







在文章中的源码跟踪我们只以一个简单的查询语句为例:
@Test
public void test01(){
SqlSession sqlSession = null;
try{
sqlSession = MybatisSqlSessionFactory.openSqlSession();
//框架根据我们提供的接口的Class文件生成动态代理,我们的sql语句应该就是在这个动态代理的过程中
//生成并执行的
BeautyMapper beautyMapper = sqlSession.getMapper(BeautyMapper.class);
HashMap<String ,Object> selectMap = new HashMap<>();
selectMap.put("id",2);
selectMap.put("name","'苍老师' or 1 ");
Beauty beauty = beautyMapper.getBeautyById(selectMap);
System.out.println(beauty.toString());
}catch (Exception e){
System.out.println("Mybatis查询数据库错误:"+e.getMessage());
}finally {
if (sqlSession!=null){
sqlSession.close();
}
}
}
其核心的语句为:
BeautyMapper beautyMapper = sqlSession.getMapper(BeautyMapper.class);
HashMap<String ,Object> selectMap = new HashMap<>();
selectMap.put("id",2);
selectMap.put("name","'苍老师' or 1 ");
Beauty beauty = beautyMapper.getBeautyById(selectMap);
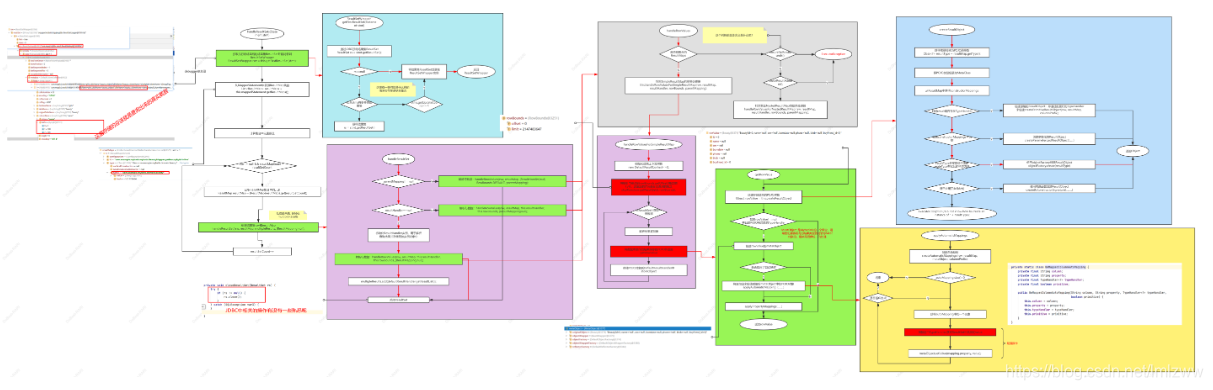
文章中包含六个程序的流程图或时序图,这些时序图是通过ProcessOn制作,在下面的连接中可以看到更清晰的图片:
1、https://www.processon.com/view/link/60ebb6cce0b34d7b4e79d36b
2、https://www.processon.com/view/link/60ebb6e86376892fca9da7fd
3、https://www.processon.com/view/link/60ebb6f50e3e7478e61f417b
4、https://www.processon.com/view/link/60ebb7020e3e7478e61f41d1
5、https://www.processon.com/view/link/60ebb71a5653bb2610707bcb
6、https://www.processon.com/view/link/60ebb72e7d9c0831271e4bee
1、获得Mapper动态代理

第一步的过程中,当执行BeautyMapper beautyMapper = sqlSession.getMapper(BeautyMapper.class);时候,首先进入SQLSession的默认实现类DefaultSqlSession,这这个类内部相应的方法通过调用Configuration、MapperRegistry类中的方法,最终在MapperProxyFactory通过获取相应的Mapper接口(BeautyMapper)的代理工厂来获取对应Mapper的代理对象。
2、获得MapperMethod对象

在第一步的过程中我们通过MapperProxyFactory构造了一个MapperProxy(new MapperProxy),这样每次在调用Mapper接口中的Dao层查询方法的时候,都会走代理的invoke方法,这里会先判断代理的这个方法是否为Object或是Default方法,如果是的话直接执行。如果不是就进入到了我们第二部,先获取MapperMethod mapperMethod
MapperMethod 的获取是通过调用cachedMapperMethod(method);,通过这个方法名也可以看出MapperMethod的获取首先是尝试从内存中获得如果缓存中有的话就取出并返回如果内存中没有的话则进行创建,并将创建出来的MapperMethod放入倒缓存中。这里我们着重说的是创建的过程。
MapperMethod的创建可以说成是,构建SqlCommand、MethodSignature。其中MethodSignature对象中存储的是这个方法相关的信息。
public MapperMethod(Class<?> mapperInterface, Method method, Configuration config) {
this.command = new SqlCommand(config, mapperInterface, method);
this.method = new MethodSignature(config, mapperInterface, method);
}
创建SqlCommand 的时候首先要获取MapperStatement,他用于保存映射器的一个节点(select|insert|delete|update)。
包括许多我们配置的SQL、SQL的id、缓存信息、resultMap、parameterType、resultType、languageDriver等重要配置内容。如果没有MapperStatement并且不存在@Flash注解的话程序将会报错。

SqlCommand 中存储的有两个属性,这两个属性的值为:

至此MapperMethod的创建就已经完成,创建完成中执行mapperMethod.execute(this.sqlSession, args);

3、根据SQL指令跳转执行语句

经过一些列的判断选择合适的指令:result = sqlSession.selectOne(this.command.getName(), param);,这里传递进去的param就是我们在调用之初设置的参数:

在这里我们开始进入正式的查询操作,也就是进入到我们程序的第四步:
4、查询前的缓存处理
在决定了最终的查询要执行那条语句之后,就开始了正式的查询语句处理,但是在执行从数据库中查询的这个操作之前我们需要做几部准备工作;
1、获取当前方法对应的MappedStatement、这里面有我们执行中的上下文环境
2、获取BoundSql,BoundSql值经过MappedStatement、获取经由RawSQLSource、StaticSQLSource创建得到;创建得到的BoundSql返回给到MappedStatement,在这个类中根据条件如果有需要则进行重建,将得到的BoundSql返回CachingExecutor
BoundSql的debugger信息:

CachingExecutor中得到BoundSql之后,开始做缓存的准备,首先是根据目前得到的信息创建缓存的key,eg:

Key:794801813:3034229127:com.example.mybatis.mybatis.BeautyMapper.getBeautyById:0:2147483647:select
id,name,sex,borndate,phone,photo,boyfriend_id from beauty where id = ? and name = ?:2:苍老师:dev
在按到BoundSql以及key之后,调用query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);,开始语句执行,这个query方法还是在CachingExecutor中的,我们可以明白目前的这个查询还是在缓存的范畴,而事实确实是这样的,程序会先判断是否有二级缓存,如果有二级缓存,则进行二级缓存相关的操作,如果没有二级缓存则进入一级缓存。进入二级缓存也并不是就一定可以获得我们想要的结果的,如果没有,他们都会通过类似于代理的思想调用BaseExecutor中的查询方法:
在BaseExecutor的方法中会有一个this.queryStack的属性,这个属性可以理解为锁,也可以理解为是与多线程或是缓存相关的,他会在这个整个方法中起一些作用。不过这这里整体的处理流程是先判断在以及缓存中是否有值,如果有的话在以及缓存中取值如果没有的话在执行queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);,开始正式在数据库中查询。关于查询后一级缓存相关操作是在queryFromDatabase而非是BaseExecutor的query方法中。

不管在二级缓存的时候就进行数据库查询操作还是到以及缓存的时候才进行了数据库的查询操作,调用queryFromDatabase这个方法就是开始正式进入到执行DB查询的步骤,执行DB查询这其中就有JDBC的一些端倪了,具体的介绍我们见与第五步:
5、执行DB查询操作
Mybatis在执行SQL操作从数据库查询数据的时候底层用的也是JDBC的相关内容,所以想要理解Mybaits在执行DB操作时候的步骤就应该先熟悉JDBC在操作数据库的时候有那几步:
1、注册驱动
Class.forName("com.mysql.cj.jdbc.Driver");
2、根据驱动获取连接
connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/muse?useSSL=false",
"root", "root");
3、通过connection获得statement
ps = connection.prepareStatement("select name, age from tb_user where id = ?");
ps.setInt(1, 1);
4、利用statement执行对象的SQL
rs = ps.executeQuery();
在这一步的过程中注册驱动不需要关注,我们在执行DB查询的这一步中接下来要做的就是获取Connection、Connection的获取与使用是在SimpleExecutor中但是获取Connection的具体方法是在BaseExecutor中,这两个类相当于是一个继承的关系,子类调用父类的方法。当Connection获取成功之后程序开始执行handler.prepare(connection, transaction.getTimeout());来获取Statement,获取Statement之后进行的就是参数处理操作handler.parameterize(stmt);,参数处理操作最终调用的能力是DefaultParameterHandler他实现了ParameterHandler接口。执行完parameterize(stmt);方法之后我们得到的相关语句就是完整的SQL语句,这一细节在下面的流程图中有所展现。
对照JDBC的执行流程在对比我们这个部分发现我们的Statement流程构建还没有描述,接下来要说的就是这个。这个操作是发生在获取Connection之前、进行参数处理之后,处理完入参的们问题prepareStatement也就执行完毕,返回一个完整的Statement:连接的获取、Statement创建、Statement晚上参数创建多是发生在SimpleExecutor中的:
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
/** 获得Connection实例 */
Connection connection = getConnection(statementLog);
// eg1: handler=RoutingStatementHandler
/** 调用了StatementHandler的prepared进行了sql的预编译 */
stmt = handler.prepare(connection, transaction.getTimeout());
/** 通过PreparedStatementHandler的parameterize来给sql设置入参 */
handler.parameterize(stmt);
// eg1: 返回org.apache.ibatis.logging.jdbc.PreparedStatementLogger@2e570ded
return stmt;
}
获取到完整的Statement之后执行 handler.query(stmt, resultHandler);,开始执行最后的查询操作,这时候传递进去的就又stmt、resultHandler,后边的这个参数用来处理结果集这是我们在第六部分需要学习的内容。

6、针对ResultSet结果集装换为POJO对象
对结果集进行分装首先是要从JDBC的结果中获取查询结果的信息ResultSet并分装到ResultSetWrapper
ResultSetWrapper rsw = this.getFirstResultSet(stmt);
这是查询结果的信息,我们还需要获取一个结果集相关的映射信息,即ResultMap信息:
List<ResultMap> resultMaps = this.mappedStatement.getResultMaps();
这里我们应该对MapperStatement这个对象熟悉,这是在前面的几个步骤中常见的一个重要的类,有了上面的结果与映射关系,我们就可以进行结果集的处理。
这个处理的先后顺序任然是围绕ResultSet以及ResultMap展开的,首先我们对ResultSet进行一些判断,例如是否有映射关系是否有ResultHandler等,根据这些不同的信息来调用handleRowValues,区别在于传递进去的参数不同
从这个方法的名称我们也可以看出这个方法是用来处理行数据,处理行数据的时候他会判断这个行中是否有聚合,换到我们数据库的层次来说就是是否关联了其他的表,这个映射关系可以是一对多或是一对一的关系。这时候就已经也要进入到对数据的最终处理了调用的方法是handleRowValuesForSimpleResultMap
在这里首先有一个分页查询的支持,分页查询之后开始对结果集进行循环处理,调用的是getRowValue()方法。在这个方法中先通过.createResultObject来创建POJO对象,创建这个对象的方式根据不同的条件也有不同的创建方式。框架就是对普通处理流程的一层层分装,在Mybatis中也会将结果类型分装为MeatObject的类型,这里面包含的有POJO对象。
如果这个结果集中启动了自动映射,就会调用applyAutomaticMappings来进行自动映射,自动映射的过程中用到了TypeHandler,同时里面的UnMappedColumnAutoMapping,也是比较有意思的东西,从这里面的属性就可以看到,数据库字段与代码中实体属性的一个映射关系。
private static class UnMappedColumnAutoMapping {
private final String column;
private final String property;
private final TypeHandler<?> typeHandler;
private final boolean primitive;
public UnMappedColumnAutoMapping(String column, String property, TypeHandler<?> typeHandler, boolean primitive) {
this.column = column;
this.property = property;
this.typeHandler = typeHandler;
this.primitive = primitive;
}
}

















 246
246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









