




一、简介
我们之前已经掌握了很多关于和LLM交互的操作了,现在我们需要在这些操作上面构建自己的机器人,进而在客户端操作服务。
我们需要使用的工具是streamlit
你就把他理解为python的uniapp吧。
二、开发环境准备
我们这次是真实的操作代码了,所以就不用jupyter这种交互式的开发了。我们用pycharm这种ide来开发。
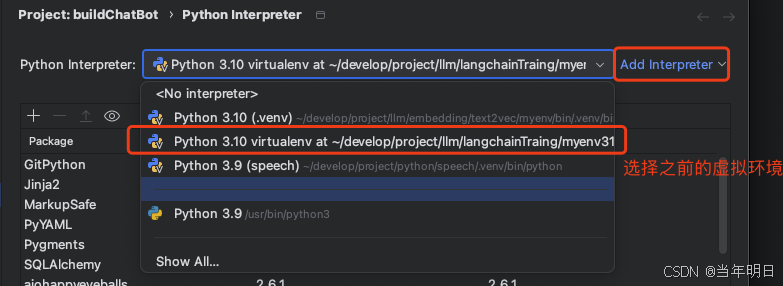
1、创建项目,选择虚拟环境
我们创建一个project,继续选择之前的虚拟环境。
操作方式其实我在使用text2vec向量化文本一文中谈到过,这里再复述一遍。
我们之前在vscode中写的时候创建了一个虚拟环境venv3110。我们用pycharm打开项目之后点击seeting->project->project Interpreter
2、安装streamlit依赖
我们需要安装一下对应的依赖。你可以在终端进入你的虚拟环境
source 你的虚拟环境路径/bin/activate
在虚拟环境下执行
pip3 install streamlit
或者是
pip install streamlit
取决于你是不是用的python3
pip list 检查你的安装包
也可以在ide中安装。
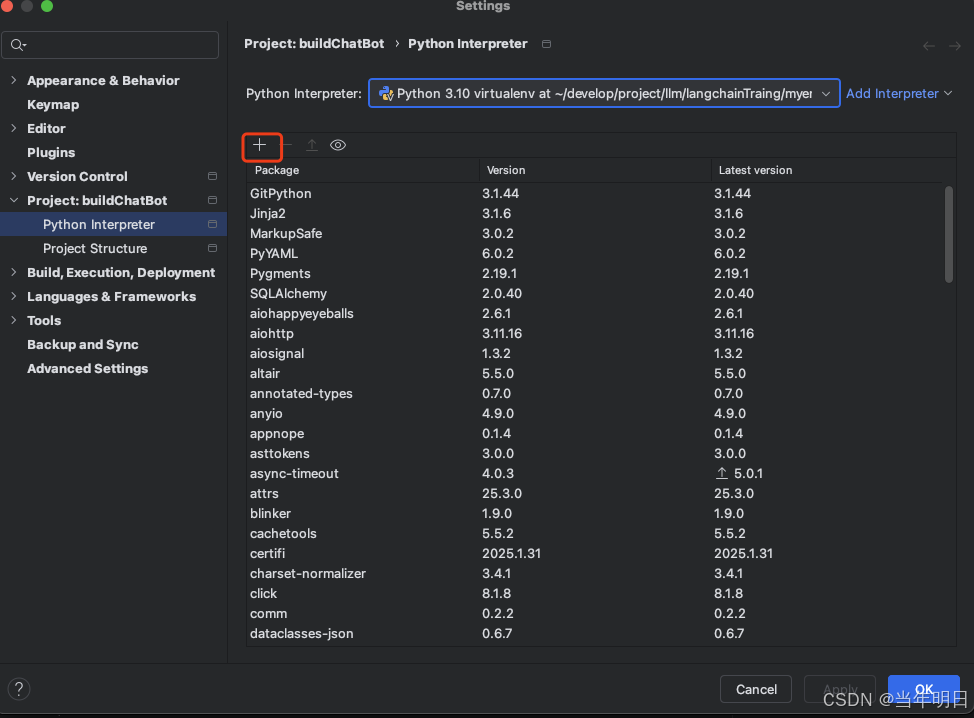
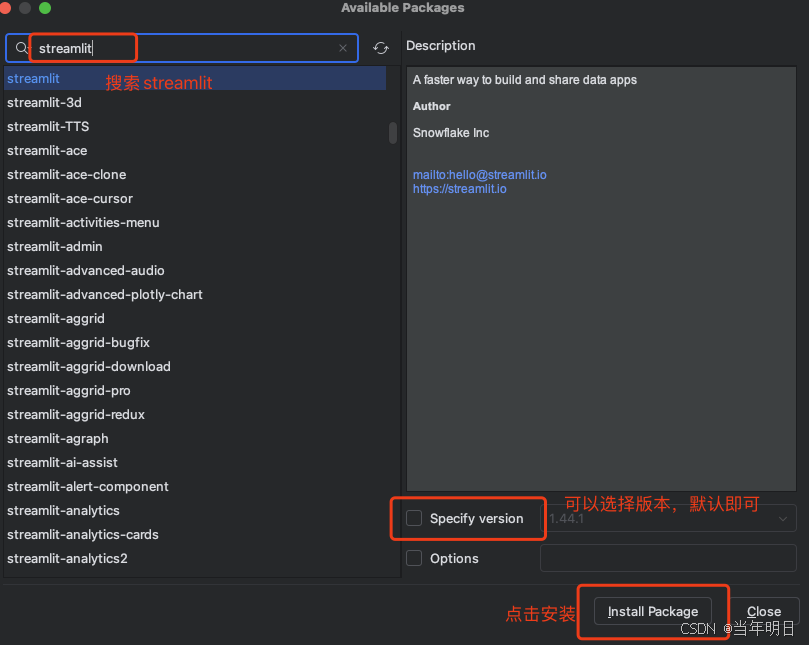
然后安装好的就可以在列表中看到了。
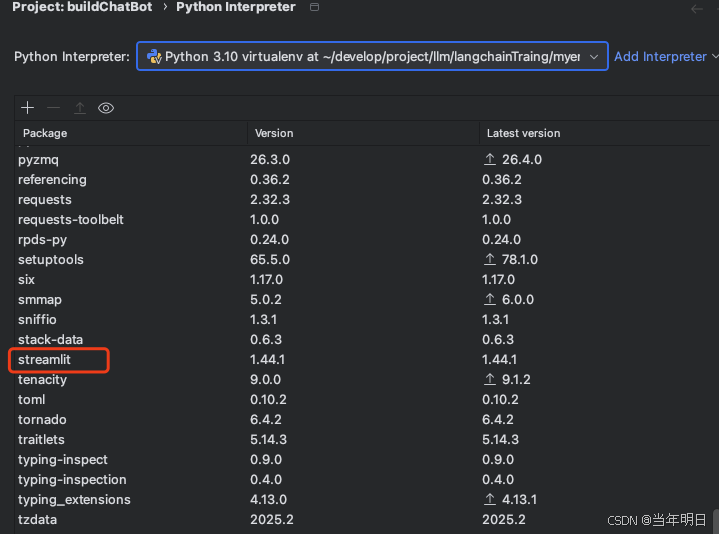
此时我们的项目结构就很简单,两个文件。一个python文件,一个.env文件存储环境变量。
至此我们完成了环境的准备。
三、使用streamlit实现交互
我们依然引入之前的那些依赖包,只不过这次要多一个streamlit,并且记得启动es和ollama。
chatBot.py
from dotenv import load_dotenv
from langchain_ollama import ChatOllama
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ElasticsearchChatMessageHistory
from streamlit import streamlit as st
# load env file
load = load_dotenv("./.env")
# init llm
llm = ChatOllama(
base_url = "http://127.0.0.1:11434",
model = "deepseek-r1:8b",
temperature = 0.5,
num_predict = 10000,
max_tokens = 250
)
# streamlit的一个标题
st.title("哥哥你好,这里是橘子GPT,我是小橘?")
st.write("哥哥,请把您的问题输入,小橘会认真回答的哦。")
# 无密码的elasticsearch配置
es_url = "http://local 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2125
2125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









