



0 前言
🔥这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。并且很难找到完整的毕设参考学习资料。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目提供大家参考学习,今天要分享的是
🚩 毕业设计 深度学习yolo11垃圾分类系统(源码+论文)
🥇学长这里给一个题目综合评分(每项满分5分)
难度系数:3分
工作量:4分
创新点:5分
🧿 项目分享:见文末!
1 项目运行效果
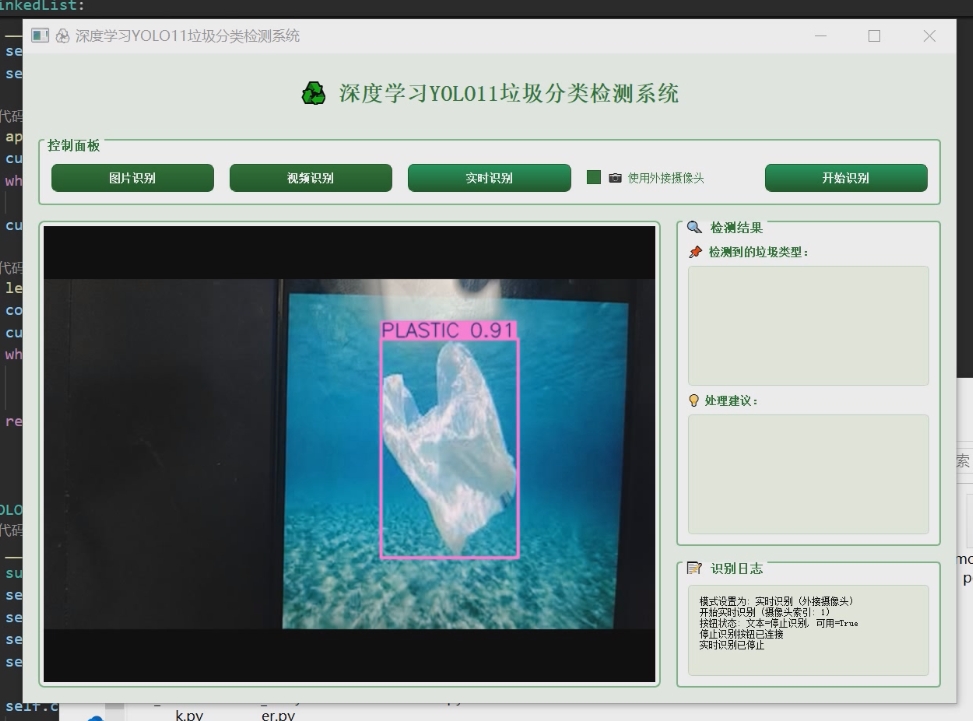
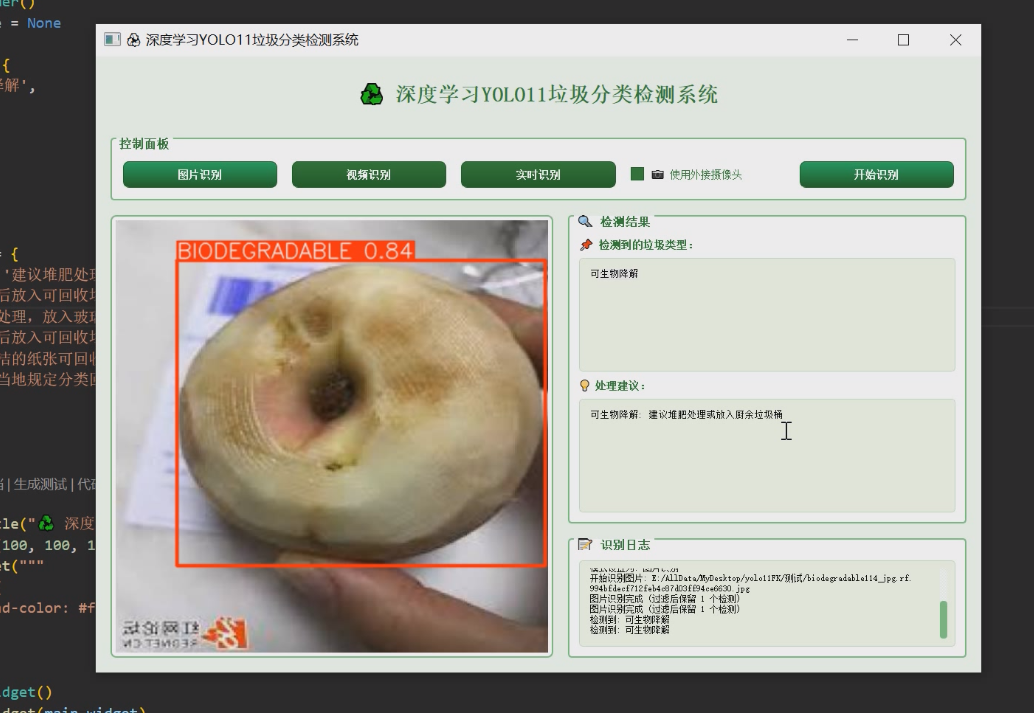
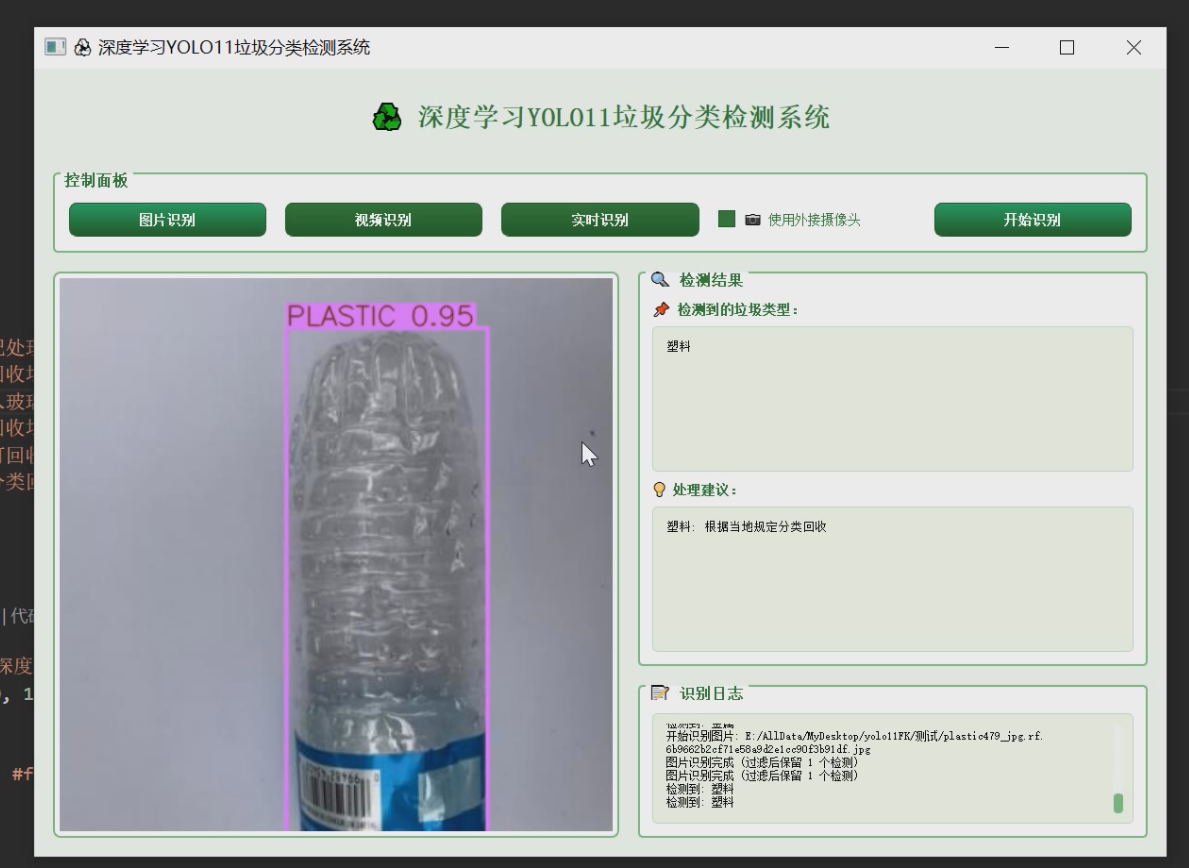
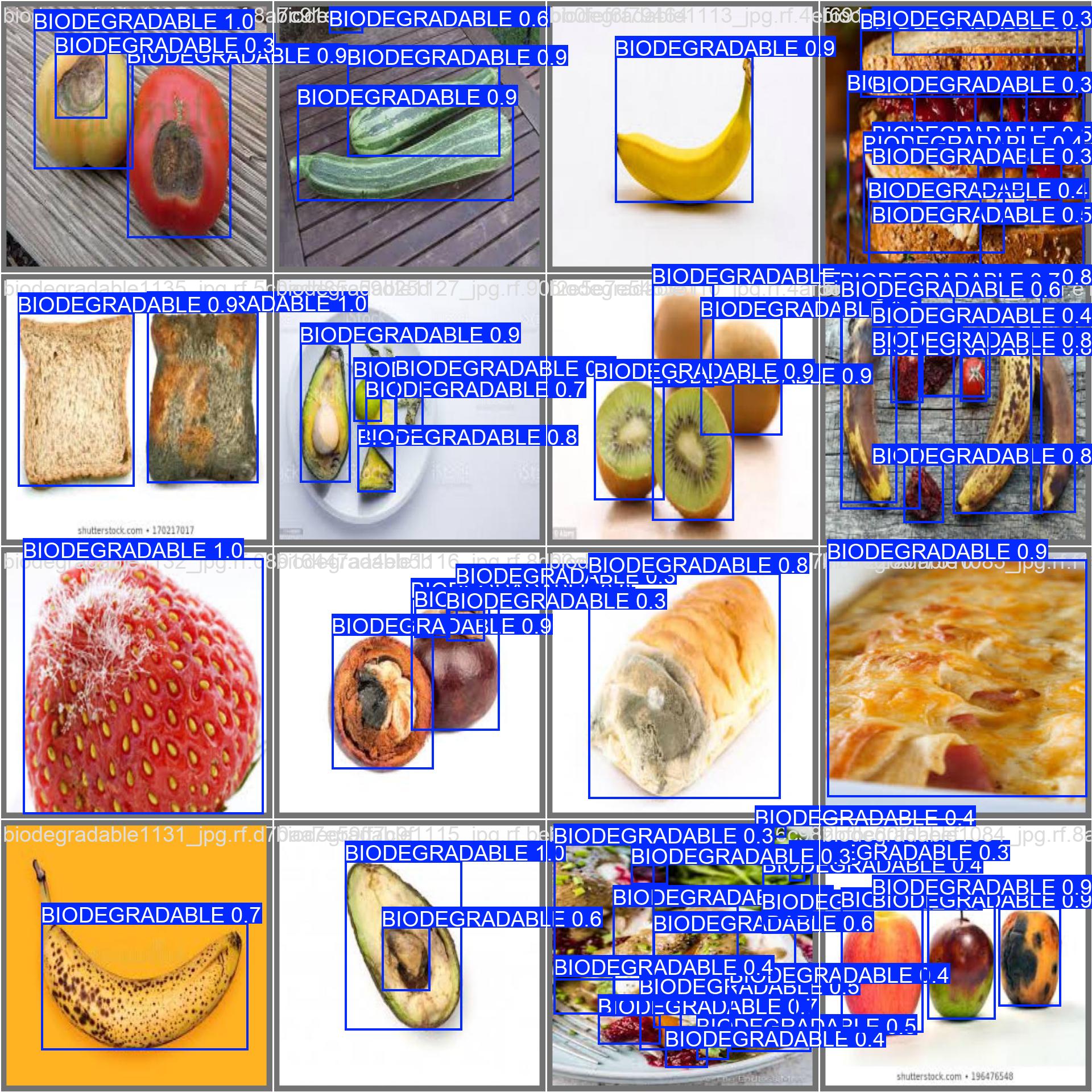

2 课题背景
2.1. 研究背景
随着全球城市化进程加速和人口持续增长,生活垃圾产量呈现爆发式增长态势。据统计数据显示,中国每年产生近3亿吨城市生活垃圾,且以每年8%-10%的速度递增。传统的人工分类方式不仅效率低下,而且分类准确率难以保证,已无法满足现代城市垃圾处理需求。
2019年,中国开始在全国46个重点城市率先推行生活垃圾强制分类政策,标志着我国垃圾分类进入法制化、规范化新阶段。2021年,《"十四五"城镇生活垃圾分类和处理设施发展规划》明确提出要加快推进垃圾分类处理设施建设,提升分类处理能力。在此政策背景下,开发智能化、自动化的垃圾分类技术成为解决当前垃圾分类困境的重要突破口。
2.2. 技术发展现状
计算机视觉技术在物体检测领域取得了突破性进展,特别是以YOLO(You Only Look Once)系列为代表的单阶段目标检测算法,因其检测速度快、准确率高而备受关注。YOLOv11作为该系列的最新版本,在保持实时性的同时,通过改进网络结构和训练策略,显著提升了小目标检测性能。
在垃圾分类领域,已有研究尝试应用深度学习技术。早期方法主要基于传统机器学习算法如SVM、随机森林等,准确率普遍低于80%。近年来,基于CNN的方法逐渐成为主流,如清华大学开发的基于Faster R-CNN的系统在特定数据集上达到了89%的准确率。然而,这些系统普遍存在计算资源消耗大、实时性差等问题,难以满足实际应用需求。
2.3. 现有技术存在的问题
通过对现有垃圾分类技术的分析,发现存在以下主要问题:
3.1 检测精度不足
现有系统对相似类别垃圾(如不同塑料制品)的区分能力有限,容易产生误判。特别是在复杂背景下,检测准确率会显著下降。
3.2 实时性差
多数基于两阶段检测算法的系统处理速度慢,无法满足实时检测需求。例如Faster R-CNN在普通GPU上仅能达到10-15FPS。
3.3 适应性不强
现有系统对光照变化、遮挡等现实场景中的干扰因素鲁棒性不足,且难以适应不同地区的分类标准差异。
3.4 用户体验不佳
缺乏友好的交互界面,普通用户难以操作和维护,限制了技术的推广应用。
2.4. 研究意义
本课题的研究具有重要的理论价值和实践意义:
4.1 理论价值
- 探索改进YOLOv11算法在垃圾分类场景中的应用潜力
- 研究多尺度特征融合在小目标检测中的优化方法
- 开发适用于动态场景的鲁棒性目标检测系统
4.2 实践意义
- 提高垃圾分类效率和准确率,降低人工成本
- 推动计算机视觉技术在实际工程中的应用
- 为智慧城市建设提供技术支持
- 促进居民环保意识提升和习惯养成
4.3 社会效益
- 助力国家垃圾分类政策实施
- 减少资源浪费和环境污染
- 推动循环经济发展
2.5. 项目创新点
本课题的创新性主要体现在以下几个方面:
5.1 算法创新
- 改进YOLOv11的损失函数,优化小目标检测性能
- 设计动态NMS阈值调整策略,提高密集目标检测准确率
- 引入注意力机制增强特征表达能力
5.2 系统创新
- 开发支持图片、视频和实时检测的多模式系统
- 实现基于PyQt5的跨平台图形界面
- 集成垃圾分类知识库和处置建议
5.3 应用创新
- 适应不同地区的分类标准差异
- 支持外接摄像头和本地视频处理
- 提供详细的检测日志和统计功能
2.6. 技术路线
本项目将采用以下技术路线:
- 数据采集与标注:构建包含6大类垃圾的图像数据集
- 模型训练:基于YOLOv11框架进行迁移学习和优化
- 系统开发:使用PyQt5实现跨平台图形界面
- 性能优化:引入TensorRT加速推理过程
- 测试部署:在多种硬件平台上验证系统性能
3 设计框架
3.1. 技术选型与框架
3.1.1 核心技术栈
- 目标检测:YOLOv11算法
- 图形界面:PyQt5框架
- 图像处理:OpenCV库
- 并行计算:CUDA加速
3.1.2 开发环境
3.2. 系统架构设计
3.2.1 整体架构
3.2.2 模块划分
- 图像采集模块:负责图片/视频/摄像头输入
- 模型推理模块:YOLOv11目标检测核心
- 结果显示模块:检测结果可视化
- 交互控制模块:系统状态管理
3.3. 核心模块实现
3.3.1 主程序结构
class YOLOApp(QMainWindow):
def __init__(self):
# 初始化模型和UI
self.model = YOLO("best.pt")
self.initUI()
def initUI(self):
# 创建主窗口和控件
self.create_widgets()
self.setup_layout()
self.connect_signals()
3.3.2 检测流程控制
3.4. 关键算法说明
3.4.1 YOLOv11改进点
# 伪代码:改进的损失函数
def compute_loss(pred, target):
# 分类损失
cls_loss = FocalLoss(pred_class, target_class)
# 定位损失
box_loss = CIoULoss(pred_box, target_box)
# 对象损失
obj_loss = BCEWithLogitsLoss(pred_obj, target_obj)
return cls_loss + box_loss + obj_loss
3.4.2 非极大值抑制优化
3.5. 交互系统设计
3.5.1 界面布局
主窗口布局:
┌───────────────────────┬─────────────────┐
│ │ │
│ │ 检测结果区域 │
│ 图像显示区域 ├─────────────────┤
│ │ 处理建议区域 │
│ │ │
├───────────────────────┼─────────────────┤
│ │ │
│ 控制面板区域 │ 日志输出区 │
│ │ │
└───────────────────────┴─────────────────┘
3.5.2 状态管理
# 伪代码:模式切换逻辑
def set_mode(mode):
self.current_mode = mode
self.update_button_states()
if mode == "realtime":
self.init_camera()
elif mode == "video":
self.open_video_file()
3.6. 数据处理流程
3.6.1 数据集构建
3.6.2 训练流程
# 伪代码:模型训练
def train_model():
# 1. 加载预训练权重
model = YOLO("yolov11s.pt")
# 2. 设置训练参数
cfg = {
'epochs': 100,
'batch': 16,
'imgsz': 640,
'data': 'trash.yaml'
}
# 3. 开始训练
results = model.train(**cfg)
3.7. 图表显示逻辑
3.7.1 图像显示流程
3.7.2 结果显示代码
def display_image(self, image):
# OpenCV转QImage
h, w, ch = image.shape
bytes_per_line = ch * w
q_img = QImage(image.data, w, h, bytes_per_line, QImage.Format_RGB888)
# 缩放保持比例
pixmap = QPixmap.fromImage(q_img).scaled(
800, 600, Qt.KeepAspectRatio, Qt.SmoothTransformation)
# 更新显示
self.image_label.setPixmap(pixmap)
4 最后
项目包含内容

论文摘要

🧿 项目分享:大家可自取用于参考学习,获取方式见文末!


















 1847
1847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









