







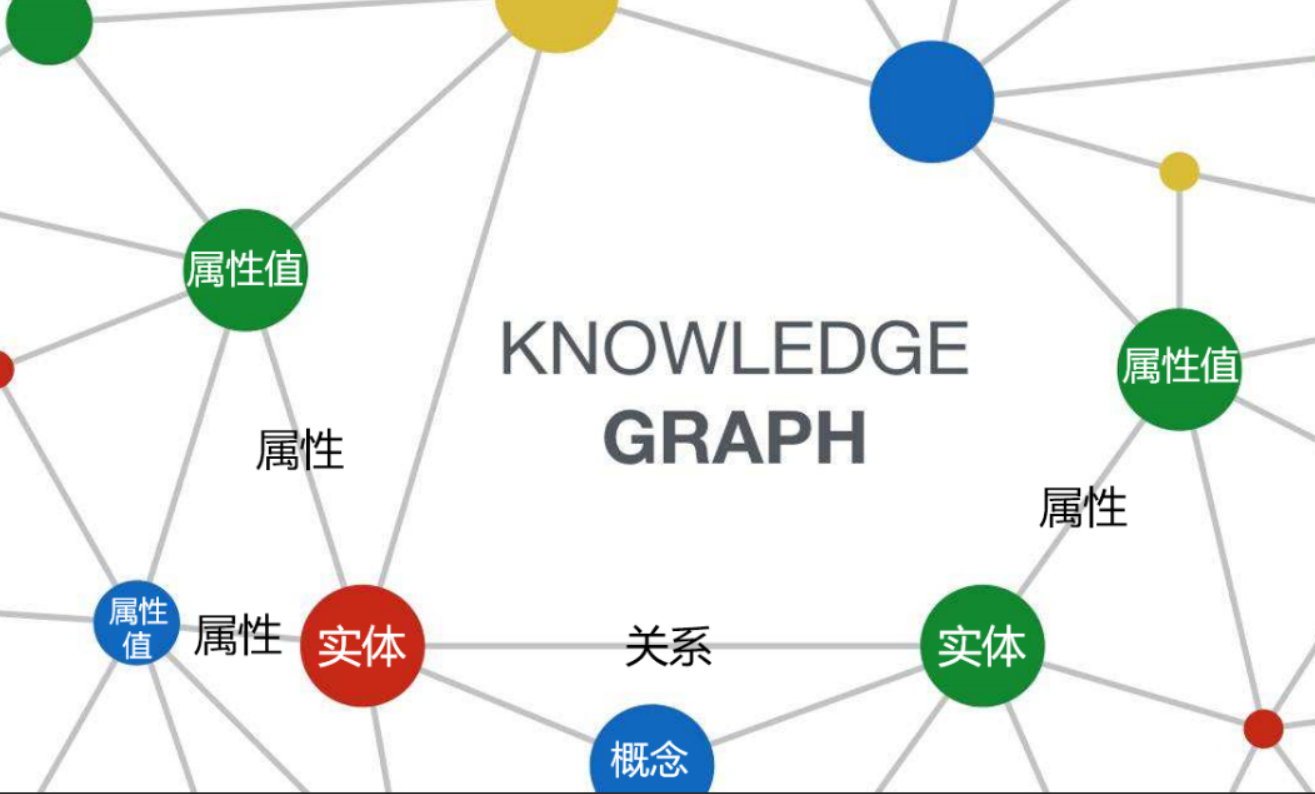
什么是知识图谱
知识图谱(Knowledge Graph)是一种用图结构表示知识和关系的技术,通过节点(实体)和边(关系)构建语义网络,旨在将分散的数据转化为机器可理解、可推理的知识体系。其核心目标是解决数据的 语义关联 和 复杂关系推理 问题。节点代表实体(如人物、地点、事件),边表示实体间的关系(如“出生于”“属于”)。
国内的一些知名学者也给出了关于知识图谱的定义。这里简单列举了几个。
电子科技大学的刘峤教授给出的定义是:
知识图谱,是结构化的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系,其基本组成单位是“实体–关系–实体”三元组,以及实体及其相关属性–值对,实体之间通过关系相互联结,构成网状的知识结构。
清华大学的李涓子教授给出的定义是:
知识图谱以结构化的方式描述客观世界中概念、实体及其关系,将互联网的信息表示成更接近人类认知世界的形式,提供了一种更好地组织、管理和理解互联网海量信息的能力。
浙江大学的陈华钧教授对知识图谱的理解是:
知识图谱旨在建模、识别、发现和推断事物、概念之间的复杂关系,是事物关系的可计算模型,已经被广泛应用于搜索引擎、智能问答、语言理解、视觉场景理解、决策分析等领域。
东南大学的漆桂林教授给出的定义是:
知识图谱本质上是一种叫作语义网络的知识库,即一个具有有向图结构的知识库,其中图的结点代表实体或者概念,而图的边代表实体/概念之间的各种语义关系。
核心要素
| 要素 | 描述 |
|---|---|
| 实体 | 现实世界中的对象(如“姚明”“上海”“《盗梦空间》”)。 |
| 关系 | 实体间的语义联系(如“出生于”“导演是”“属于类型”)。 |
| 属性 | 实体或关系的附加信息(如“姚明”的“身高”为2.29米)。 |
| 本体 | 定义实体、关系、属性的类型和约束规则(如“导演”只能关联“电影”实体)。 |
关键特征
-
语义化:通过关系赋予数据实际含义(如“A 是 B 的子公司”)。
-
结构化:数据以图形式存储,支持多跳关系查询。
-
可推理:基于规则或机器学习推断隐含知识(如“若A是B的母公司,B位于C国,则A在C国可能有分支机构”)。
-
动态扩展:可灵活添加新实体、关系,无需重构全局模式。
传统关系型数据库与知识图谱的场景对比
假设我们需要构建一个电影推荐系统,支持以下需求:
-
用户搜索《盗梦空间》时,推荐“同导演的其他电影”和“主演参演的其他类型电影”。
-
分析“哪些演员经常与科幻片导演合作”。
传统关系型数据库(如MySQL)的局限性
-
复杂查询需要多次JOIN
-
查询“《盗梦空间》导演的其他作品”需要多表关联:
SELECT m.title FROM movies m JOIN directors d ON m.director_id = d.id WHERE d.name = 'Christopher Nolan';
-
查询“主演参演的其他类型电影”需要更多JOIN:
SELECT m.title FROM actors a JOIN movie_actor ma ON a.id = ma.actor_id JOIN movies m ON ma.movie_id = m.id WHERE a.name = 'Leonardo DiCaprio' AND m.genre != 'Sci-Fi';
-
问题:表结构固定,深层关系查询效率低,难以扩展。
-
-
难以处理隐性关系
-
若想分析“演员A是否经常与某类导演合作”,需手动关联导演类型、演员合作记录等,无法直接通过图遍历发现模式。
-
-
缺乏语义理解
-
无法自动推断“合作次数≥3次的演员→导演”可能形成稳定团队。
-
知识图谱的优势
-
高效的多跳查询
用图查询语言(如Cypher)直接遍历关系:// 查询《盗梦空间》导演的其他作品 MATCH (m:Movie {title: "Inception"})<-[:DIRECTED]-(d:Director)-[:DIRECTED]->(other:Movie) RETURN other.title; // 查询主演参演的非科幻片 MATCH (a:Actor {name: "Leonardo DiCaprio"})-[:ACTED_IN]->(m:Movie) WHERE m.genre <> 'Sci-Fi' RETURN m.title;-
优势:无需多表JOIN,直接通过图遍历获取结果,性能更高。
-
-
发现隐性关系
// 分析“经常与科幻导演合作的演员” MATCH (d:Director)-[:DIRECTED]->(m:Movie {genre: "Sci-Fi"}), (d)-[:DIRECTED]->(m2:Movie)<-[:ACTED_IN]-(a:Actor) WITH a, COUNT(DISTINCT d) AS directorCount WHERE directorCount >= 2 RETURN a.name, directorCount;-
输出:返回与≥2位科幻导演合作过的演员。
-
-
支持语义推理
-
定义规则:“若演员与导演合作≥3次,则关系强化为
长期合作”。 -
系统可自动标记这类关系,用于推荐或分析。
-
-
动态扩展能力
-
新增关系类型(如“获奖情况”“电影系列”)无需修改全局结构:
MATCH (m:Movie {title: "Inception"}) CREATE (m)-[:PART_OF_SERIES]->(:Series {name: "Nolan Sci-Fi"});
-
实际应用案例
案例1:医疗诊断辅助系统
-
传统方式:基于关键词匹配病历和药品数据库,可能忽略症状间的关联(如“头痛+发烧→脑膜炎”)。
-
知识图谱应用:
-
构建“症状-疾病-药品-副作用”图谱。
-
输入患者症状后,自动遍历可能的疾病路径,并排除禁忌药(如患者有肝病→避免使用某类药物)。
-
结果:诊断建议更精准,减少误诊风险。
-
案例2:金融反欺诈
-
传统方式:规则引擎检查单笔交易(如“单日转账超5万”)。
-
知识图谱应用:
-
构建“用户-账户-交易-地理位置”图谱。
-
发现隐性模式(如多个账户通过中间人关联,资金流向同一目标账户)。
-
结果:识别洗钱网络,而不仅是单次异常交易。
-
案例3:电商推荐
-
传统方式:基于用户历史购买推荐相似商品(如“买了手机→推荐耳机”)。
-
知识图谱应用:
-
构建“用户-商品-品牌-使用场景”图谱。
-
推荐逻辑:“用户买了露营帐篷→推荐与该品牌帐篷兼容的防潮垫(通过商品兼容关系),以及同用户群体常买的户外灯具(通过群体行为分析)”。
-
结果:推荐结果更具多样性和逻辑性。
-
为什么需要知识图谱?总结
-
复杂关系查询
当业务需求涉及多层级关系(如“朋友的朋友”“上下游供应链”)时,图遍历效率远高于关系型数据库。 -
动态关系与隐性模式
知识图谱适合需要动态添加关系类型(如社交网络中的新互动方式)或挖掘潜在关联(如反欺诈中的隐藏网络)的场景。 -
语义理解与推理
通过本体(Ontology)定义实体关系的语义,支持逻辑推理(如“子公司位于欧盟→需遵守GDPR”)。 -
数据融合
整合多源异构数据(如合并CRM系统中的客户数据和社交媒体行为数据),消除数据孤岛。
何时选择知识图谱?
-
✅ 需要处理多跳关系、动态扩展或关系推理。
-
✅ 数据天然成图(社交网络、供应链、生物基因通路)。
-
❌ 仅需简单键值查询或事务处理时,传统数据库更合适。
通过知识图谱,能将分散的数据转化为可推理、可探索的语义网络,这是传统数据库无法替代的核心价值。


















 1809
1809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











