







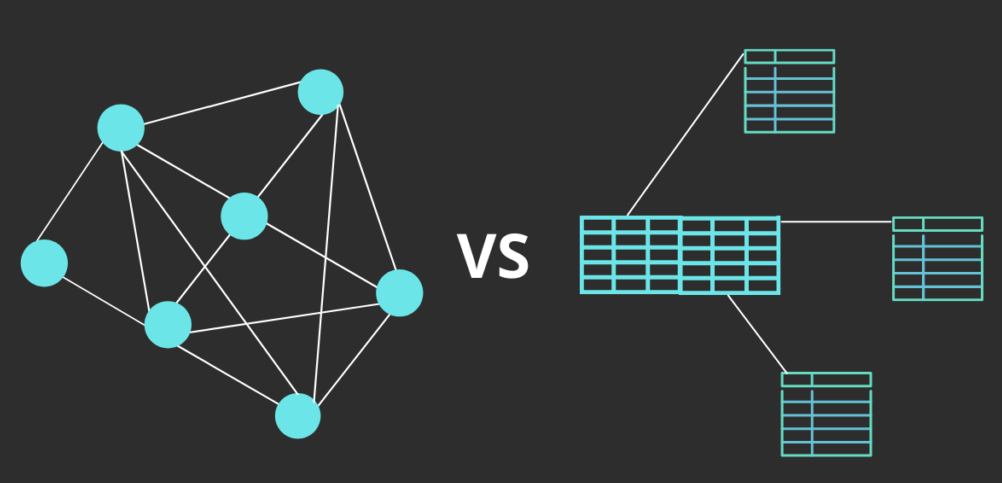
相信大家对于与传统关系型数据库(如MySQL、PostgreSQL等)一定不会陌生,在这里我就不浪费篇章进行介绍了,本文我们来重点了解一下什么是知识图谱数据库,以及它和传统数据库的主要区别。
如果大家想了解跟多关于知识图谱的内容,可以参考文章
一文读懂什么是知识图谱(Knowledge Graph)-优快云博客
知识图谱数据库
知识图谱数据库(Knowledge Graph Database)是一种专门用于存储、管理和查询知识图谱的数据库系统。知识图谱是一种以图结构(Graph)形式组织和表示知识的数据库,通过实体(Entity)、属性(Attribute)和关系(Relationship)描述现实世界中的事物及其关联。知识图谱数据库的核心目标是高效处理复杂的关联关系,支持灵活的语义查询。
常见知识图谱数据库
-
图数据库(Graph Databases):
-
Neo4j:最流行的图数据库,支持属性图模型。
-
Amazon Neptune:AWS托服务的图数据库,支持RDF和属性图。
-
JanusGraph:开源分布式图数据库,支持大规模数据。
-
ArangoDB:多模型数据库,支持图、文档和键值存储。
-
-
RDF三元组存储(Triple Stores):
-
Apache Jena:开源框架,支持RDF和SPARQL查询。
-
Virtuoso:高性能三元组存储,适合语义网应用。
-
Ontotext GraphDB:专为知识图谱设计的RDF数据库。
-
-
多模态数据库:
如 TigerGraph,结合图计算与机器学习,支持复杂分析。
知识图谱数据库 vs 传统数据库:核心差异对比
| 对比维度 | 知识图谱数据库 | 传统关系型数据库 |
|---|---|---|
| 数据模型 | 图结构:以“节点-关系-属性”为核心,直接表示实体间的复杂关系。 | 表结构:基于二维表格,通过主键和外键间接表示关系,关系需通过 JOIN 操作查询。 |
| 查询方式 | 图遍历:通过关系直接跳转(如查找朋友的朋友),适合深度关联查询。 | 表连接:依赖 JOIN 操作,多层级关联查询效率较低(如递归查询)。 |
| 适用场景 | 社交网络、推荐系统、欺诈检测、知识推理等高度关联的数据场景。 | 交易系统、报表统计、结构化数据管理等事务型场景。 |
| 查询语言 | 图查询语言(如Cypher、SPARQL、Gremlin),支持路径查询和模式匹配。 | SQL(结构化查询语言),擅长聚合计算和表间关联。 |
| 性能特点 | 关系查询高效:深度关系查询复杂度为 O(1) ~ O(n),与数据量无关。 | 简单查询高效:主键查询快,但多表 JOIN 或递归查询复杂度高(O(n²) 或更高)。 |
| 扩展性 | 水平扩展较难(图数据库通常以单机为主),但支持垂直扩展。 | 容易水平扩展(分库分表),适合大规模分布式存储。 |
| 数据复杂度 | 天然支持动态模式(可随时新增节点类型或关系类型)。 | 依赖固定模式(需预先定义表结构),修改模式成本高。 |
| 可视化能力 | 内置图可视化工具,直观展示节点和关系网络。 | 需借助外部工具(如BI软件)实现可视化。 |
| ACID支持 | 部分支持(如Neo4j支持ACID),但分布式图数据库可能弱化一致性。 | 强ACID支持(如MySQL),保证事务一致性。 |
| 存储结构 | 以图的方式存储,节点和关系独立存储,关系为一等公民。 | 以行或列存储,关系通过外键隐式表达。 |
| 典型应用 | - 社交网络(好友推荐) - 反欺诈(识别异常路径) - 知识库(如医疗诊断推理) | - 银行交易系统 - 电商订单管理 - 企业ERP系统 |
| 示例查询 | 查找用户A的3度好友(朋友的朋友的朋友):MATCH (A)-[:FRIEND*3]->(B) | 查找用户的订单详情:SELECT * FROM Users JOIN Orders ON Users.id = Orders.user_id; |
场景:社交网络分析
| 需求 | 知识图谱实现 | 传统数据库实现 |
|---|---|---|
| 查询“用户A的3度好友” | 1行Cypher查询:MATCH (u:User)-[:FRIEND*1..3]-(f:User) WHERE u.name="A" RETURN f | 需多层JOIN或递归查询,效率低且代码复杂。 |
| 分析“哪些用户是多个群组的桥梁” | 使用图算法(如Betweenness Centrality)直接计算节点重要性。 | 需手动统计用户所属群组并计算交集,难以规模化。 |
场景:电商推荐
| 需求 | 知识图谱实现 | 传统数据库实现 |
|---|---|---|
| 推荐“购买手机的用户可能需要的兼容配件” | 遍历“手机-兼容-配件”关系链,动态扩展推荐结果。 | 依赖人工规则(如“同一品类”),无法自动发现隐性关联。 |
| 识别“虚假评论团伙” | 构建“用户-评论-商品-IP地址”图谱,发现多个用户通过同一IP或设备关联。 | 需分别查询用户、IP、设备表并手动关联,难以发现复杂模式。 |
总结:知识图谱的核心优势
-
复杂关系处理
适合多层级、网状关系场景(如社交网络、供应链追踪)。 -
动态语义扩展
灵活适应业务变化(如新增“电影系列”“拍摄地”关系)。 -
隐性知识发现
通过图算法(社区检测、路径分析)挖掘潜在模式。
总结选择建议:
-
选知识图谱数据库:
-
需要频繁查询多层级关系(如社交网络、路径分析)。
-
数据模式灵活多变,或需要动态添加实体类型和关系。
-
知识图谱的核心价值在于 将数据转化为可探索、可推理的知识网络
-
-
选传统关系型数据库:
-
数据高度结构化,以事务处理(OLTP)为主。
-
需要强一致性、高并发写入(如金融交易系统)。
-
传统数据库更擅长高效处理结构化事务
-
-
混合使用:
复杂系统可结合两者,例如用关系型数据库存储核心业务数据,用知识图谱处理关联分析。


















 1033
1033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











