




 本文主要探讨Diffusion Probabilistic Model(DPM)在语音合成(TTS)领域的应用,提到了DiffWave、WaveGrad等近期的研究成果,并指出这些文章的特点是公式复杂、内容深入。作者分享了自己的PPT,概述了DPM在语音合成中的使用情况,其中部分图片来源于孔之丰博士的讲解视频。
本文主要探讨Diffusion Probabilistic Model(DPM)在语音合成(TTS)领域的应用,提到了DiffWave、WaveGrad等近期的研究成果,并指出这些文章的特点是公式复杂、内容深入。作者分享了自己的PPT,概述了DPM在语音合成中的使用情况,其中部分图片来源于孔之丰博士的讲解视频。
声明:工作以来主要从事TTS工作,平时看些文章做些笔记。文章中难免存在错误的地方,还望大家海涵。平时搜集一些资料,方便查阅学习:TTS 论文列表 http://yqli.tech/page/tts_paper.html TTS 开源数据 http://yqli.tech/page/data.html。如转载,请标明出处。欢迎关注微信公众号:低调奋进
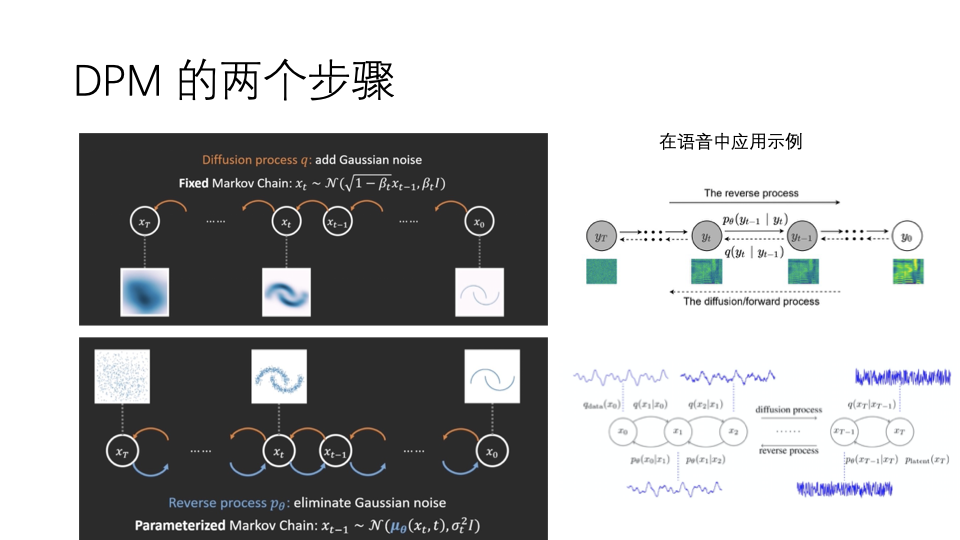
Diffusion Probabilistic Model主要在图片处理领域火了一阵子,这两年在语音领域应用突然多了起来。2020年出现两篇DPM应用到声码器的文章:DiffWave和WaveGrad。今年的5月份连发三篇关于DPM应用到声学模型的文章Grad-TTS, DiffSing和DiffSVC。这些文章有公共特点:公式多,文章长,很多地方都需要读者慢慢研究相关的理论。当然我没有死扣这些公式,我只是看最后推理的结果,把整体思路整明白即可。我在这里先放个大概,主要总结了DPM在语音中应用,内容主要是我的PPT。另外我强调一下本PPT中的图片,为了讲解简洁清晰,截取了孔之丰博士讲解DiffWave视频中的两张图片。



 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 398
398




 到【灌水乐园】发言
到【灌水乐园】发言









