



0 前言
🔥这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。并且很难找到完整的毕设参考学习资料。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目提供大家参考学习,今天要分享的是
🚩 毕业设计 深度学习YOLO番茄叶片病变识别系统(源码+论文)
🥇学长这里给一个题目综合评分(每项满分5分)
难度系数:3分
工作量:4分
创新点:5分
🧿 项目分享:见文末!
1 项目运行效果
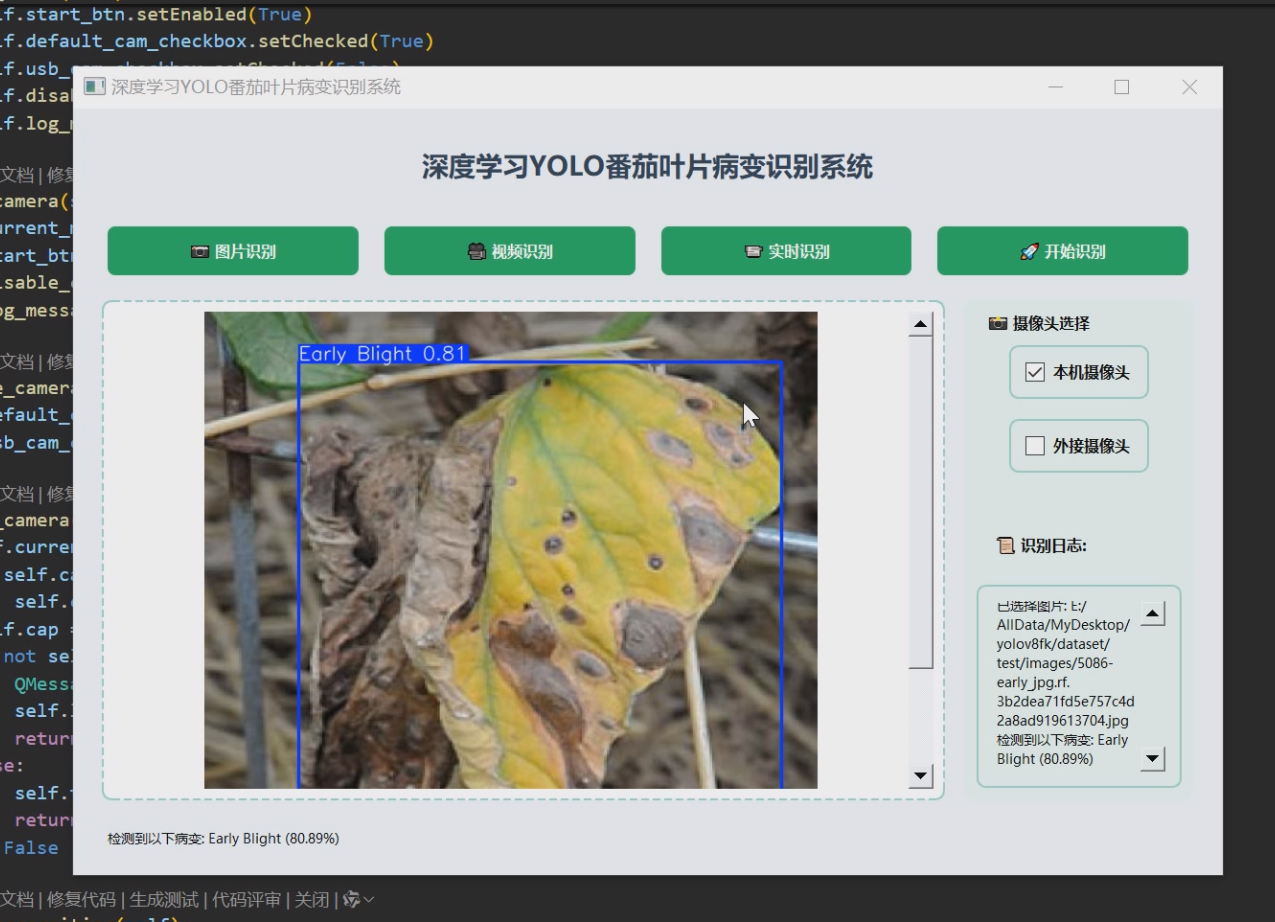
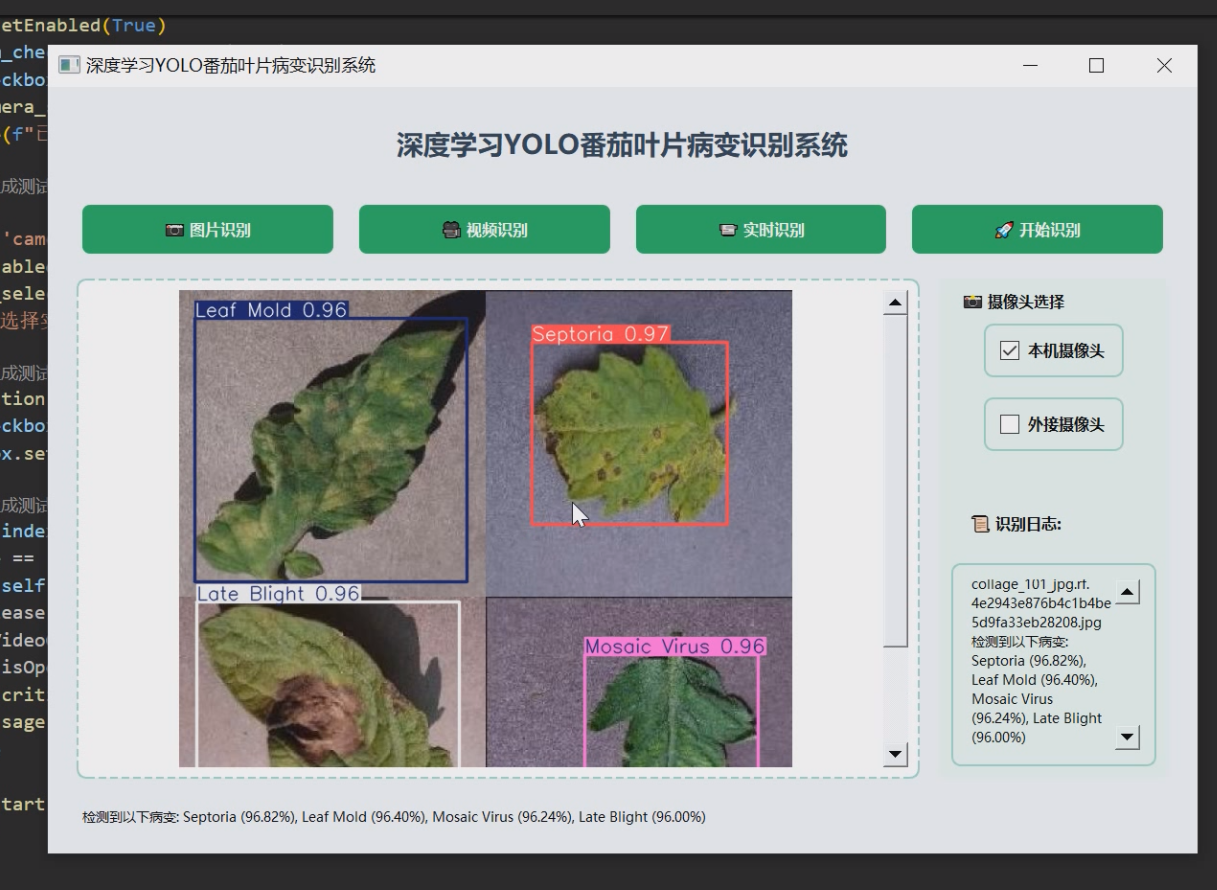
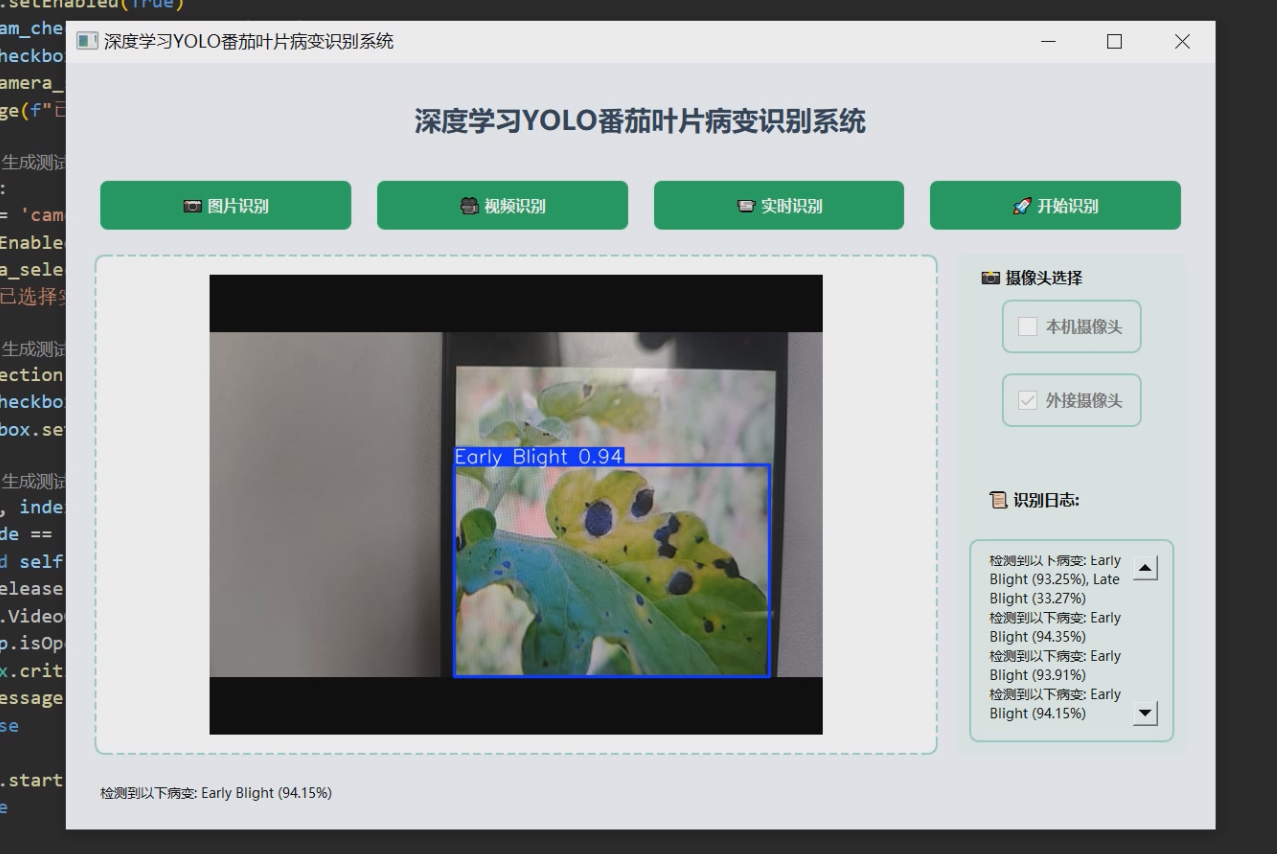

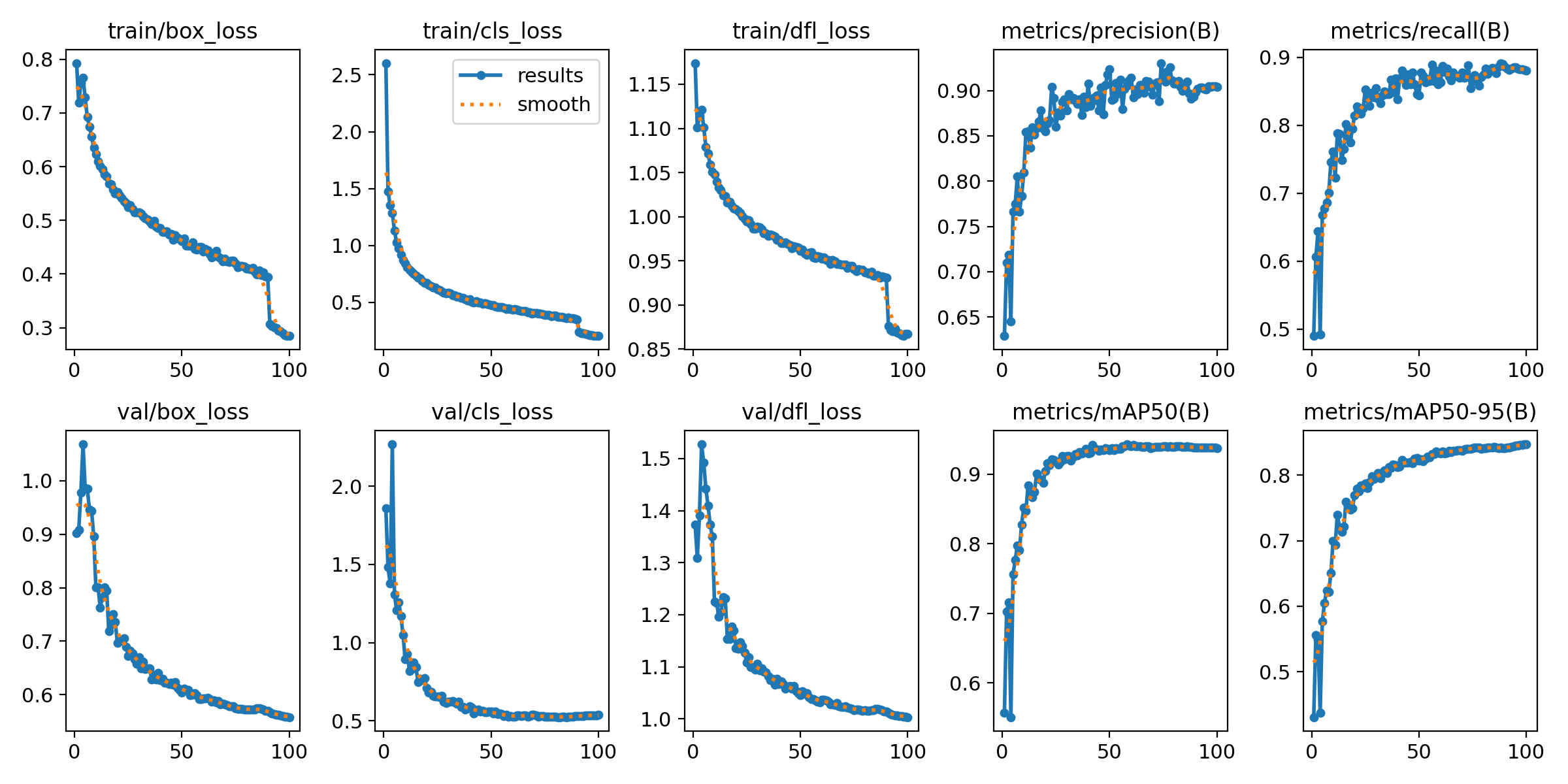
2 课题背景
2.1 农业现代化发展趋势
随着全球人口的持续增长和城市化进程的加快,农业生产面临着前所未有的挑战。据联合国粮农组织(FAO)统计,预计到2050年全球粮食需求将增加约70%。在这一背景下,传统农业模式已难以满足现代社会对农产品数量和质量的双重需求。因此,推动农业现代化、智能化发展已成为各国政府和科研机构的重点研究方向。
近年来,物联网、大数据、人工智能等新一代信息技术的快速发展,为农业转型升级提供了新的解决方案。智慧农业作为现代农业的重要组成部分,通过集成各种智能技术,实现了农业生产过程中的精准监测、智能决策和自动化控制。其中,计算机视觉技术因其非接触式、高效率、低成本等特点,在农作物生长监测、病虫害检测、产量预测等方面展现出巨大潜力。
2.2 农作物病害检测的重要性
病虫害是影响农作物产量和品质的关键因素之一。据统计,全球每年因病虫害造成的农作物损失高达数千亿美元。传统的病害检测方法主要依赖人工田间调查和实验室分析,存在以下问题:
- 效率低下:人工巡田耗时耗力,难以实现大面积农田的实时监测。
- 成本高昂:专业检测设备和实验室分析费用较高,限制了其在基层农业生产中的广泛应用。
- 主观性强:诊断结果易受技术人员经验影响,可能导致误诊或漏诊。
- 响应滞后:从发现病害到采取防治措施往往需要较长时间,容易错过最佳防治时机。
因此,开发一种快速、准确、低成本的农作物病害自动检测系统,对于提高病害防控效率、降低经济损失具有重要意义。
2.3 深度学习技术在农业领域的应用
深度学习作为人工智能的一个重要分支,近年来在图像识别、语音处理、自然语言理解等领域取得了突破性进展。特别是卷积神经网络(CNN)的发展,使得计算机视觉技术在目标检测、分类、分割等任务中表现出接近甚至超越人类的性能。
在农业领域,深度学习技术已被广泛应用于以下几个方面:
- 作物种类识别:通过训练深度学习模型,可以准确识别不同类型的农作物。
- 生长状态评估:利用多光谱成像和深度学习技术,可以评估作物的生长状况和营养水平。
- 杂草检测与除草机器人:结合无人机航拍和地面机器人,可以实现精准喷洒农药,减少环境污染。
- 病虫害检测:通过对大量病害样本进行训练,深度学习模型能够准确识别不同类型的作物病害。
研究表明,使用深度学习技术进行农作物病害检测相比传统方法具有显著优势:
- 准确性高:经过充分训练的模型可以达到90%以上的识别准确率。
- 速度快:单张图像的处理时间通常在几十毫秒以内,适合实时检测。
- 适应性强:通过数据增强和迁移学习,模型可以快速适应新环境或新病害类型。
- 成本低:基于普通摄像头的采集设备即可满足基本需求,降低了硬件投入。
2.4 YOLO系列算法的发展与应用
目标检测是计算机视觉领域的核心任务之一,旨在同时完成图像中物体的定位和分类。YOLO(You Only Look Once)系列算法是由Joseph Redmon等人提出的一种单阶段目标检测框架,以其出色的检测速度和精度而闻名。
2.4.1 YOLO算法演进
YOLO系列算法自2016年首次发布以来,经历了多次重大改进:
- YOLOv1:首次提出了将目标检测问题转化为单次推理的思想,大大提高了检测速度。
- YOLOv2/YOLO9000:引入了Anchor机制、多尺度预测等技术,提升了小目标检测能力。
- YOLOv3:采用FPN结构进行特征融合,增强了多尺度目标检测效果。
- YOLOv4:由Alexey Bochkovskiy团队开发,引入了CSPDarknet53主干网络和PANet特征金字塔,进一步提升了性能。
- YOLOv5/6/7:Ultralytics公司推出的改进版本,优化了模型结构和训练流程,支持更灵活的部署方式。
- YOLOv8:最新一代YOLO算法,集成了最新的研究成果,提供了更高的精度和更快的推理速度。
2.4.2 YOLOv8的技术特点
YOLOv8在继承前代优点的基础上,进行了多项创新性改进:
- 改进的骨干网络:采用更高效的特征提取结构,提升模型表达能力。
- 动态标签分配:根据训练过程中的表现动态调整正负样本权重,提高收敛速度。
- 无锚框检测头:摒弃传统Anchor机制,直接预测边界框坐标,简化模型结构。
- 增强的数据增强策略:引入Mosaic、MixUp等高级数据增强技术,提升模型泛化能力。
- 支持多种部署平台:提供ONNX、TensorRT、CoreML等多种导出格式,便于跨平台应用。
2.5 番茄叶片病变识别的研究现状
番茄作为全球最重要的蔬菜作物之一,其产量和品质直接影响着农业生产效益。然而,番茄生长过程中极易受到多种病害侵袭,如早疫病、晚疫病、叶霉病、灰斑病等。这些病害不仅会导致叶片枯黄脱落,还可能影响果实发育,造成严重减产。
目前,国内外已有不少学者开展了基于深度学习的番茄病害检测研究:
- 国外研究:美国加州大学戴维斯分校的研究人员开发了一种基于CNN的番茄病害识别系统,在包含10种常见病害的数据集上达到了93.2%的准确率。
- 国内研究:中国农业大学团队构建了一个涵盖30余种番茄病害的大规模数据集,并采用迁移学习方法训练出高性能检测模型。
- 商业应用:日本SoftBank公司推出了搭载AI芯片的农业无人机,可实时识别作物病害并指导精准施药。
尽管已有诸多研究成果,但在实际应用中仍面临一些挑战:
- 数据获取难度大:高质量标注的农业病害图像数据相对稀缺。
- 环境复杂多变:野外光照条件、天气状况等因素会影响图像质量。
- 模型轻量化需求:农业应用场景往往要求在边缘设备上运行,对模型计算资源有严格限制。
- 用户友好性不足:现有系统大多侧重于算法性能,缺乏直观易用的交互界面。
2.6 本课题的研究动机
针对上述挑战,本课题拟开发一套基于YOLOv8和Python的番茄叶片病变识别系统。该系统将重点解决以下问题:
- 易用性:通过PyQt5开发图形用户界面,使非专业用户也能轻松操作。
- 实用性:支持图片、视频和实时摄像头三种输入方式,满足不同场景需求。
- 高效性:充分利用YOLOv8的高速检测能力,确保系统响应迅速。
- 可扩展性:设计模块化架构,便于后续添加新的病害类别或功能模块。
通过本课题的研究,期望能够为农业生产者提供一个实用、高效的病害检测工具,助力智慧农业发展,推动农业现代化进程。
3 设计框架
3.1. 系统整体架构
本系统采用分层架构设计,主要包括以下四个层次:
+----------------------------+
| 用户交互层 |
| (PyQt5图形用户界面) |
+-----------+----------------+
|
+-----------v----------------+
| 控制逻辑层 |
| (Python业务逻辑处理) |
+-----------+----------------+
|
+-----------v----------------+
| 模型推理层 |
| (YOLOv8目标检测模型) |
+-----------+----------------+
|
+-----------v----------------+
| 数据资源层 |
| (图像/视频/摄像头数据) |
+----------------------------+
技术选型说明:
- 编程语言:Python 3.8+
- 深度学习框架:YOLOv8(基于Ultralytics实现)
- 图形界面库:PyQt5
- 配置文件格式:YAML
- 开发环境:Windows 10/11
3.2. 核心技术组件与集成
3.2.1 YOLOv8目标检测模块
这是系统的核心功能模块,负责执行番茄叶片病变的识别任务。使用预训练的YOLOv8模型进行迁移学习,在自定义数据集上进行微调。
# YOLOv8模型初始化示例
from ultralytics import YOLO
# 加载预训练模型
model = YOLO('yolov8s.pt') # 可替换为'yolov8m.pt'等其他版本
# 自定义数据集训练
results = model.train(data='Mydata.yaml', epochs=100, imgsz=640)
# 执行预测
results = model.predict(source='test_image.jpg', conf=0.25)
3.2.2 PyQt5图形用户界面模块
该模块负责构建用户交互界面,包含主窗口、按钮控件、图像显示区域、日志输出框等元素。采用信号-槽机制实现界面元素与业务逻辑的交互。
# PyQt5界面初始化示例
from PyQt5.QtWidgets import *
from PyQt5.QtCore import *
from PyQt5.QtGui import *
class TomatoLeafDetectionApp(QWidget):
def __init__(self):
super().__init__()
self.setWindowTitle("深度学习YOLO番茄叶片病变识别系统")
self.setGeometry(100, 100, 1200, 800)
# 初始化UI组件
self.init_ui()
# 加载模型
self.model = YOLO('best.pt')
3.2.3 数据处理模块
该模块负责管理输入数据源,包括本地图片文件、视频文件和实时摄像头流。不同数据源采用统一接口进行抽象,便于在不同模式间切换。
# 不同数据源处理示例
import cv2
def process_image(self, file_path):
# 图像处理逻辑
image = cv2.imread(file_path)
results = self.model(image)
annotated_frame = results[0].plot()
def process_video(self, file_path):
# 视频处理逻辑
self.video_cap = cv2.VideoCapture(file_path)
self.timer = QTimer()
self.timer.timeout.connect(self.process_video_frame)
self.timer.start(30) # 每30毫秒处理一帧
def start_camera(self, index):
# 摄像头处理逻辑
self.cap = cv2.VideoCapture(index)
self.timer = QTimer()
self.timer.timeout.connect(self.update_frame)
self.timer.start(30)
3.3. 系统工作流程
3.3.1 整体流程图
[开始] --> [加载YOLOv8模型]
--> [初始化PyQt5界面]
--> [等待用户操作]
--> [判断操作类型]
--> [图片识别/视频识别/摄像头识别]
--> [执行相应处理]
--> [显示检测结果]
--> [记录识别日志]
--> [是否继续?]
--> 是 --> [继续等待用户操作]
--> 否 --> [释放资源] --> [结束]
3.3.2 核心交互流程
- 模型加载阶段:程序启动时加载预先训练好的YOLOv8模型
- 界面初始化阶段:构建PyQt5界面元素,设置QSS样式
- 用户操作阶段:响应用户选择的数据源类型(图片/视频/摄像头)
- 数据处理阶段:根据选择的数据源类型执行相应的处理流程
- 结果显示阶段:将检测结果可视化,并更新到界面上
- 日志记录阶段:将检测信息记录到日志文本框中
- 循环执行阶段:持续响应用户操作直到程序关闭
3.4. UI交互系统设计
3.4.1 界面布局设计
+-------------------------------------------------------------+
| 深度学习YOLO番茄叶片病变识别系统 |
|-------------------------------------------------------------|
| 图片识别 | 视频识别 | 实时识别 | 开始识别 |
|-------------------------------------------------------------|
| |
| 识别结果显示区域 |
| |
|-------------------------------------------------------------|
| 摄像头选择 | |
| ------------------------------ | |
| ☑ 本机摄像头 (索引 0) | |
| ☐ 外接摄像头 (索引 1) | 识别日志: |
| | ┌─────────────────────┐ |
| | │ │ |
| | │ │ |
| | │ 识别日志信息 │ |
| | │ │ |
| | └─────────────────────┘ |
|-------------------------------------------------------------|
| 状态栏:就绪 |
+-------------------------------------------------------------+
3.4.2 交互逻辑设计
主要交互事件流:
-
按钮点击事件:
- 图片识别按钮:打开文件对话框选择图片
- 视频识别按钮:打开文件对话框选择视频
- 实时识别按钮:准备摄像头捕获
- 开始识别按钮:触发对应的数据处理流程
-
复选框状态变化事件:
self.default_cam_checkbox.stateChanged.connect(lambda: self.change_camera(0)) self.usb_cam_checkbox.stateChanged.connect(lambda: self.change_camera(1)) -
定时器事件:
- 用于驱动视频帧和摄像头帧的连续处理
- 定时间隔设置为30毫秒以平衡性能和流畅度
self.timer = QTimer() self.timer.timeout.connect(self.update_frame) self.timer.start(30) -
日志记录事件:
- 每次检测完成后自动将结果追加到日志文本框
def log_message(self, message): self.log_text.append(message) self.statusBar.showMessage(message)
3.4.3 图表显示逻辑
图像显示实现:
- 对于OpenCV图像:需要先将BGR格式转换为RGB格式再显示
def show_video_frame(self, frame):
# 将OpenCV BGR格式转换为RGB
rgb_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
h, w, ch = rgb_frame.shape
bytes_per_line = ch * w
# 创建QImage并显示
q_img = QImage(rgb_frame.data, w, h, bytes_per_line, QImage.Format_RGB888)
pixmap = QPixmap.fromImage(q_img)
scene = QGraphicsScene()
pixmap_item = QGraphicsPixmapItem(pixmap)
scene.addItem(pixmap_item)
self.graphics_scene = scene
self.graphics_view.setScene(self.graphics_scene)
- 对于本地图片文件:直接使用QPixmap加载显示
def show_image(self, file_path):
scene = QGraphicsScene()
pixmap = QPixmap(file_path)
if not pixmap.isNull():
pixmap_item = QGraphicsPixmapItem(pixmap)
scene.addItem(pixmap_item)
self.graphics_scene = scene
self.graphics_view.setScene(self.graphics_scene)
检测结果叠加逻辑:
利用YOLOv8内置的绘图函数,将检测框和类别信息叠加到原始图像上:
def process_image(self):
# 获取当前显示的图片
items = self.graphics_scene.items()
if items and isinstance(items[0], QGraphicsPixmapItem):
pixmap = items[0].pixmap()
if not pixmap.isNull():
# 将QPixmap转换为OpenCV格式
image = pixmap.toImage()
image = image.convertToFormat(QImage.Format.Format_RGB888)
ptr = image.bits()
ptr.setsize(image.byteCount())
import numpy as np
arr = np.array(ptr).reshape(image.height(), image.width(), 3)
cv_image = cv2.cvtColor(arr, cv2.COLOR_RGB2BGR)
# 进行预测
results = self.model(cv_image)
# 显示带检测结果的图像
annotated_frame = results[0].plot()
self.show_video_frame(annotated_frame)
# 记录检测结果
self.log_detection_results(results[0])
3.5. 系统特点总结
本系统通过合理的技术选型和架构设计,实现了以下关键特性:
-
高效的深度学习推理:
- 使用优化后的YOLOv8模型,保证了检测速度和精度的平衡
- 支持多种模型大小选择(从yolov8s到yolov8x)
-
友好的用户交互体验:
- 清晰直观的界面布局
- 多种输入方式支持(图片/视频/摄像头)
- 实时更新的检测结果展示
- 详细的识别日志记录
-
良好的可扩展性:
- 模块化的设计便于后续功能扩展
- 可轻松添加新的病害类别或改进检测算法
-
跨平台兼容性:
- 基于Python和PyQt5开发,可在不同操作系统上运行
该设计充分体现了深度学习技术与图形用户界面开发的有机结合,为农业领域的智能病害检测提供了一个实用的解决方案。
4 最后
项目包含内容

论文摘要

🧿 项目分享:大家可自取用于参考学习,获取方式见文末!


















 482
482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









