




在大型语言模型(LLM)的应用领域,参数调节对输出质量起着决定性作用,而温度(Temperature)参数便是其中掌控输出随机性与确定性平衡的核心要素。无论是追求精准的事实问答,还是需要富有创意的故事生成,合理设置温度参数都能让模型输出更贴合需求。本文将系统拆解温度参数的工作原理,结合实例解析不同取值的影响,并提供实用的调优指南,助力你成为LLM温度调节的高手。

一、温度参数的核心原理:重塑概率分布的“魔法旋钮”
语言模型生成文本时,本质上是在每个步骤从候选词汇(Token)中进行概率采样。例如,当模型预测下一个词时,会对“天空”“海洋”“森林”等可能词汇分配不同概率。而温度参数的作用,就是通过数学变换重塑这些概率分布,进而改变采样结果的特性。
(一)概率调整的数学逻辑
温度参数通过特定公式对原始概率进行重缩放,其核心公式如下:
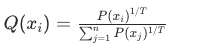
其中,$P(x_i)$ 是模型生成的原始概率,$T$ 为温度值,$Q(x_i)$ 是调整后的概率,$n$ 为候选词汇总数。
从公式可见,温度参数通过指数运算改变概率间的相对权重。当温度为1时,$1/T = 1$,公式简化为
![]()
,即原始概率保持不变。这也是为什么温度=1被视为“基准线”——此时模型完全按照自身预测的原始概率分布进行采样。
当温度小于1时,$1/T$ 成为大于1的指数(例如温度=0.5时,指数为2)。此时高概率词汇的优势会被放大,低概率词汇的权重则被进一步压制。就像把概率分布的“山峰”变得更陡峭,让最可能的选项更容易被选中。例如原始概率为[0.6, 0.3, 0.1]时,温度=0.5会将其调整为[0.78, 0.2, 0.02],高概率词汇的占比显著提升。
当温度大于1时,$1/T$ 成为小于1的指数(例如温度=2时,指数为0.5)。此时低概率词汇的权重会相对提升
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 6714
6714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











