




声明:平时看些文章做些笔记分享出来,文章中难免存在错误的地方,还望大家海涵。搜集一些资料,方便查阅学习:http://yqli.tech/page/speech.html。语音合成领域论文列表请访问http://yqli.tech/page/tts_paper.html,语音识别领域论文统计请访问http://yqli.tech/page/asr_paper.html。如何查找语音资料请参考文章https://mp.weixin.qq.com/s/eJcpsfs3OuhrccJ7_BvKOg)。如有转载,请注明出处。欢迎关注微信公众号:低调奋进。
TALCS: An Open-Source Mandarin-English Code-Switching Corpus and a Speech Recognition Baseline
本文是好未来在2022.06.27更新的文章,主要开源最大的中英混合训练语料,为语音识别的Code-switching方向研究做贡献。
(开源数据统计可参见http://yqli.tech/page/data.html)
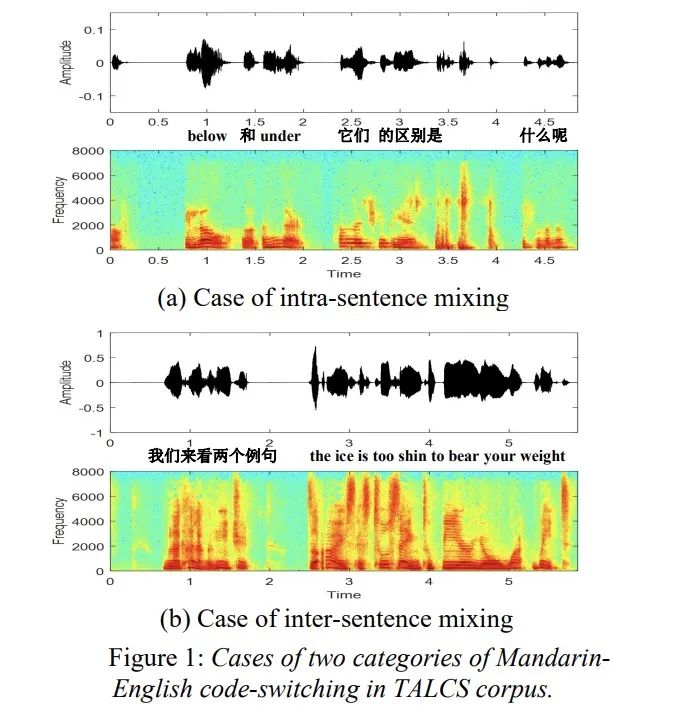
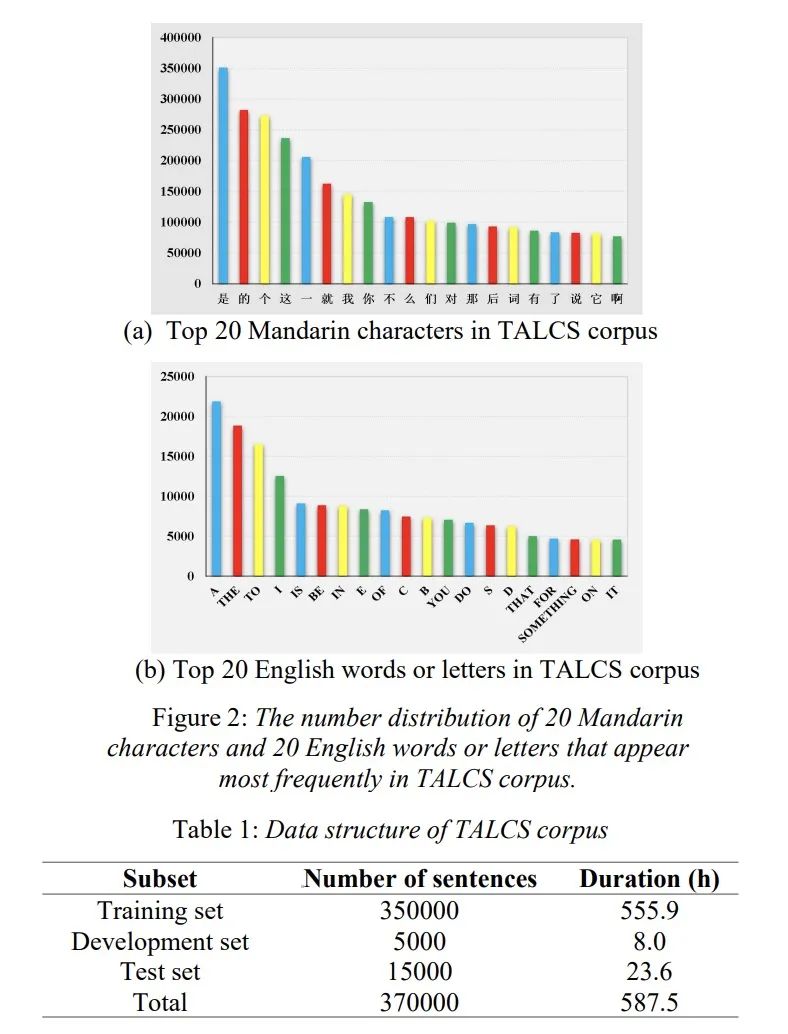
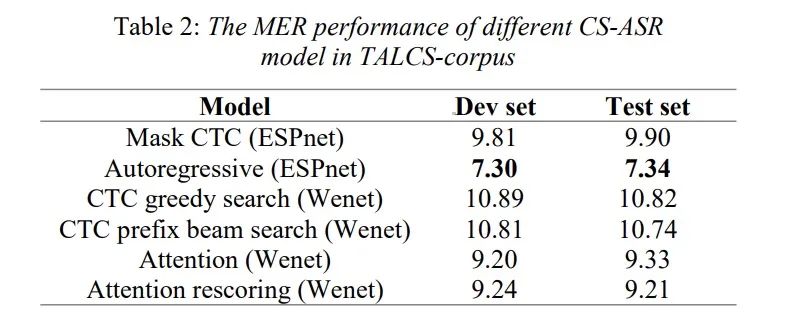
由于本文主要工作是开源全球最大的中英混合数据,我们就不再介绍背景,直接查看数据集的情况。该数据集为好未来英语课授课音频,包含中英文混合讲话的情况,每条音频只有一位说话人,该数据集有100多说话人。(文件63.36G)该数据包含了如图1所示的句内和句间混合的样例。该数据中的中文汉字和英文单词之间的比例为13:1,其中top 20如图2所示。table 1展示了语库的训练集合测试集的划分情况,table 2展示使用该数据集在espnet和wenet上的实验结果。
| 数据规模 | 587小时音频 |
| 采样率 | 16KHz |
| 采样位声 | 16bit |
| 录制设备 | 普通麦克风 |
| 说话人 | 200+ |
| 录制时间 | 2019年 |
| 数据格式 | 音频:.wav;标注结果:.txt |
| 音频长度 | 1~60s |
| 数据类型 | 英语课教师授课音频 |


















 2455
2455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











