



个人记录过程用,全是个人理解,有问题欢迎指出。
一、metadata.json获取
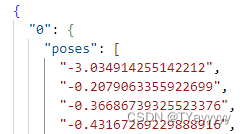
humannerf想要得到的:
{
// Replace the string item_id with your file name of video frame.
"item_id": {
// A (72,) array: SMPL coefficients controlling body pose.
"poses": [
-3.1341, ..., 1.2532
],
// A (10,) array: SMPL coefficients controlling body shape.
"betas": [
0.33019, ..., 1.0386
],
// A 3x3 camera intrinsic matrix.
"cam_intrinsics": [
[23043.9, 0.0,940.19],
[0.0, 23043.9, 539.23],
[0.0, 0.0, 1.0]
],
// A 4x4 camera extrinsic matrix.
"cam_extrinsics": [
[1.0, 0.0, 0.0, -0.005],
[0.0, 1.0, 0.0, 0.2218],
[0.0, 0.0, 1.0, 47.504],
[0.0, 0.0, 0.0, 1.0],
],
}
...
// Iterate every video frame.
"item_id": {
...
}
}
问一下GPT
相机内参矩阵(Camera Intrinsic Matrix):
含义: 相机内参矩阵描述了相机的内部特性,例如焦距、光学中心和畸变等。这些参数是相机固有的,不受相机在空间中的位置和朝向的影响。
表示: 通常是一个3x3的矩阵,形如:
[ fx 0 cx ]
[ 0 fy cy ]
[ 0 0 1 ]
其中,fx和fy是焦距,cx和cy是光学中心的坐标。
相机外参矩阵(Camera Extrinsic Matrix):
含义: 相机外参矩阵描述了相机在世界坐标系中的位置和方向。它表示了相机相对于世界坐标系的位姿,包括平移和旋转。
表示: 通常是一个4x4的矩阵,形如:
[ R11 R12 R13 Tx ]
[ R21 R22 R23 Ty ]
[ R31 R32 R33 Tz ]
[ 0 0 0 1 ]
其中,R11到R33表示旋转矩阵的元素,Tx、Ty和Tz表示平移。
1.使用vibe得到基础数据
得到pkl数据,搞半天原来是不能用pickle,得用joblib来读取,网上随便找个使用joblib的pkl读取的代码,读取数据看看里面的格式是个什么样的。
发现论文也写了pkl格式,贴一下
>>> import joblib # you may use native pickle here as well
>>> output = joblib.load('output/group_dance/vibe_output.pkl')
>>> print(output.keys())
dict_keys([1, 2, 3, 4]) # these are the track ids for each subject appearing in the video
>>> for k,v in output[1].items(): print(k,v.shape)
pred_cam (n_frames, 3) # weak perspective camera parameters in cropped image space (s,tx,ty)
orig_cam (n_frames, 4) # weak perspective camera parameters in original image space (sx,sy,tx,ty)
verts (n_frames, 6890, 3) # SMPL mesh vertices
pose (n_frames, 72) # SMPL pose parameters
betas (n_frames, 10) # SMPL body shape parameters
joints3d (n_frames, 49, 3) # SMPL 3D joints
joints2d (n_frames, 21, 3) # 2D keypoint detections by STAF if pose tracking enabled otherwise None
bboxes (n_frames, 4) # bbox detections (cx,cy,w,h)
frame_ids (n_frames,) # frame ids in which subject with tracking id #1 appears
# 具体格式大概是:
{
“1”:{
“pred_cam”:[[3],[ , , ]],
“orig_cam”:[[4],[ , , , ]],
“verts”:[[[3],[ , , ]],[[ , , ],[ , , ]],[[ , , ],[ , , ]]……],
“pose”:[[72],[72],……], # 直接使用
“betas”:[[10],……], # 直接使用
“joints3d”:[[[3],]],
“joints2d”:null,
“bboxes”:[[4],]
“frame_ids”:[]
}
}
pose和betas可以直接使用,cam_intrinsics和cam_extrinsics得到方法如下。(ps:最好使用vibe,有bbox。romp没有bbox。)
# Hello,
# There are multiple ways to get intrinsic and extrinsic camera parameters.
# Here is my recommendation. You might want to use pred_cam and bboxes instead (see the output format of VIBE).
# Let's say you want to access the 1st tracked human.
pred_cam = vibe_result['pred_cam'][0]
bbox = vibe_result['bboxes'][0]
# Use the function below to get the camera parameters.
def get_camera_parameters(pred_cam, bbox):
FOCAL_LENGTH = 5000.
CROP_SIZE = 224
bbox_cx, bbox_cy, bbox_w, bbox_h = bbox
assert bbox_w == bbox_h
bbox_size = bbox_w
bbox_x = bbox_cx - bbox_w / 2.
bbox_y = bbox_cy - bbox_h / 2.
scale = bbox_size / CROP_SIZE
cam_intrinsics = np.eye(3)
cam_intrinsics[0, 0] = FOCAL_LENGTH * scale
cam_intrinsics[1, 1] = FOCAL_LENGTH * scale
cam_intrinsics[0, 2] = bbox_size / 2. + bbox_x
cam_intrinsics[1, 2] = bbox_size / 2. + bbox_y
cam_s, cam_tx, cam_ty = pred_cam
trans = [cam_tx, cam_ty, 2*FOCAL_LENGTH/(CROP_SIZE*cam_s + 1e-9)]
cam_extrinsics = np.eye(4)
cam_extrinsics[:3, 3] = trans
return cam_intrinsics, cam_extrinsics
# I hope this helps. Let me know if you still have any questions.
2.进行处理
写个代码转成要求的json格式,将metadata.json文件放入dataset/wild/monocular中。
运行
cd tools/prepare_wild
python prepare_dataset.py --cfg wild.yaml
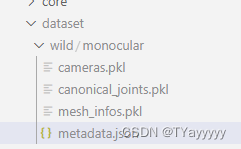
至此得到
二、frame获取
没什么难度,把视频的每帧单独保存就行,放在dataset/wild/monocular/images,要保证images和masks中的图片每帧的命名和metadata.json中的item_id是一样的,不然会报。我直接是从0开始。
KeyError:Caught KeyError in Dataloader worker process 0.
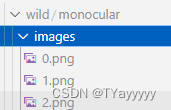
三、mask获取
同上,放在dataset/wild/monocular/masks。DIS跑了下得到的结果一般,勉强用用。得到的效果都挺一般的,不像humannerf例子里面自带的那种边界分明的mask。不了解分割,不知道是相机分辨率太好了,还是特地精抠的一组数据。

四、运行
这时候文件夹的格式为
-humannerf
|--dataset
|--wild
|--monocular
|--images
|-包含n张视频每帧图片
|--masks
|-包含n张视频每帧人物蒙版
|-metadata.json
|-cameras.pkl # 为上面两步使用prepare_dataset.py通过metadeta.json生成
|-canonical_joints.pkl # 为上面两步使用prepare_dataset.py通过metadeta.json生成
|-mesh_infos.pkl # 为上面两步使用prepare_dataset.py通过metadeta.json生成
|-train.py
直接运行
python train.py --cfg configs/human_nerf/wild/monocular/single_gpu.yaml
在跑了,祝我好运
————废弃,不用看。文章修改前的部分————
orig_cam
VIBE中代码的位置:\lib\utils\demo_utils.py
def convert_crop_cam_to_orig_img(cam, bbox, img_width, img_height):
'''
Convert predicted camera from cropped image coordinates
to original image coordinates
:param cam (ndarray, shape=(3,)): weak perspective camera in cropped img coordinates
:param bbox (ndarray, shape=(4,)): bbox coordinates (c_x, c_y, h)
:param img_width (int): original image width
:param img_height (int): original image height
:return:
'''
cx, cy, h = bbox[:,0], bbox[:,1], bbox[:,2]
hw, hh = img_width / 2., img_height / 2.
sx = cam[:,0] * (1. / (img_width / h))
sy = cam[:,0] * (1. / (img_height / h))
tx = ((cx - hw) / hw / sx) + cam[:,1]
ty = ((cy - hh) / hh / sy) + cam[:,2]
orig_cam = np.stack([sx, sy, tx, ty]).T
return orig_cam
Conversion Script from SPIN code base to Metadata parameters in Human Nerf!
From VIBE, ROMP, you get weak perspective camera model (s, tx, ty ),
convert that to the extrinsic ( tx, ty, tz ) while the Rotation part remains np.eye(3).
Next use the intrinsic parameters given in the VIBE, ROMP,
with cx and Cy as your image centers and focal length ( check their config file )
def convert_weak_perspective_to_perspective(
weak_perspective_camera,
focal_length=5000.,
img_res=224,
):
# Convert Weak Perspective Camera [s, tx, ty] to camera translation [tx, ty, tz]
# in 3D given the bounding box size
# This camera translation can be used in a full-perspective projection
perspective_camera = np.stack(
[
weak_perspective_camera[1],
weak_perspective_camera[2],
# focal_length焦距,VIBE默认配置5000。img_res分辨率,可自定义,最好512或者1080.
2 * focal_length / (img_res * weak_perspective_camera[0] + 1e-9)
],
axis=-1
)
return perspective_camera
Then the extrinsic parameters will be:
E = [[1, 0, 0, tx],
[0, 1, 0, ty],
[0, 0, 1, tz],
[0, 0, 0, 1]]


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









