



题目、作者:

Abstract
1. ABSA任务介绍:方面级情感分析(ABSA)是通过各种互补的子任务(方面词抽取、意见词抽取等)从文本数据中提取关于特定实体(方面词)及其相应方面的观点。
2. motivation:先前的研究都集中在为这些子任务模型的复杂设计上,而本文提出一种可扩展到任何ABSA子任务的生成框架
3. 本文方法介绍:
① idea出处:本文方法建立在一篇NAACL的论文InstructABSA,这篇论文提出了一个基于指令调优ABSA模型的方法,其中包含任务描述,然后是ABSA子任务的上下文示例。
② 本文方法:本文提出PFInstruct,通过在任务描述中添加与nlp相关的任务前缀来扩展这种指令学习范式
1. Introduction
1. ABSA子任务介绍:ABSA任务涉及检测文本S中的意见词o,情感极性s以及与之相关联的方面词a,下图展示了nlp任务相关的前缀、ABSA考虑的5个子任务及对应的输入和输出:
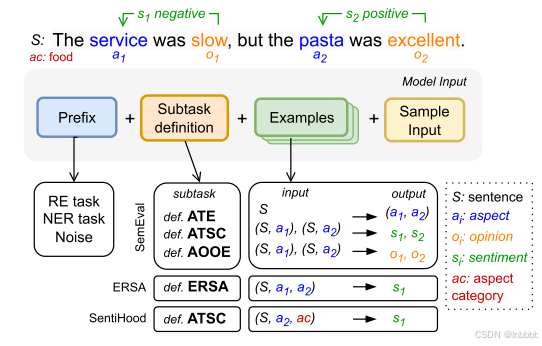
① nlp前缀:
RE:Relation Extraction,关系抽取,旨在从文本中识别并提取实体之间的关系
NER:Named Entity Recognition,命名实体识别,用于识别文本中的实体,如人名、地名、机构名等
更多nlp任务(前缀)可跳转下面连接NLP任务全览:涵盖各类NLP自然语言处理任务及其面临的挑战-优快云博客
② ABSA子任务:
1) ATE:输入一个文本,输出文本中的方面词
2) ATSC:输入文本和文本中的方面词,输出每个方面词对应的情感极性
3) AOOE:输入文本和本文中的方面词,输出文本中的意见词
4) ERSA:输入文本和文本中的方面词,输出情感极性
5) ATSC:输入文本、方面词和该方面词对应的方面类别(比如输入“披萨很好吃”,“披萨”,“食物”),输出情感极性
2. 本文框架介绍:
① 本文框架是对InstructABSA框架的扩展,引入了前缀提示符
② 具体来说,本文在任务中添加了前缀,将评估扩展到生物医学和城市社区等领域,并将所有子任务制定为生成任务。其中添加前缀的目的是:指示模型执行相关的nlp任务,如RE或NER
2. Background and Methodology
2.1 Background: ABSA
1. ABSA介绍:ABSA子任务可以分为单输出子任务和复合输出子任务。在单个输出子任务中,如ATE(方面项抽取)、ATSC(方面-术语情感分类)和AOOE(方面-意见提取),输出被限制为给定文本S中的方面a、意见o或情感s。复合输出子任务要求{a, o, s}实体类型的组合。本文只研究单个输出子任务
2. 本文额外任务(数据集)介绍:此外,本文还在ERSA和SentiHood任务上评估了本文的模型。其中ERSA是ABSA的扩展任务,给定文本S和两个不同的方面词,目标是预测给定S的方面之间关系的情感极性S。SentiHood任务被定义为ATSC任务的扩展,需要对一个或多个方面类别的每个方面词进行情感分类
2.2 Methodology
给定一个示例S,本文构建一个由4个组件组成的提示符,介绍如下:
1. Prefix(前缀)
明确要求模型解决样本S上的NLP任务的初始指令。
目的:将S中的主要实体包含在一个初步的NLP任务中,该任务可以通知后续的ABSA子任务,以确定S中的主要实体的正确输出。这种NLP任务可以命名为实体识别(NER)或关系提取(RE)。如果方面ai是任务输入的一部分,并且样本包含至少两个实体(或方面),则应用RE前缀
2. Task definition
ABSA子任务的简要概述。在情感分类任务中,本文还包括一组预定义的类
3. Examples
一个由两个积极的、消极的和中性域内示例组成的集合
4. Sample input
与上下文示例类似,我们为模型提供输入S,并期望模型按照说明生成相应的输出
前缀例子:

3. Results
首先是本文使用的数据集,如图:

其中前5个数据集是领域常用的数据集,后两个数据集在2.1节中介绍过
3.1 Analysis of SemEval subtasks
下面3个表分别显示了ATE、ATSC、AOOE的实验结果:
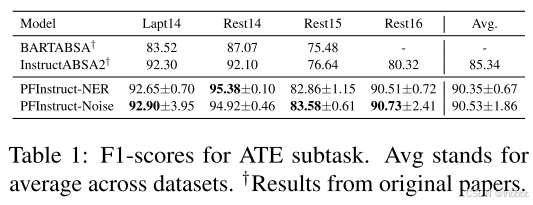
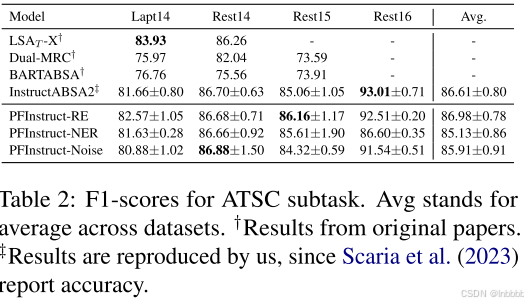
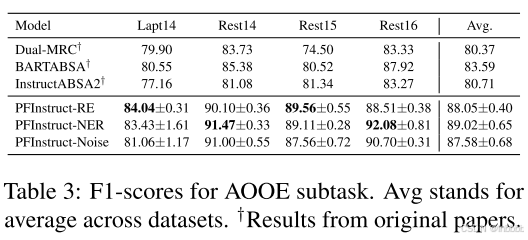
可以看到,与以前的SOTA方法相比,本文的方法在所有子任务上都取得了更好的性能(f1分数)。这些结果验证了我们最初的假设:指示模型解决目标文本S的相关NLP任务似乎补充了模型对S中主要实体的理解,从而导致更准确的预测。
3.2 Analysis of ERSA and SentiHood
下表展示了ERSA和SentiHood两个数据集的结果,可以看出,前缀的选择很重要,因为它会对模型性能产生负面影响
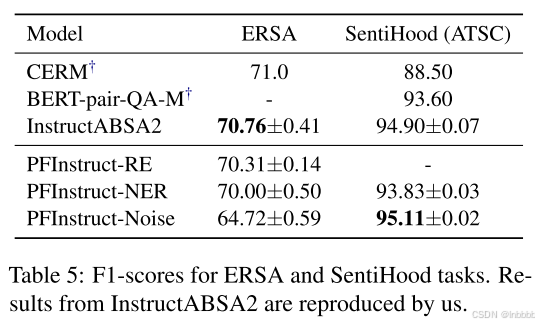
ERSA的固有性质比其他ABSA子任务提出了更大的挑战,因为文本S中表达的情感不一定反映目标实体a1和a2之间关系的情感,在这种情况下,上下文噪声对模型性能的影响最大。模型需要适应一个专门的领域,并了解任务的细微差别。在nlp任务前缀方面,利用a1和a2的知识来推断它们的语义关系(PFInstruct-RE)比一般实体识别(PFInstruct-NER)提高了模型的性能。然而,它并没有超越没有提示前缀(InstructABSA2设置)的模型性能。

















 295
295



 到【灌水乐园】发言
到【灌水乐园】发言








