







前不久,Flink社区发布了FLink 1.9版本,在其中包含了一个很重要的新特性,即state processor api,这个框架支持对checkpoint和savepoint进行操作,包括读取、变更、写入等等。
savepoint的可操作带来了很多的可能性:
- 作业迁移
1.跨类型作业,假如有一个storm作业,将状态缓存在外部系统,希望更好的利用flink的状态机制来增加作业的稳定和减少数据的延迟,但如果直接迁移,必然面临状态的丢失,这时,可以将外部系统的状态转换为flink作业的savepoint来启动。
2.同类型作业,假如有一个flink作业已经在运行,一个新的flink作业希望复用之前的某些状态,也可以将savepoint进行处理重新写入,进而使得新的flink作业可以在某个基础上运行。
- 作业升级
1.有UID升级,一般情况下,如果升级前的operator已经设置了uid,那么可以直接升级,但是如果希望在之前的状态数据上做些变更,这里就提供了一种接口。
2.无UID升级,在特殊情况下,一开始编写了没有UID的作业,后来改成了标准的有UID的作业,反而无法在之前的savepoint上启动了,这时也可以对savepoint同时做升级。
- 作业校验
1.异步校验,一般而言,flink作业的最终结果都会持久化输出,但在面临问题的时候,如何确定哪一级出现问题,state processor api也提供了一种可能,去检验state中的数据是否与预期的一致。
- 作业扩展
1.横向扩展,如果在flink作业一开始运行的时候,因为面对的数据量较小,设置了比较小的最大并行度,但在数据量增大的时候,却没办法从老的savepoint以一个比之前的最大并行度更大的并行度来启动作业,这时,也需要复写savepoint的同时更改最大并行度。
2.纵向扩展,在flink作业中新添加了一个operator,从savepoint启动的时候这个operator默认无状态,可以手动构造数据,使得这个operator的表现和其他operator保持一致。
可以对savepoint进行哪些操作?
- 读取savepoint
1.验证,读取出来的savepoint会转换为一个dataSet,随后可以以标准批处理的方式来验证你的业务预期;
2.source,也可以以savepoint作为数据源,来作为你另一个作业的输入。
- 写入savepoint
1.写入新的savepoint,可以写入一个全新的savepoint,这个savepoint是独立的存在,他可以有新的operator uid,新的operator state,以及新的max parallism等等。
2.复用原来的savepoint,可以在原来的savepoint的基础上加入新的operator的state,在新的savepoint被使用之前,老的savepoint不允许被删除。
那么究竟哪些state是可读的?有哪些接口了?
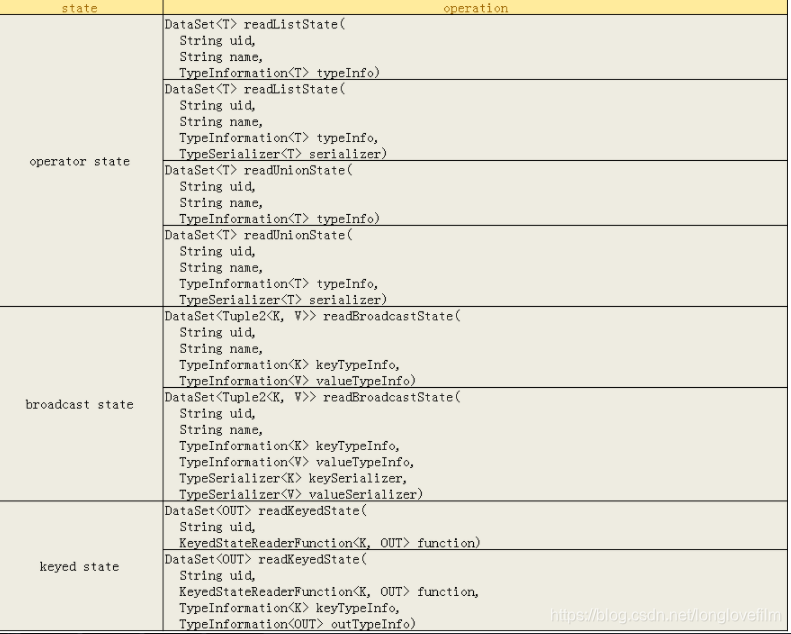
可以看到,主要提供对三种state的访问,operator state和broadcast state,其中broadcast state是一种特殊的operator state,因为他也支持自定义的serializer。
通关程序
目前在社区或者网上并没有完整的样例供大家参考,下面这个例子是完全在测试环境中跑通的,所有的flink相关组件的版本依赖都是1.9.0。
下面我们说明如何使用这个框架。
1.首先我们创建一个样例作业来生成savepoint
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(60*1000);
DataStream<Tuple2<Integer,Integer>> kafkaDataStream =
env.addSource(new SourceFunction<Tuple2<Integer,Integer>>() {
private boolean running = true;
private int key;
private int value;
pri 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 33万+
33万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









