




声明:平时看些文章做些笔记分享出来,文章中难免存在错误的地方,还望大家海涵。搜集一些资料,方便查阅学习:http://yqli.tech/page/speech.html。语音合成领域论文列表请访问http://yqli.tech/page/tts_paper.html,语音识别领域论文统计请访问http://yqli.tech/page/asr_paper.html。如何查找语音资料请参考文章https://mp.weixin.qq.com/s/eJcpsfs3OuhrccJ7_BvKOg)。如有转载,请注明出处。欢迎关注微信公众号:低调奋进。
Scaling ASR Improves Zero and Few Shot Learning
本文为facebook在2021.11.10更新的文章,主要研究ASR在超大规模的数据(450万小时)和超大参数(100亿)的模型的实验效果,具体文章链接https://arxiv.org/pdf/2010.10504v1.pdf
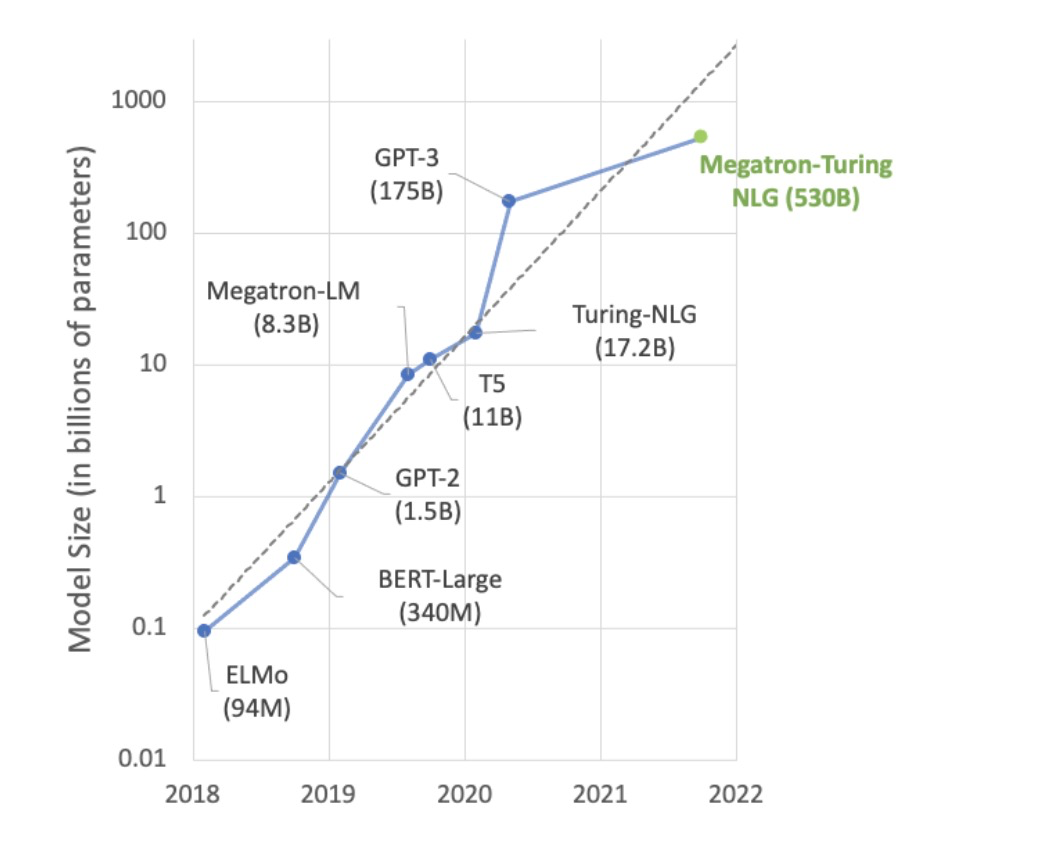
先说个题外话题,AI的研究更像奥运比赛:更高,更快,更强。更高:准确度等性能指标更高。更快:训练、推理服务速度更快。更强:鲁棒性、泛化能力更强。随着AI发展,模型的参数量、数据量以及计算资源等因素使该领域研究归于巨头掌中。Nvidia GTC2021大会的语言模型Megatron已经达到5300亿的参数量,训练如此超规模模型所使用的数据、计算资源让绝大多数的研究机构和企业无法参与。
除了以上NLP的实例,语音识别的研究也进入超参数超数据时代,比如2021.10.01 google更新的文章BigSSL: Exploring the Frontier of Large-Scale Semi-Supervised Learning for Automatic Speech Recognition的模型参数已经达到80亿,使用的无标签和有标签数据接近100万小时数据。而本文的数据量达到450万小时,100亿的参数量。对于以上试验,我们是无法进行复现试验,因此我们只能瞻仰这些大牛们的工作,扩展视野)
一 研究背景
使用超大规模数据在NLP、CV、ASR领域越来越流行。但模型参数量和数据量是相互制约的瓶颈,即对于一个模型不是数据越多越好,相反亦然。因此本文探索了数据量和参数量的制约关系,并提高ASR的性能。
二 详细设计
本文使用了E2E VGG-transformer transducer模型 (如图1和图2所示,图片取自文章
Transformer-Transducer: End-to-End Speech Recognition with Self-Attention),其参数量为table 2所示。另外本文也试验400亿参数的模型,但该实验没有提高性能,因此不放入本文的对比试验中,留待将来进行探索。为了训练模型有效性,本文使用aligmnment restricted transducer loss、fully shared data-parallel、activation checkpointing和mixed precision training等技巧。
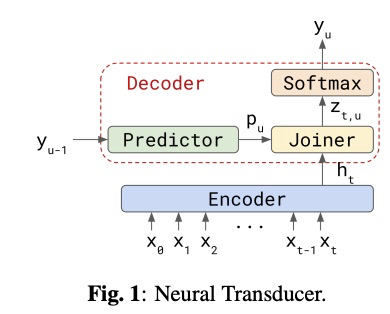
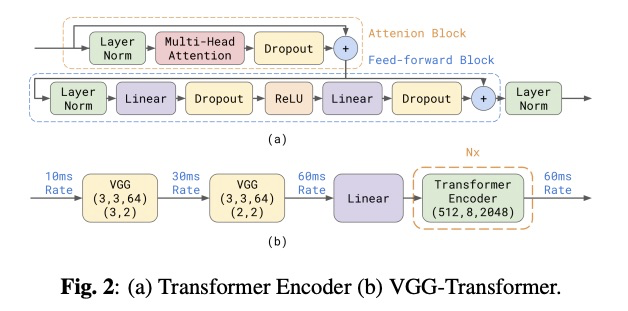
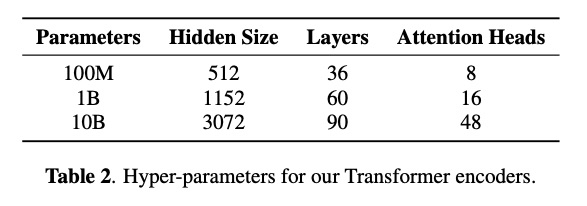
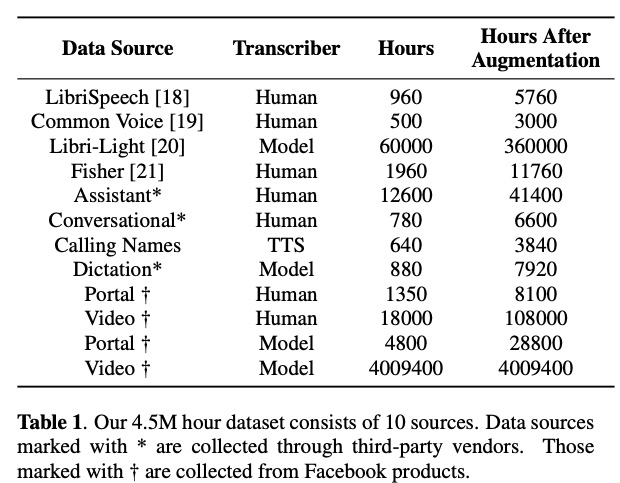
table 1为本文的数据详情,共450万小时,大部分为facebook内部的video数据。对于该数据,本文提出了words per second、confidence score、model disagreement、segment+alignment、rara data进行数据筛选。对于数据的标注,可以使用监督和半监督训练的10亿参数量的模型进行标注。
三 试验
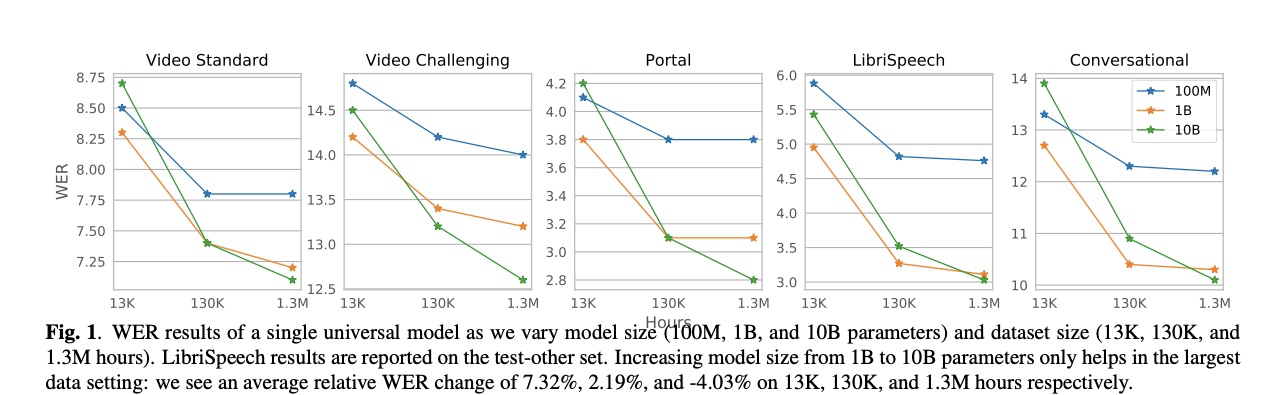
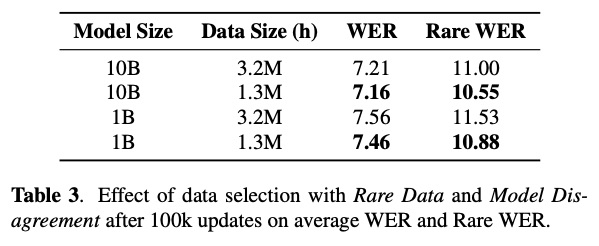
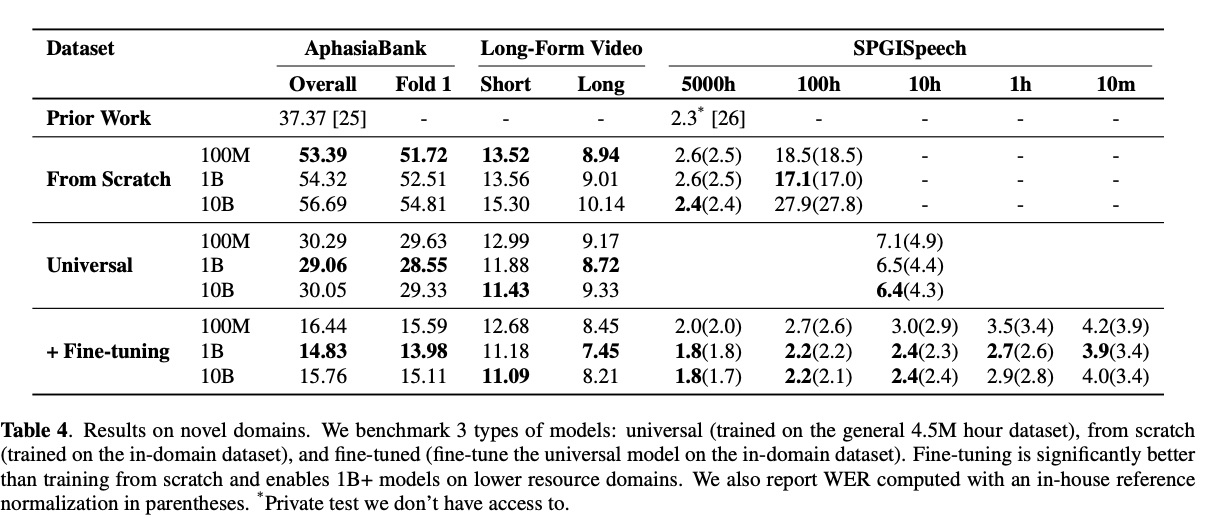
图一展示模型大小和数据量关系,可以看出在13万小时数据,10B的模型相较1B的模型不具有优势,只有数据超大时候才显出优势。table 2展示数据选取对结果的影响,该结果显示通过特定规则对数据进行筛选和调配对结果有很大影响。table 4展示zero-shot和few-shot的实验,其中AsphasiaBank为语言障碍语料。该实验有Universal为从450万语料训练基础模型、From Scratch为从特定语料开始训练、Fine-tuning为在Universal基础上进行微调实验。可以看到fint-tuning的效果最好。
四 总计
本文为ASR的超大规模数据和超大模型上的探索实验,主要探索了数据量和参数量的制约关系,并提高zero-shot和few-shot的实验效果。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











