







最近比较火的一个大模型就是deepseek了。目前几乎所有主流的平台都支持了接入deepseek大模型。下面我们来看看怎么在本地部署和运行一个deepseek大模型。
目前来说最简单的方式就是使用ollama来部署。我们去官网ollama.com下载一下ollama,并安装。
安装完成以后输入ollama -v.看到版本信息以后,就表示安装完成了。
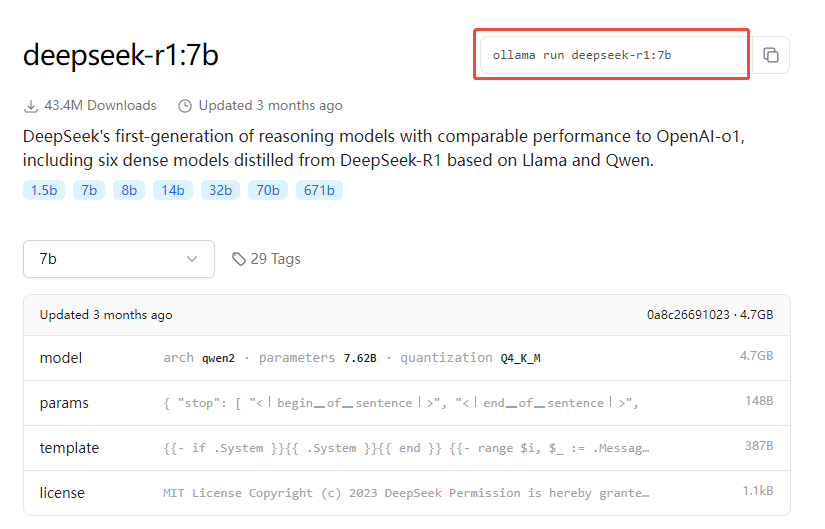
下一步我们开始安装模型,在ollama官网输入deepseek搜索,会列出所有deepseek的模型。这里我们选择deepseek-r1.进入后可以看到r1的不同版本。这些版本是1.5b、7b、8b、14b、32b、70b-直到671b,b是十亿的意思,7b就是含有70亿个参数,671b就是含有6710亿个参数。参数越高当然就是代表模型越强大,但是选择版本要根据你机器的配置来,机器配置不够是无法运行高参数的模型的。这里我们一般的配置可能选择一个7b的模型,自己尝试一下。
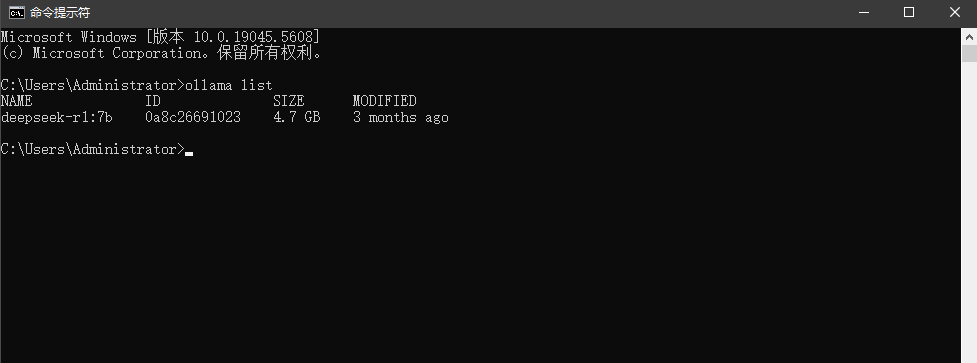
在命令行运行ollama run deepseek-r1:7b,他会自动去下载模型。下载完成后我们可以运行命令
ollama list查看一下当前有的模型
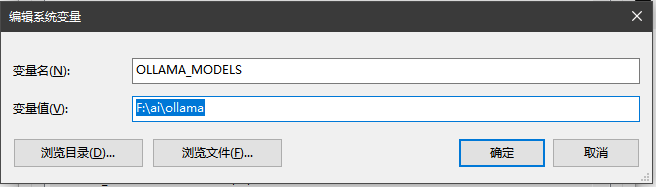
这里有个注意事项,ollama默认是安装到C盘的,如果C盘空间不太够,我们需要更改一下模型的下载路径。我们设置一个环境变量,就能更改模型的下载路径了。在系统环境变量里面添加一个OLLAMA_MODELS环境变量,设置你想要存储的位置。
安装完成以后,我们就可以使用了。我们可以通过命令行进行提问;
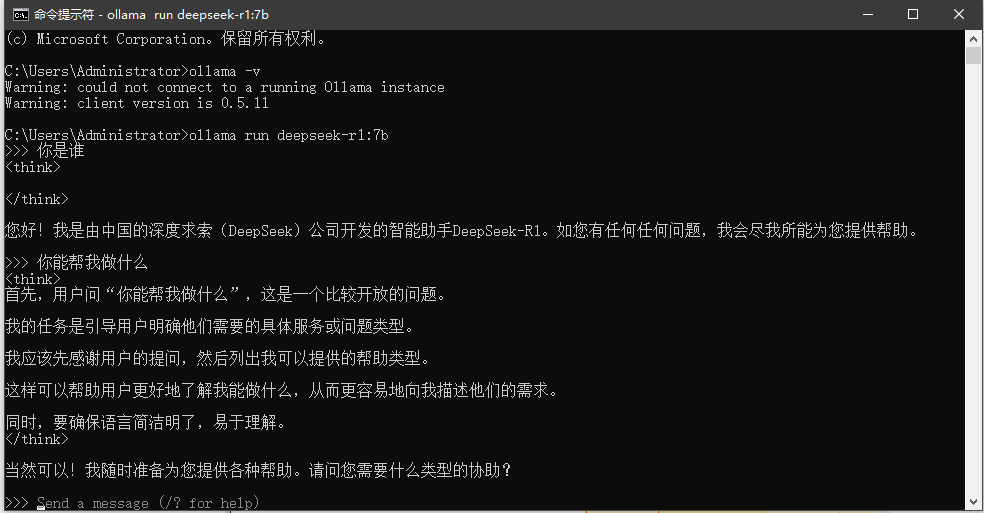
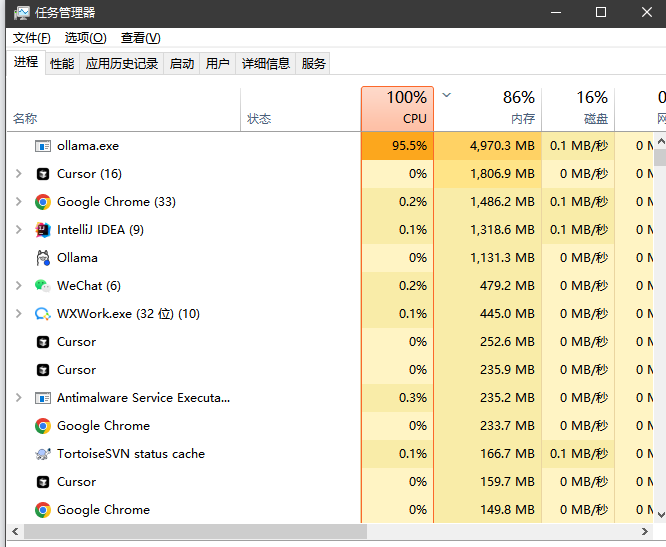
可以看到CPU都跑满了。我这里是一个普通的办公电脑,并未带显卡的,跑个7B就已经很吃力了。
至此我们就完成了deepseek的本地部署,有兴趣的可以自己去尝试一下

















 18万+
18万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









