



题目、作者:
Enhanced Coherence-Aware Network with Hierarchical Disentanglement for Aspect-Category Sentiment Analysis

Abstract
1. motivation:一句评论通常包括多个不同的方面类别,其中一些并没有明确地出现在评论中(隐性方面词)。即使在一个句子中,包含情感的方面类别也不止一个,而且它们在句子内是纠缠在一起的,这使得模型无法区分地保留所有的情感特征(情感纠缠)。【Introduction会详细介绍】
2. 本文方法介绍:本文提出一个“具有层次解纠缠的增强连贯性感知网络”(ECAN)。具体来说,本文方法探索了连贯性建模来捕捉整个评论的上下文,帮助隐式方面词的识别和情感的识别。为了解决多方面类别和情感纠缠问题,本文提出一个层级解纠纷模型来提取不同方面类别和情感特征
1. Introduction
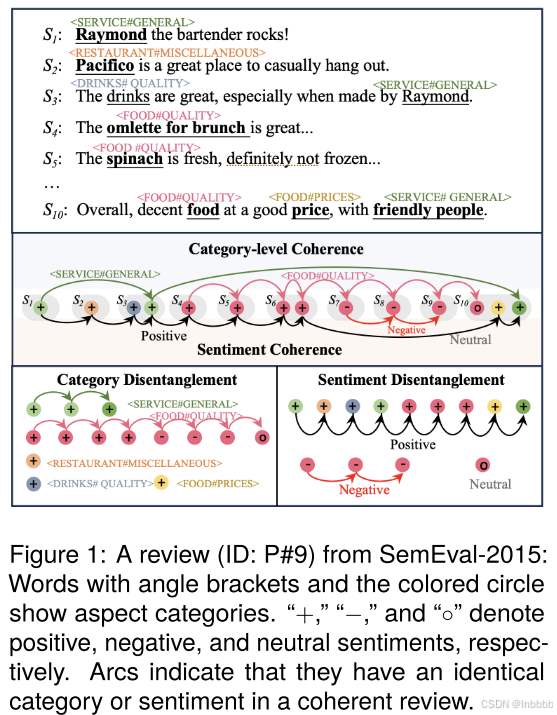
这是本文给出的例子,这个例子来自REST15数据集(一个评价餐厅的数据集)。其中相同颜色表示他们在连贯的评论中有相同的类别或者情感极性;“#”的作用是分割粗粒度和细粒度的方面类别,一般ACSA任务都是大类别中有小类别,比如<食物#价格>,表示对“食物的价格”做情感预测。
1. ACSA介绍:ACSA=ACD+ACSC,即方面类别情感分析由方面类别检测ACD以及方面类别情感分类ACSC组成。给定一个句子,ACSA的任务是先对这句话的方面类别进行检测,然后预测该方面类别对应的情感极性
2. 阻碍ACSA任务SOTA的两个问题:
(对应摘要部分的motivation)
① 隐性方面词:一个评论通常包含多个不同的方面类别,其中一些没有明确出现在评论中。
例如,图1中的S1和S2中的“SERVICE”和“RESTAURANT”并没有出现在文本中;另外,对于S3中的“Raymond”,如果只看S3不看其他的文本,我们可能认为这是一个酒保的名字,我们无法只通过S3这句话看出来“Raymond”与方面类别“SERVICE”相关;最后,S1、S3中的“Raymond”和S10中的“friendly people”方面类别都是“SERVICE”,而之前的工作无法捕捉到句子是如何连接的,或者整个评论是如何组织起来向读者传达信息的
② 情感纠缠:一个句子中存在多个方面类别及其情感,并且它们相互纠缠,导致普通的情感级token无法区别的保留情感特征(个人理解:可能分为两种情况,一种是图中的示例S10,即对于同一个方面类别可能有两个不同情感的意见词;另一种就是一句话有多个方面类别,且句法、语义较复杂,导致模型错误的将属于其他方面类别的意见词作为预测当前方面类别情感极性的意见词)
例如,图1中的S10,对于方面类别food,意见词“decent”对于food是中性的,而“good price”对于food又是积极的,因此可能导致food错误的被预测为是积极的。
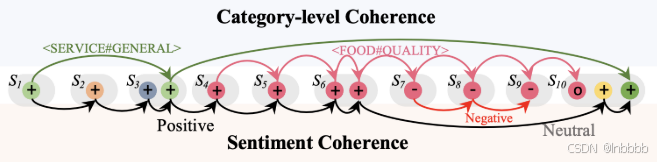
另外,下图为类别层面的连贯性,可以看到不同方面类别在句间也是存在关联的,这表明方面类别及其对应的情感在句内和句间都是纠缠在一起的(有关联的)
3. 本文方法介绍:
本文提出一种具有层级解纠缠的增强连贯感知网络(ECAN)。
① 一致性建模 → 捕获整个评论的上下文、使模型能够从上下文中学习显式意见,以帮助内隐方面和情感识别
② 分层解纠缠模块 → 提取不同的类别和情感特征(为了解决方面类别和情感纠缠的问题)
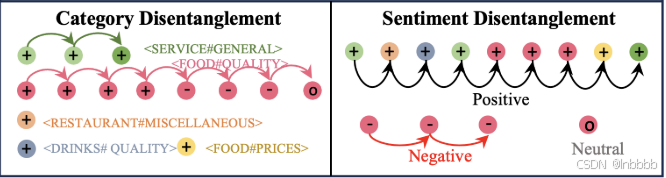
如下图,本文利用连贯性特征,根据情感极性对方面类别表示(左子图)和表示情感的词(右子图)进行了分离,因此,将句子级表示分为具有相对类别和情感特征的若干组
4. Contribution:
① 提出ECAN,以帮助ACSA任务的隐式方面和情感识别
② 提出一种方面类别和情感的层级解纠缠结构,从而发掘更细粒度的特征
③ SOTA
2. Task Definition
① 数据定义:给定一个包含I和句子的评论集合D,![]() ,其中第i个句子表示为
,其中第i个句子表示为![]() ,这句话有n个单词组成(wj表示这句话的第j个单词);
,这句话有n个单词组成(wj表示这句话的第j个单词);![]() 为预定义的m个方面类别。p为情感极性(积极、中性、消极)
为预定义的m个方面类别。p为情感极性(积极、中性、消极)
② 目标:检测出si中出现的所有方面类别(ACD任务),并对每个检测到的方面类别进行情感分类(ACSC)
3. Approach
ECAN由下面四个部分组成:XLNet连贯感知表示学习、分层解纠缠、用于增强情感上下文的词级句法学习、多任务学习
模型总览:
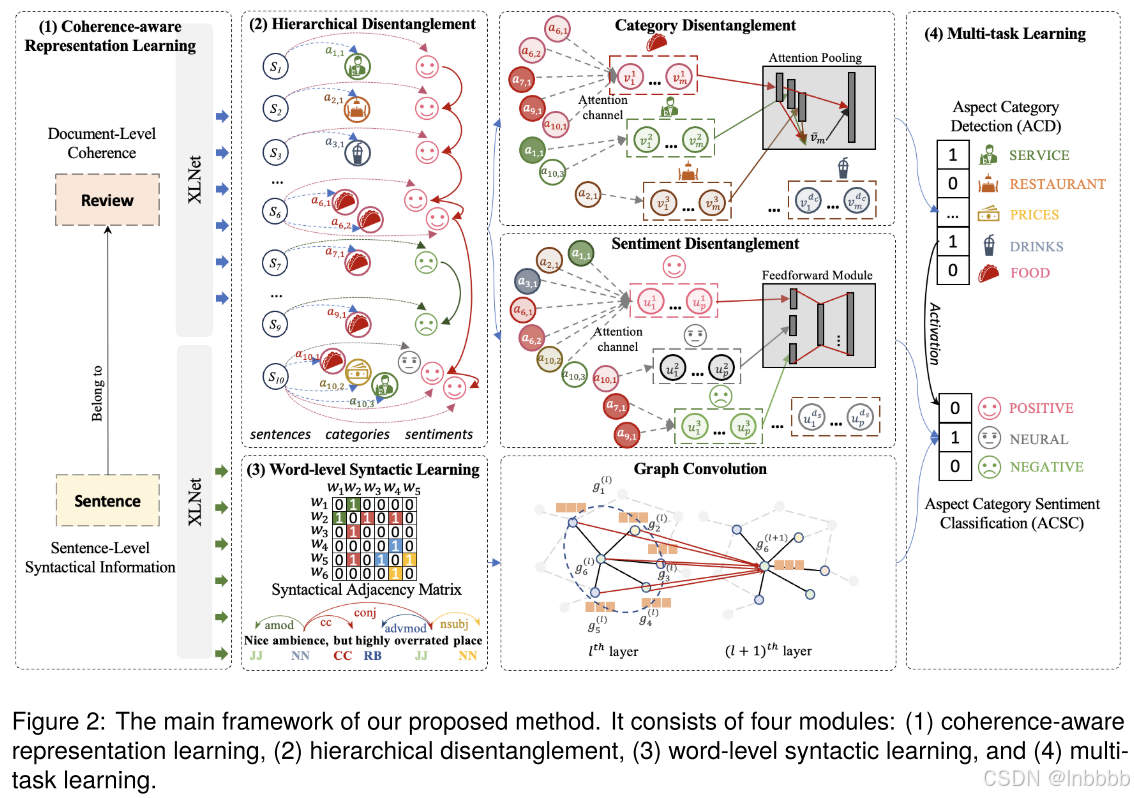
3.1 Coherence-Aware Representation Learning with XLNet
与之前工作(专注于句子中的局部上下文)不同,ECAN从挖掘句子级和文档级(利用XLNet对一致性表示建模)的上下文,以检测方面类别及其情感极性(选择XLNet作为主干,是因为它具有学习较长文本序列的能力)

① 输入形式:
对于每个文档,本文定义的输入序列如下: ![]() ;
;
对于每个句子,本文定义的输入序列如下:
![]() 。
。
通过XLNet,分别得到文档和句子的嵌入表示![]() 和
和![]()
② 连贯感知:为了学习鲁棒的连贯表征,我们使用句子排序对比学习(CL)任务作为辅助任务。它强制要求积极的样本(原始文件)的相干性分数要高于消极的样本(无序文件)。具体来说,本文随机地对原始评论中的句子进行洗牌,以产生B个消极的样本的数量,并应用对比学习来对齐连贯和不连贯的表征
设![]() 为线性投影,
为线性投影,![]() 将连贯文件嵌入表示
将连贯文件嵌入表示![]() 转换为连贯分数,则对比学习过程的损失函数定义为:
转换为连贯分数,则对比学习过程的损失函数定义为:
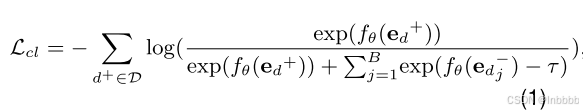
其中d+为积极样本,![]() 为积极样本的得分,消极样本得分同理。
为积极样本的得分,消极样本得分同理。
3.2 Hierarchical Disentanglement
XLNet的连贯建模只能捕获整个文档中句子之间的全局关系(粗粒度),从而阻碍了细粒度任务的性能。所以本文提出同时解开类别及其在句子中情感表示的情感纠缠
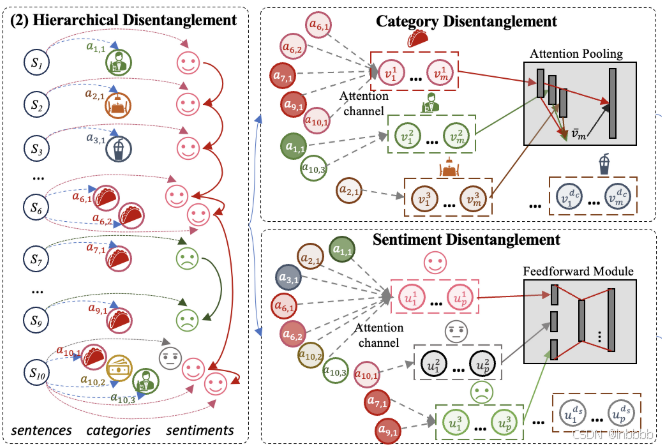
3.2.1 Category Disentanglement
本文采用并行注意力机制来获得表示细粒度类别组件的解纠缠表示块。形式上,对于第i个注意力通道![]() ,给定文档级表示
,给定文档级表示![]() ,先通过切片操作获得文档级表示中的句子表示
,先通过切片操作获得文档级表示中的句子表示![]() 作为第一层的
作为第一层的![]() ,接下来通过堆叠transformer块以获得每个通道的自注意力得分:
,接下来通过堆叠transformer块以获得每个通道的自注意力得分:
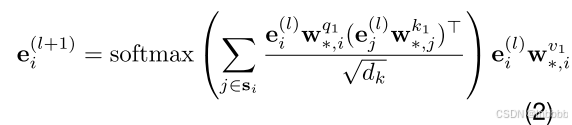
其中W是可训练权重矩阵,dk是维度大小【该公式为更新公式】。随后,将最后一层的自注意得分送入前馈神经网络:
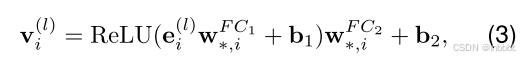
其中W为两个线性变换矩阵,b1和b2为可学习参数。
在经过dc层并行注意力通道后,得到了解纠缠快的表示![]() ,接下来通过下面公式,本文将这些解纠缠表示连接起来,以使用注意力池层进一步选择具有代表性的特征:
,接下来通过下面公式,本文将这些解纠缠表示连接起来,以使用注意力池层进一步选择具有代表性的特征:
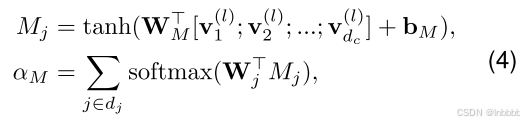
其中W、b分别分可学习参数,最终本公式得到一个注意力权重向量![]()
3.2.2 Sentiment Disentanglement
与3.2.1相似,本模块也采用并行注意力机制从文档级连贯表示![]() 中获得解纠缠情感表示块,其中并行通道定义为
中获得解纠缠情感表示块,其中并行通道定义为![]() 。不同之处在于,解纠缠的情感表示仅通过ACSC任务进行优化,其中包含真实值情感信息。我们注意到,解纠缠情感表示的梯度更新完全由ACSC任务训练;虽然,它是否会被训练是由方面类别信息激活的。其中在第i个通道的自注意力计算公式如下:
。不同之处在于,解纠缠的情感表示仅通过ACSC任务进行优化,其中包含真实值情感信息。我们注意到,解纠缠情感表示的梯度更新完全由ACSC任务训练;虽然,它是否会被训练是由方面类别信息激活的。其中在第i个通道的自注意力计算公式如下:
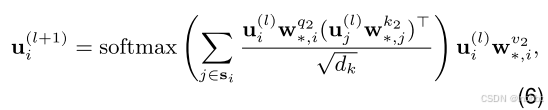
本文根据经验,发现简单的线性变换比注意力池操作更有效,所以把注意力层的输出做如下计算:
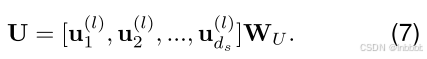
接下来,将输入U输入到position-wise前馈神经网络,得到情感表示的隐藏解纠缠表示:
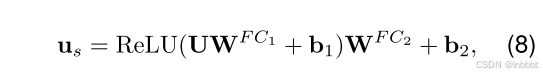
3.3 Word-Level Syntactic Learning for Enhancing Sentiment Semantics
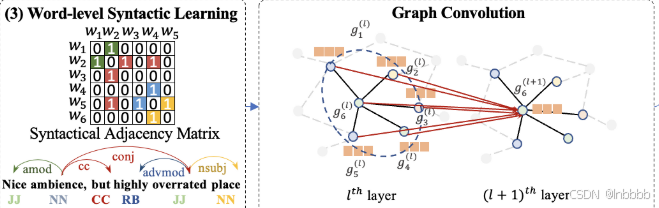
本文使用斯坦福工具得到目标句子的词级依赖树,并使用图卷积从依赖树中学习情感和方面类别之间的局部相关性。该部分的更新公式(GCN)如下:
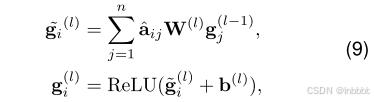
其中![]() 为从上一层GCN获得的第i个单词的表示,W和b的可学习参数。至此,我们得到了局部情感表示,然后将其送入一个线型层:
为从上一层GCN获得的第i个单词的表示,W和b的可学习参数。至此,我们得到了局部情感表示,然后将其送入一个线型层:
![]()
3.4 Multi-Task Learning
本文使用一个多任务框架来联合学习识别句子顺序对比学习的文档级连贯性,检测潜在的方面类别,并识别他们的情感
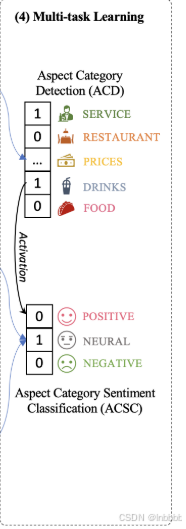
① 方面类别检测任务(ACD)
类别表示的概率计算表示为:
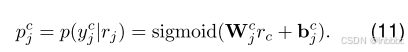
ACD损失函数如下:
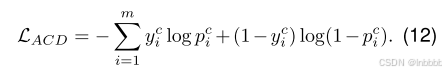
② 方面类别情感分类任务(ACSC)
情感表示由![]() 得到,因此,类别对应的情感概率为:
得到,因此,类别对应的情感概率为:
![]()
ACSA损失函数如下:
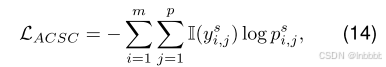
Loss
ECAN总损失:
对比学习损失+ACD损失+ACSC损失,表示如下:
![]()
4. Experiments
5.1 Datasets and Evaluation Metrics
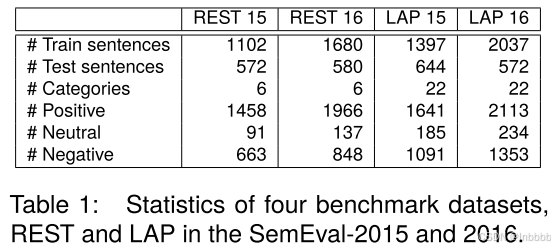
① 数据集
② 评价指标
Precision、Recall、F1分数
5.2 Main Results
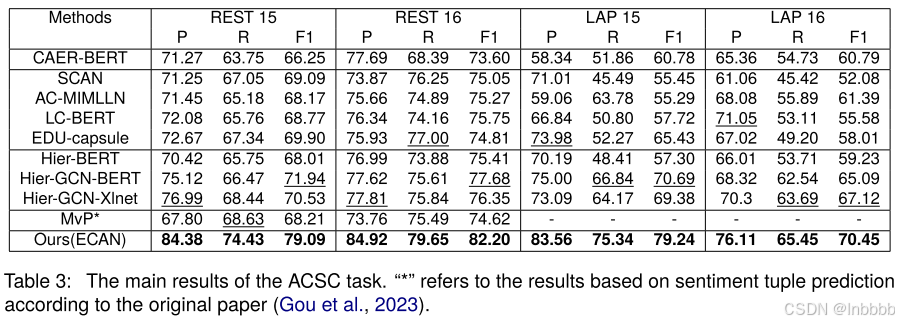
① ACD

② ACSC
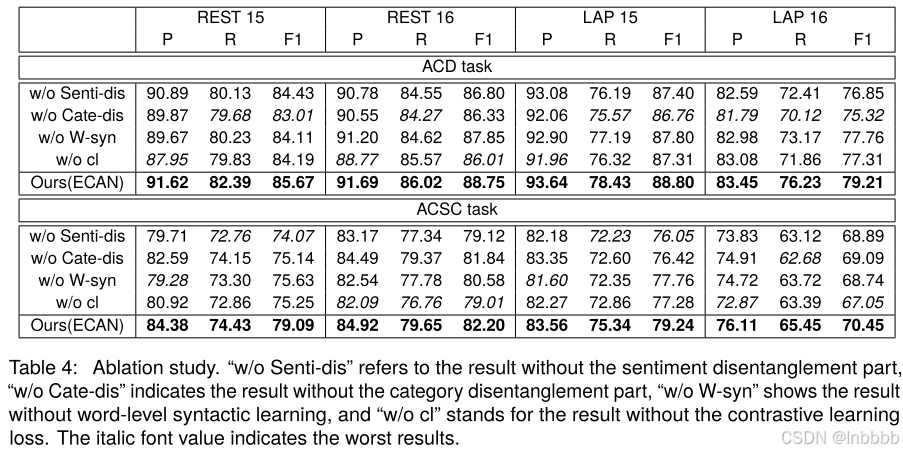
③ 消融实验

















 7352
7352



 到【灌水乐园】发言
到【灌水乐园】发言








