




我们在上一篇文章中提到了我们可以使用langsmith来监控我们自己的模型。那么我们本文就来操作一把。
一、配置langsmith
首先我们要登陆进来官方网址。你可以用你的github账号登陆。
然后我们可以看到他的主页。
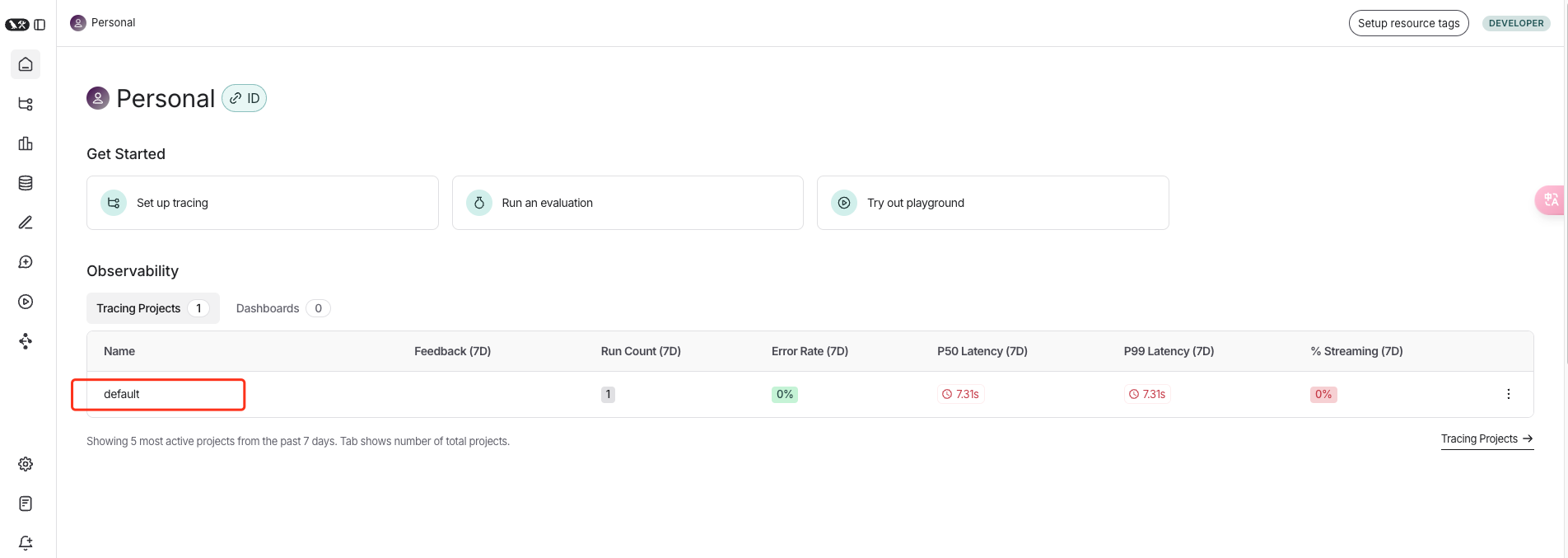
他已经有了一个内置的项目,我们不需要他的,我们自己创建自己的。

接下来我们就看到配置信息的地方。你能看到他可以选择是不是langchain项目,可见他是支持非langchain的监控的,还是挺厉害的。
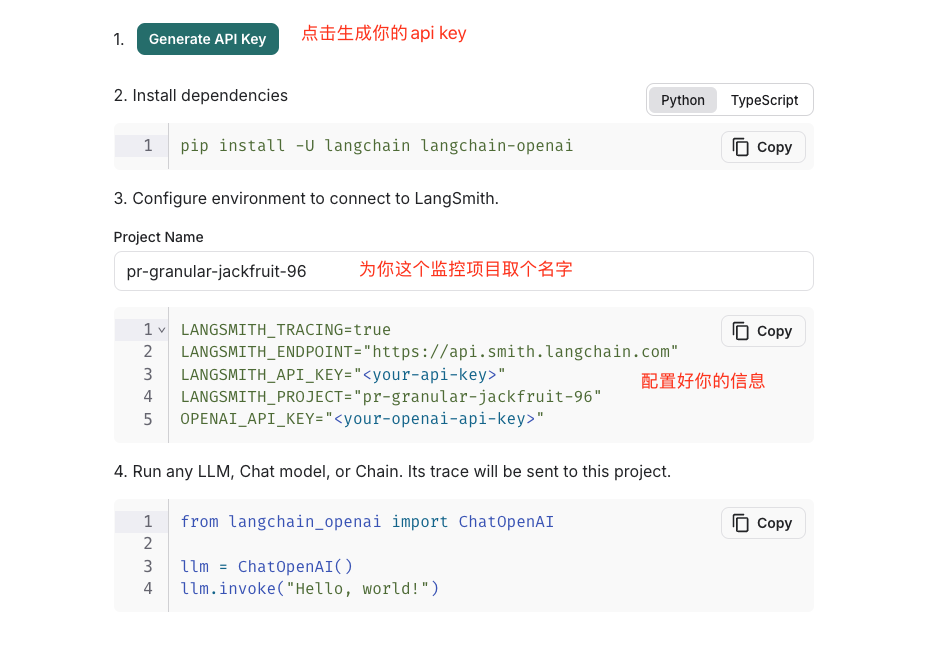
二、提供langsmith和langchain的关联
当我们都填写完的时候,那个配置信息的文本框就自动填充了对应的信息如下:
LANGSMITH_TRACING=true # 表示我们添加的是对langchain的监控
LANGSMITH_ENDPOINT="https://api.smith.langchain.com" # 我们这个监控项目暴露出来的端点地址
LANGSMITH_API_KEY="lsv2_pt_xxxxxxxbc8725973_6xxxxxxx148f" # 我们生成的key
LANGSMITH_PROJECT="x 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3487
3487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









