






基本原理
GAN网络由一个生成器和一个判别器组成,生成器接受一个随机噪声图像并生成一个伪样本图像送入到判别器中,判别器判断该样本是真实的图像还是生成的图像,然后反复迭代修改参数,生成器试图生成更加真实的图像来骗过判别器,而判别器试图提高判别真实与生成图像的能力,二者相互对抗,最终得到可以生成最为逼真的新样本图像的生成器。
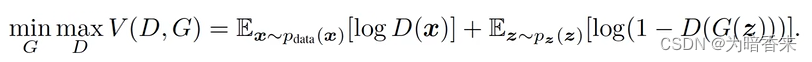
G为生成器,D为判别器,z为随机输入数据,x为训练集的数据。式中对G而言要得到V的最小值,logD(x)相当于常数,随机数据z输入生成器G中再输入到判别器D,要让V最小,也就要让log(1-D(G(z)))最小,即D(G(z))最大,相当于随机数据通过生成器后生成的数据要让判别器识别为真。对D而言要让V最大,即log(D(x))和log(1-D(G(z)))最大,相当于判别器能够将训练集的数据判别为真,生成器输出数据判别为假。
使用MNIST数据集训练GAN网络,生成手写数字的图像
导入库
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as v2
from torch.utils.data import DataLoader
import numpy as np
1. 初始化
图像维度为[1, 28, 28],即通道为1,W和H分别为28
batch_size为64,epoch为200
latent_dim是生成器输入的随机噪声向量的维度
image_size = [1, 28, 28] # 图像维度
batch_size = 64
num_epoch = 200
latent_dim = 96
use_gpu = torch.cuda.is_available()
2. 生成器类(输入随机数据z,输出图片image)
- 使用全连接层(Linear层)将输入的潜在向量维度逐步扩充到1024,每一步后跟BatchNorm,批量归一化有助于加速收敛,并且可以提供一定程度的正则化效果。还有GELU()高斯误差线性单元,是一种非线性激活函数,用于在网络中引入非线性特性。
- 最后再映射回图像维度1×28×28,之后使用Sigmoid激活函数,将输出值压缩到(0, 1)区间内。
class Generator(nn.Module): # 输入随机数据z,输出图片image
def __init__(self):
super(Generator, self).__init__() # 继承父类Module
self.model = nn.Sequential( # 线性堆栈,可以添加多个层
nn.Linear(latent_dim, 128),
torch.nn.BatchNorm1d(128), # batchnorm可以提高收敛速度
torch.nn.GELU(),
nn.Linear(128, 256),
torch.nn.BatchNorm1d(256),
torch.nn.GELU(),
nn.Linear(256, 512),
torch.nn.BatchNorm1d(512),
torch.nn.GELU(),
nn.Linear(512, 1024),
torch.nn.BatchNorm1d(1024),
torch.nn.GELU(),
nn.Linear(1024, np.prod(image_size, dtype=np.int32)), # 映射到图像维度1*28*28
nn.Sigmoid(),
)
def forward(self, z): # shape of z: [batch_size,latent_dim]
output = self.model(z)
image = output.reshape(z.shape[0], *image_size) # *image_size表示以元组形式输入
return image
3. 判别器类(输入图片,输出概率)
- 维度从图像维度1×28×28逐步降低最后到1,每步与生成器类相比没有批量归一化。
class Discriminator(nn.Module): # 输入图片,输出概率
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(np.prod(image_size, dtype=np.int32), 512),
torch.nn.GELU(),
nn.Linear(512, 256),
torch.nn.GELU(),
nn.Linear(256, 128),
torch.nn.GELU(),
nn.Linear(128, 64),
torch.nn.GELU(),
nn.Linear(64, 32),
torch.nn.GELU(),
nn.Linear(32, 1),
nn.Sigmoid(),
)
def forward(self, image): # shape of image: [batch_size, C, W, H]
prob = self.model(image.reshape(image.shape[0], -1)) # 转化为2维,与z一致
return prob
4. 训练
- 下载数据集mnist,调整大小并转为tensor格式。
- 构造dataloader,shuffle表示是否打乱数据集顺序,drop_last=True最后一个不完整的批次将被丢弃
datasets = torchvision.datasets.MNIST('mnist_data', train=True, download=True,
transform=v2.Compose([v2.Resize(28), v2.ToTensor(),
v2.Normalize(mean=[0.5], std=[0.5])]))
print(len(datasets))
dataloader = DataLoader(datasets, batch_size=batch_size, shuffle=True, drop_last=True)
- 实例化生成器和判别器
generator = Generator()
discriminator = Discriminator()
- 配置生成器与判别器的优化器
- betas=(0.4, 0.8), 一阶矩的衰减率较低,而二阶矩的衰减率较高,这可能会导致优化器对最近梯度的依赖减少,而更多地考虑过去的梯度信息
- weight_decay=0.0001, 模型将应用一个相对温和的L2正则化,这有助于防止过拟合,同时不会对权重更新产生太大的影响。
g_optimizer = torch.optim.Adam(generator.parameters(), lr=0.0003, betas=(0.4, 0.8), weight_decay=0.0001)
d_optimizer = torch.optim.Adam(discriminator.parameters(), lr=0.0003, betas=(0.4, 0.8), weight_decay=0.0001)
- Loss使用bce交叉熵
- 设置判别器标签1或0
loss_fn = nn.BCELoss()
labels_one = torch.ones(batch_size, 1)
labels_zero = torch.zeros(batch_size, 1)
- 若满足gpu,将运行的参数改为gpu模式
# gpu运算
if use_gpu:
print("use gpu for training")
generator = generator.cuda()
discriminator = discriminator.cuda()
loss_fn = loss_fn.cuda()
labels_one = labels_one.to("cuda")
labels_zero = labels_zero.to("cuda")
- 遍历每个epoch
- 遍历每个dataloader
- 生成随机噪声向量z,维度为(batch_size, latent_dim)
- 将z通过生成器生成预测图像pred_images
- 优化生成器:初始梯度置0,得到重建损失和生成器损失,反向传播更新参数
- 优化判别器:初始梯度置0,得到对原始图像损失、对预测图像损失和判别器损失,观察real_loss与fake_loss,同时下降同时达到最小值,并且差不多大,说明判别器已经稳定了,反向传播更新参数
- 每50步(即每50个小批量处理后), 打印重建损失、生成器损失、判别器损失、真实图像损失和生成图像损失
- 每400步,代码会从生成的图像中取出前16张,保存在pre_images文件下
for epoch in range(num_epoch):
for i, mini_batch in enumerate(dataloader):
gt_images, _ = mini_batch # 不要标签label
z = torch.randn(batch_size, latent_dim)
if use_gpu: # 确保gpu运算
gt_images = gt_images.to("cuda")
z = z.to("cuda")
pred_images = generator(z) # G(z)
# 优化生成器
g_optimizer.zero_grad() # 初始梯度置0
recons_loss = torch.abs(pred_images - gt_images).mean() # 重建损失
g_loss = recons_loss * 0.05 + loss_fn(discriminator(pred_images),
labels_one) # 生成器要使得生成图片被判别器判为1, 计算损失,discriminator(pred_images)表示D(G(z))
g_loss.backward() # 反向传播
g_optimizer.step() # 更新参数
# 优化判别器 判别器器要使得原始图片被判别器判为1,生成图片被判别器判为0
d_optimizer.zero_grad()
real_loss = loss_fn(discriminator(gt_images), labels_one) # 对原始图像损失
fake_loss = loss_fn(discriminator(pred_images.detach()), labels_zero) # 生成图像损失
d_loss = (real_loss + fake_loss) # 判别器损失
# 观察real_loss与fake_loss,同时下降同时达到最小值,并且差不多大,说明D已经稳定了
d_loss.backward()
d_optimizer.step()
# 每50步(即每50个小批量处理后), 打印重建损失、生成器损失、判别器损失、真实图像损失和生成图像损失
if i % 50 == 0:
print(
f"step:{len(dataloader) * epoch + i}, recons_loss:{recons_loss.item()}, g_loss:{g_loss.item()}, d_loss:{d_loss.item()}, real_loss:{real_loss.item()}, fake_loss:{fake_loss.item()}")
# 每400步,代码会从生成的图像中取出前16张
if i % 400 == 0:
image = pred_images[:16].data
torchvision.utils.save_image(image, f"pre_images/image_{len(dataloader) * epoch + i}.png", nrow=4)
结果
-
前几次的损失

-
前几次生成的手写数字图像

-
15万次左右的损失
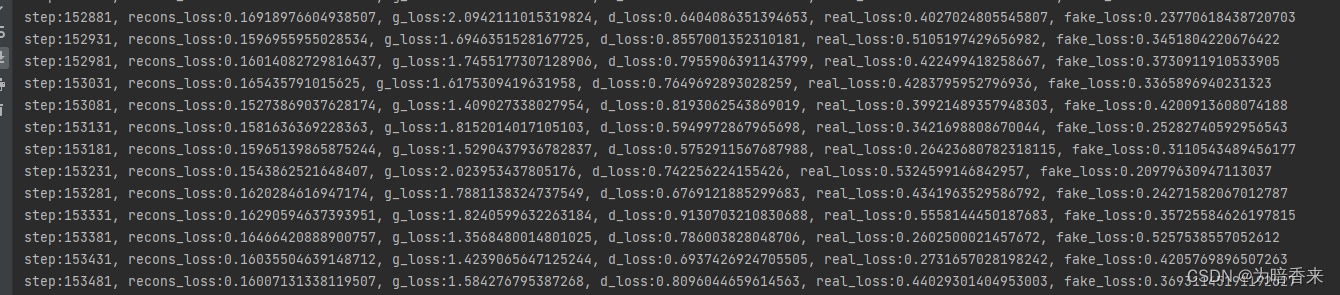
-
15万次左右的手写数字图像


















 2634
2634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









