







 本文详细介绍了Spark中的RDD持久化、缓存和CheckPoint,强调了它们在优化计算过程中的作用。此外,还探讨了广播变量和累加器这两种共享变量的使用和优势。最后,深入讨论了Spark的DAG调度,包括Job、DAG、Stage划分以及内存迭代计算,为读者提供了Spark内核调度的全面理解。
本文详细介绍了Spark中的RDD持久化、缓存和CheckPoint,强调了它们在优化计算过程中的作用。此外,还探讨了广播变量和累加器这两种共享变量的使用和优势。最后,深入讨论了Spark的DAG调度,包括Job、DAG、Stage划分以及内存迭代计算,为读者提供了Spark内核调度的全面理解。
传送门:
- 视频地址:黑马程序员Spark全套视频教程
- 1.PySpark基础入门(一)
- 2.PySpark基础入门(二)
- 3.PySpark核心编程(一)
- 4.PySpark核心编程(二)
- 5.PySaprk——SparkSQL学习(一)
- 6.PySaprk——SparkSQL学习(二)
- 7.Spark综合案例——零售业务统计分析
- 8. Spark3新特性及核心概念(背)
一、RDD持久化
1.RDD的数据是过程数据
RDD之间进行相互迭代计算(Transformation的转换),当执行开启后,新RDD的生成,代表老RDD的消失。RDD的数据是过程数据,只在处理的过程中存在。一旦处理完成,就不见了。
这个特性可以最大化的利用资源,老旧RDD没用了就从内存中清理,给后续的计算腾出内存空间。
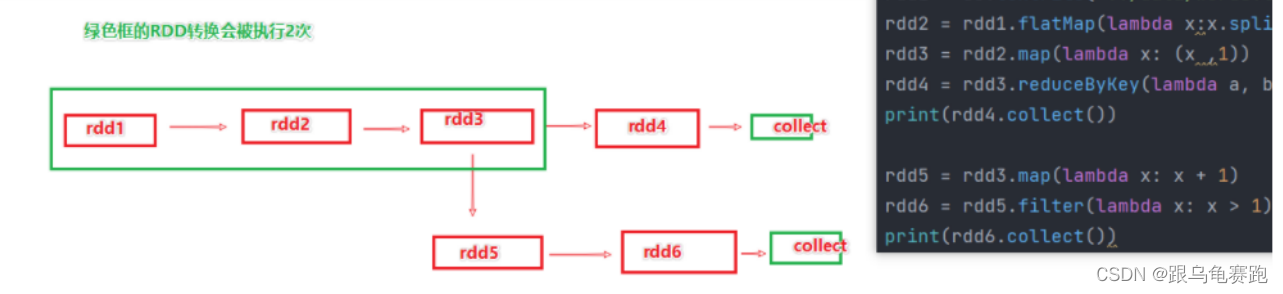
如上图,rdd3被2次使用,第一次使用之后,其实RDD3就不存在了
第2次用的时候,只能基于RDD的血缘关系,从RDD1重新执行,构建出RDD3,供RDD5使用
2.RDD缓存
上述的场景肯定要执行优化,优化就是:RDD3如果不消失,那么RDD1→RDD2→RDD3,这个链条就不会执行2次,或者更多次。此时,用到了RDD的缓存技术。RDD的缓存技术: Spark提供了缓存API,可以让我们通过调用API,将指定的RDD数据保留在内存或者硬盘上。
缓存API:

2.1 RDD缓存的特点
-
缓存技术可以将过程RDD数据,持久化保存到内存或者硬盘上(分散存储——保存在多个服务器的内存空间与硬盘空间中)
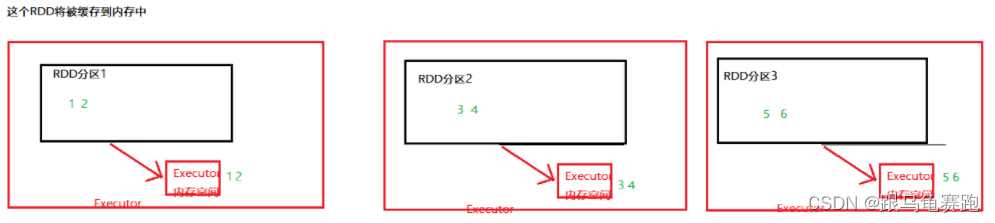
-
但是,这个保存在设定上是认为不安全的。
缓存的数据在设计上是认为有丢失风险的。所以,一旦缓存丢失,可以基于RDD的血缘关系记录,重新计算这个RDD数据。缓存必须保留被缓存RDD的前置"血缘关系"。
缓存如何丢失:
➊在内存中的缓存是不安全的, 比如断电\计算任务内存不足,把缓存清理给计算让路
➊硬盘中因为硬盘损坏也是可能丢失的.
2.2 cache()与unpersist()实战
#!usr/bin/env python
# -*- coding:utf-8 -*-
from pyspark import SparkConf, SparkContext
import time
if __name__ == '__main__':
# 1.构建SparkContext对象
conf = SparkConf().setAppName('creat rdd').setMaster('local[*]')
sc = SparkContext(conf=conf)
rdd1 = sc.textFile('../data/input/words.txt')
rdd2 = rdd1.flatMap(lambda x: x.split(' '))
rdd3 = rdd2.map(lambda x: (x, 1))
# 缓存到内存中
rdd3.cache()
rdd4 = rdd3.reduceByKey(lambda a, b: a + b)
print(rdd4.collect())
rdd5 = rdd3.groupByKey()
rdd6 = rdd5.mapValues(lambda x : sum(x))
print(rdd6.collect())
# 主动清理缓存
rdd3.unpersist()
[('hadoop', 1), ('hello', 3), ('spark', 1), ('flink', 1)]
[('hadoop', 1), ('hello', 3), ('spark', 1), ('flink', 1)]
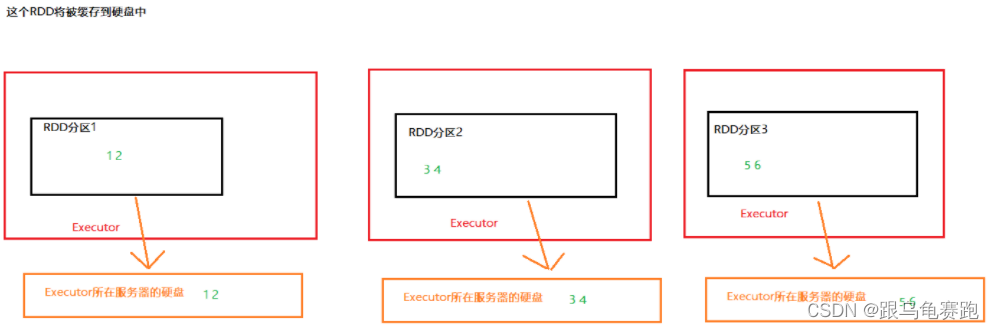
3.RDD CheckPoint
CheckPoint技术,也是将RDD的数据保存起来。但是,它仅支持硬盘存储。并且:
- 被设计认为是安全的
- 不保留血缘关系
这个RDD数据将被CheckPoint到HDFS中
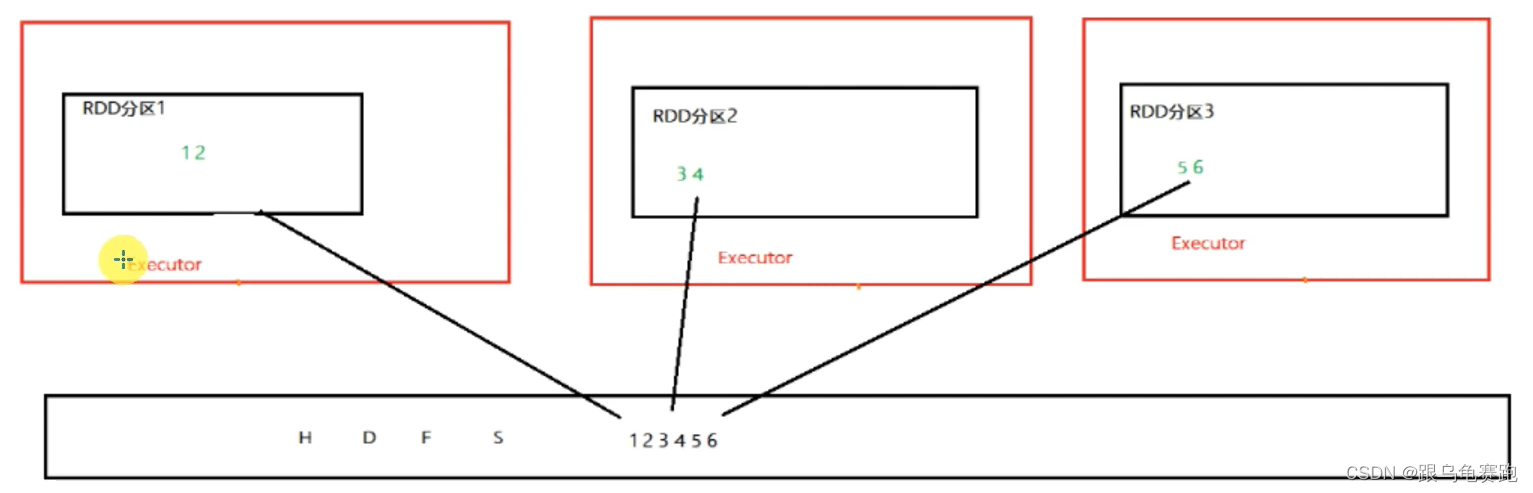
对比缓存,CheckPoint的RDD数据保存是集中收集存储。如图,CheckPoint存储RDD数据,是集中收集各个分区数据进行存储,而缓存是分散存储。
注意:
- CheckPoint是一种重量级的使用,也就是RDD的重新计算成本很高的时候,我们采用CheckPoint比较合适。或者数据量很大,用CheckPoint比较合适。如果数据量小,或者RDD重新计算是非常快,用CheckPoint没啥必要,直接缓存即可。
- Cache和CheckPoint两个API都不是Action类型。所以,想要它俩工作,必须在后面接上Action。接上Action的目的,是让RDD有数据,而不是为了让checkPoint和cache工作。
3.1 CheckPoint和缓存的对比
- CheckPoint不管分区数量多少,风险是一样的,缓存分区越多,风险越高
- CheckPoint支持写入HDFS,缓存不行, HDFS是高可靠存储,CheckPoint被认为是安全的。
- CheckPoint不支持内存,缓存可以,缓存如果写内存性能比CheckPoint要好一些
- CheckPoint因为设计认为是安全的,所以不保留血缘关系,而缓存因为设计上认为不安全,所以保留血缘关系
3.2 CheckPoint算子实战

#!usr/bin/env python
# -*- coding:utf-8 -*-
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
# 1.构建SparkContext对象
conf = SparkConf().setAppName('creat rdd').setMaster('local[*]')
sc = SparkContext(conf=conf)
# 2.告知Spark,开启Checkpoint功能
sc.setCheckpointDir('hdfs://node1:8020/test/output/ckp')
rdd1 = sc.textFile('../data/input/words.txt')
rdd2 = rdd1.flatMap(lambda x: x.split(' '))
rdd3 = rdd2.map(lambda x: (x, 1))
# 调用Checkpoint API;保存数据即可
rdd3.checkpoint()
rdd4 = rdd3.reduceByKey(lambda a, b: a + b)
print(rdd4.collect())
rdd5 = rdd3.groupByKey()
rdd6 = rdd5.mapValues(lambda x : sum(x))
print(rdd6.collect())
[('hadoop', 1), ('hello', 3), ('spark', 1), ('flink', 1)]
[('hadoop', 1), ('hello', 3), ('spark', 1), ('flink', 1)]
4.总结
-
Cache和Checkpoint区别
- Cache是轻量化保存RDD数据,可存储在内存和硬盘,是分散存储,设计上数据是不安全的(保留RDD血缘关系)
- CheckPoint是重量级保存RDD数据,是集中存储,只能存储在硬盘(HDFS)上,设计上是安全的(不保留RDD血缘关系)
-
Cache和CheckPoint的性能对比?
Cache性能更好,因为是分散存储,各个Executor并行执行,效率高,可以保存到内存中(占内存),更快。
- CheckPoint比较慢,因为是集中存储,涉及到网络IO,但是存储到HDFS上更加安全(多副本)
二、Spark案例练习
1.搜索引擎日志分析
使用搜狗实验室提供【用户查询日志(SogouQ)】数据,使用Spark框架,将数据封装到RDD中进行业务数据处理分析。
数据格式:下载地址
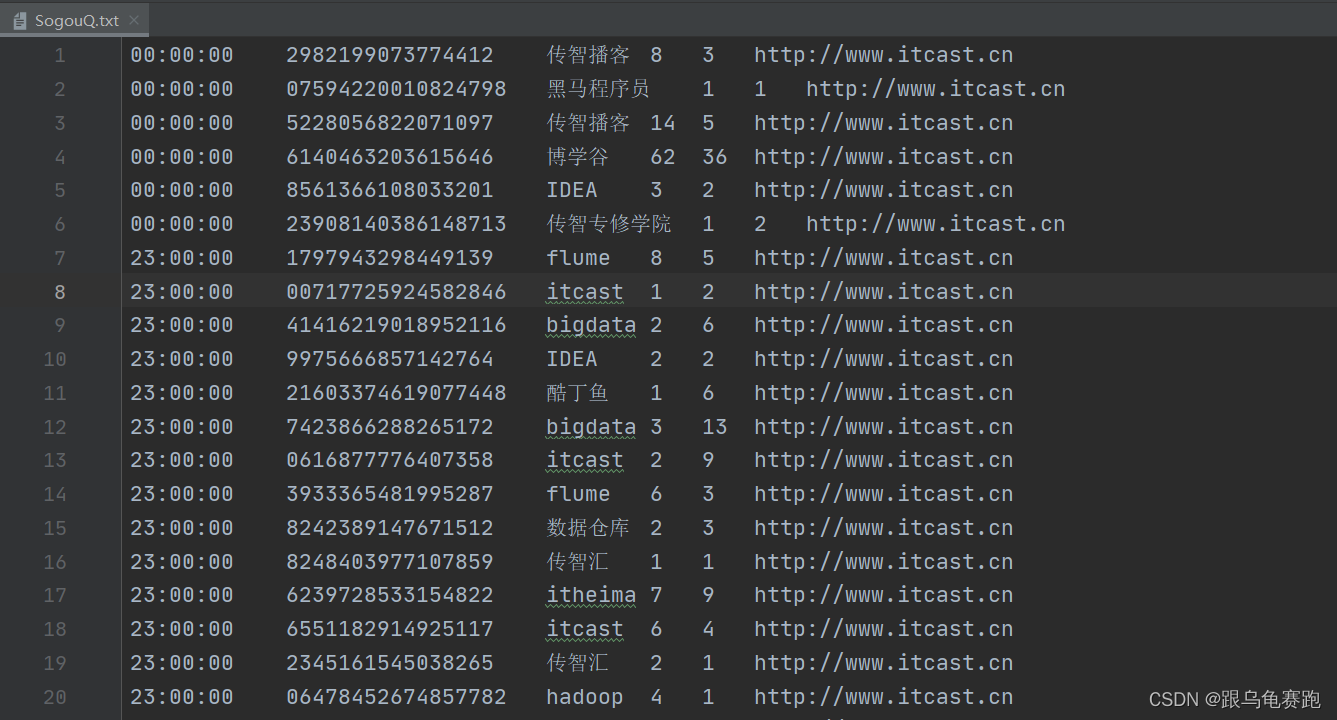
每一列分别为访问时间、用户ID、查询词、该URL在返回结果中的排名、用户点击的顺序号、用户点击的URL
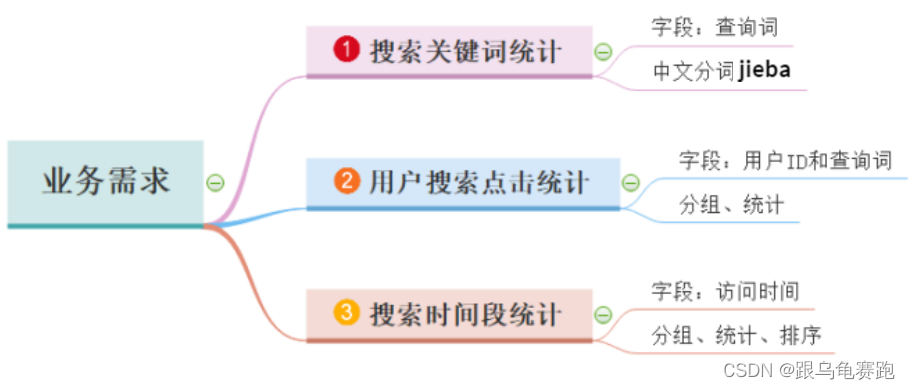
案例需求:三个需求。
- 用户搜索的关键词分析
- 用户和关键词组合分析
- 热门搜索时间段分析
需求一:用户搜索的关键词分析,代码解析:
#!usr/bin/env python
# -*- coding:utf-8 -*-
"""
搜索引擎日志分析
- 用户搜索的关键词分析
- 用户和关键词的组合分析
- 热门搜索时间段分析
"""
import jieba
from pyspark import SparkContext, SparkConf
from pyspark.storagelevel import StorageLevel
from utils import context_jieba, filter_words, transfer_words
if __name__ == '__main__':
# 0.构建SparkContext对象
conf = SparkConf().setAppName(' ').setMaster('local[*]')
sc = SparkContext(conf=conf)
# 1.读取数据文件
file_rdd = sc.textFile('../../data/input/SogouQ.txt')
# 2.对数据按照“\t”进行切分
split_rdd = file_rdd.map(lambda x: x.split('\t'))
# 3.split_rdd作为基础rdd,要多次使用,因此保存在硬盘中
split_rdd.persist(StorageLevel.DISK_ONLY)
# TODO:需求1:用户搜索的关键词分析——主要分析热点词
# 将搜索内容取出来
context_rdd = split_rdd.map(lambda x: x[2])
# 对搜索内容进行分词,得到分词后的结果
words_rdd = context_rdd.flatMap(content_jieba)
# 对分词后的异常内容进行处理——先将不要的过滤掉,再将剩余内容替换成完成的内容
# 将关键词中的谷、帮、客进行过滤掉
filter_rdd = words_rdd.filter(filter_words)
# 将关键词进行替换
final_word_rdd = filter_rdd.map(transfer_words)
# 对单词进行分组、聚合、降序排序,找出前五个热点词
result1 = final_word_rdd.reduceByKey(lambda a, b: a + b). \
sortBy(lambda x: x[1], ascending=False, numPartitions=1).take(5)
print("需求1的结果:", result1)
需求1的结果: [('scala', 2310), ('hadoop', 2268) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2717
2717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











