




声明:语音合成论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
PPSpeech: Phrase based Parallel End-to-End TTS System
本文出自北京邮电大学,更新2020.08.06,本文主要针对现在句子级别的自回归系统tacotron2,实现短语级的系统,从而提高推理速度。具体的文章链接 https://arxiv.org/pdf/2008.02490.pdf
1 研究背景
语音合成的自回归系统taoctron2不便于进行并发合成,因为此刻的
推理需要依赖上一时刻的输出,因此推理速度十分缓慢。本文针对句子级别(sentence-level)系统存在的问题,提出短语级别(phrase-level)的合成系统,使其可以并发合成,从而提高推理速度。为了解决使用短语级别带来的韵律发生变化和音色变换,本文又添加acousic embedding和context embedding作为taoctorn 2的条件特征,从而使其合成的质量跟句子级别保持一致。
2 详细设计
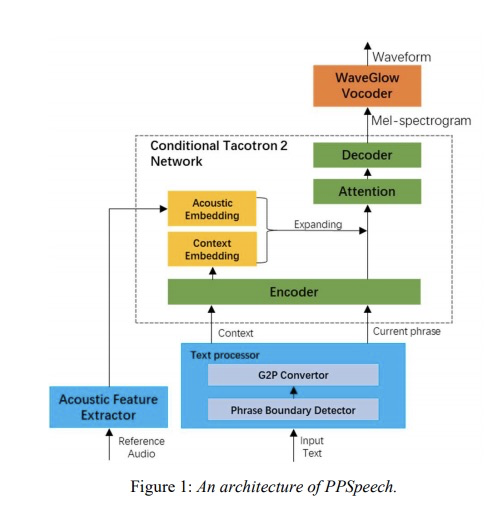
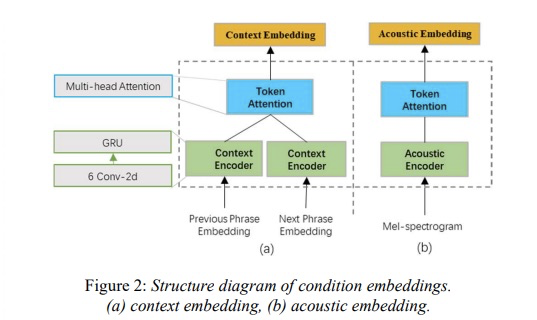
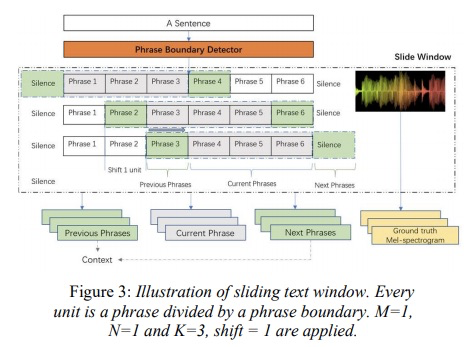
具体的系统架构为图1所示,为了解决使用短语级别带来的韵律发生变化和音色变换,本文添加acoustic embedding和context embedding作为taoctorn 2的条件特征,其中acoustic encoder和context encoder的结构如图2所示。context encoder的生成需要前一个phrase和后一个phrase经过tacotron2的encoder后的embedding作为输入。另外整个系统的输入类似滑动窗口,具体的如图3所示,其中M为前面phrase个数,N为后面phrase个数,k为当前phrase个数。训练的时候,M=N=1,K=3,推理的时候M=N=K=1。
3 实验
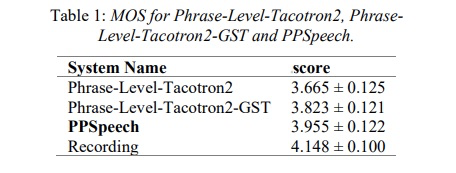
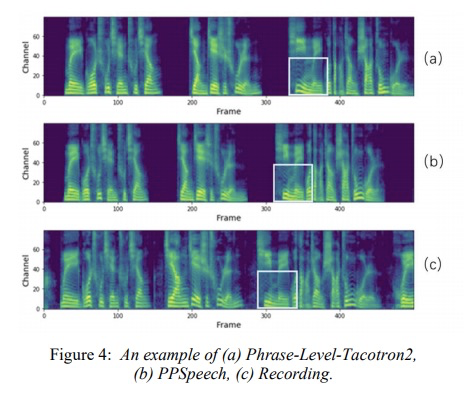
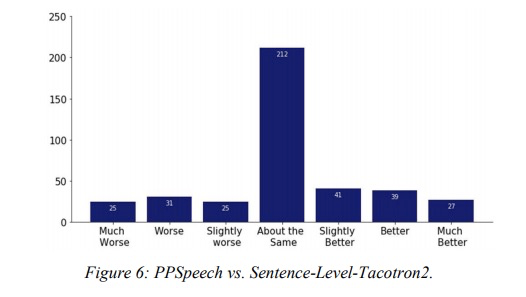
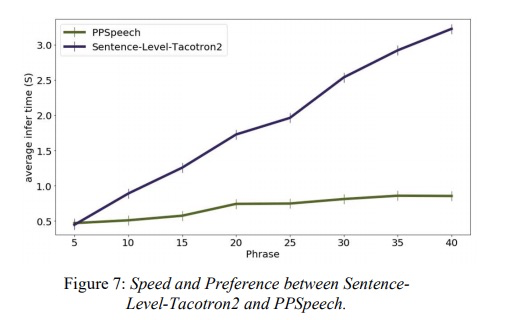
本文先对比使用phrase级别的合成效果。由table 1显示,本文ppspeech的MOS值最高,因此添加context encoder和acoustic encoder模块具有提高合成音频自然度的效果。接下来图4和图5分别对比context encoder和acoustic encoder,添加后的语谱图与原始录音更一致。图6和图7是和句子级别系统进行合成音质和合成速度对比,图6显示本系统和句子级别合成质量几乎相等,图7显示合成速度随着句子长度几乎不变。

4 总结
本文针对语音合成系统使用句子级别存在无法并发合成问题,提出短语级别合成系统,使其可以并发合成,从而提高推理速度。实验证明本系统可以保证合成音频质量的前提下,合成速度与原来系统对比,随着句子长度增长优势越明显。



















 1162
1162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











