



开头还是介绍一下群,如果感兴趣PolarDB ,MongoDB ,MySQL ,PostgreSQL ,Redis, Oceanbase, Sql Server等有问题,有需求都可以加群群内有各大数据库行业大咖,可以解决你的问题。加群请联系 liuaustin3 ,(共2280人左右 1 + 2 + 3 + 4 +5) 新人奖直接分配到5群,5群接近400,即将停止自由申请, 已建立6群。

南帝北丐,东邪西毒,中神通,数据库业界,也有MySQL 实战找八怪(高鹏高老师),PostgreSQL 知识找灿灿(熊灿灿,熊总),不服不行,一个重庆,一个成都,四川好地方,数据库人才辈出,这篇文章就是在某群,灿灿偶然对一个问题,泄露的话开始的。
原因是灿总发现了有个同学 KILL -9 POSTGRESQL ID
留下部分原话是 内存问题,优先用sar -B,看direct memory reclaim,杀不掉最后还有gdb ➕exit的方式干,流复制场景下,写入阻塞,多半都是syncrep导致
总结,对于KILL -9 POSTGRESQL ID 深恶痛觉
一句话咱们分析分析几个知识点
1 内存问题,用 sar -B 查看 direct memory reclaim
2 对于PostgreSQL 的进程杀不掉用 gdb的方式处理
3 流复制场景,写入的问题和数据同步有关(强同步)
产生这些知识点的原因是,KILL -9 process id(PostgreSQL process id)

OMG ,KILL -9 PG Process id ,How dare you !
Why ! Do I , Do I ,God Please!
So.....
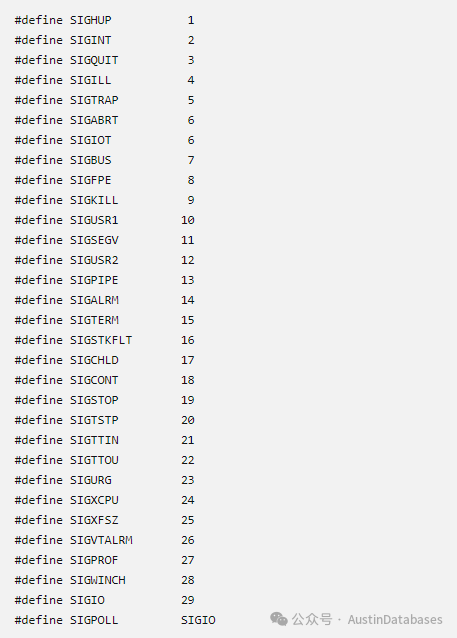
为什么对于PostgreSQL 对于Kill -9 深恶痛绝,或者捅了马蜂窝,这点我们先从LINUX 的信号处理开始,在LINUX 中KILL 后面加数字会发送不同的信号,这里kill -9 也就是下图的 SIGKILL , 发送这个信号后,会发生对于制定的process ID 的进程立即终止它,对于简单的程序是可以接受的,但在实践中很少有“简单的程序”,同时PG 更不是什么简单的程序。
因为程序中会有一些需要进行的事务性的工作,比如终止它前需要进行的清理工作,如关闭资源的句柄,删除临时文件,将内存的数据刷新到磁盘上,等等。那么我们将PostgreSQL 的 process and memory Architecture 的图那出来,我们就可以明白如果我们使用了kill -9 任意的PG的 process id ,会导致如下问题的可能性
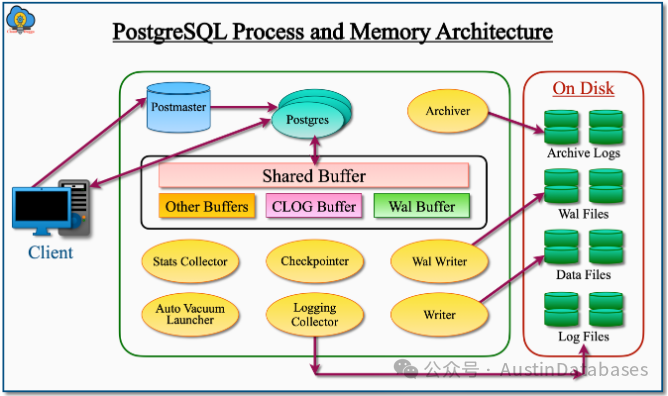
1 数据丢失: 在强制对POSTGRESQL 进行KILL -9 的时候,会发送 abort的信号给PG,PG将认为自己的程序遇到重大的问题,并进行处主进程以外的所有进程的重新初始化。同时在这里众多的客户进程还在访问,那么正在进行的事务由并未完全提交的,导致修改的数据但尚未持久化到磁盘的数据丢失的可能 (如同抢红灯,不是每次都会死,但死一次就够了)
2 事务不完整:由于对于PG的process 是强力终止的,对于客户的运行的事务可能未完成提交或部分提交,在这样的情况下事务的完整性就破坏了,导致一个操作整体后,变得不整体数据库处于数据事务后的不一致状态。
3 数据破坏:在强制终止进程时,数据文件可能在写入数据,或刷新中,KILL -9 将整体的操作破坏,然后你就很可能得到一个逻辑错误的数据文件影响数据库的可用性和数据的完整性。
此时估计有同学提出,咱们不还有WAL日志吗,通过日志将未完成的数据进行REDO 补救总可以吧!

4 火星撞地球,哦不 WAL日志损坏: 强制终止进程,WAL日志也有可能未能正常写入或截断,导致WAL日志的不完整或损坏,进而影响整体数据库的在出现CRASH 后的前滚能力。
好了目前我们已经知道,熊总对于KILL -9 为什么深恶痛绝了。
第一个知识点完成,下一个知识点是,那么我没有办法进入到PG中,我怎么在外部对于PG的一些process进行KILL 。我们稍微 验证一下,打开PG然后对于PG的任意的一个客户的process 进行KILL -9 你就得到所有的PG的子进程都初始化的“奖赏”(下图仅仅KILL一个客户的process后就得到了主子进程的ID号全部和之前不一样的情况)
嗯这是一个好问题,PGER 都知道通过 select pg_terminate_backend(pid) 来进行链接的解除,那么如上我根本就进不去PG内部怎么办? 我也不会什么 sar gdb
那么可以试试,PostgreSQL 的 pg_ctl 命令,是一个宝藏,pg_ctl除了可以开启数据库,关闭数据库,重启数据库,或者promote 数据库,等等,他还有一个 pg_ctl kill 的命令,这个命令本身使用也需要注意,但如果使用不当和kill -9 的功效是一样的,这里这个命令
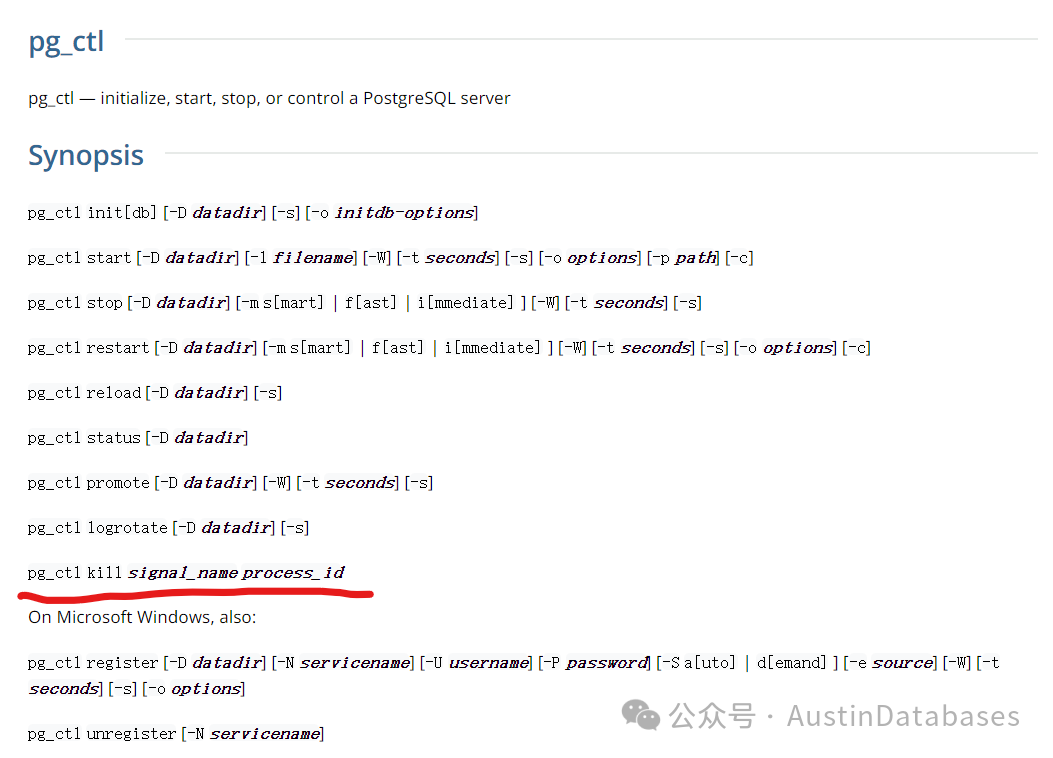
这里的 signal_name 是重要的,这里分别可以使用
ABRT
QUIT
HUP
INT
KILL
TERM
USR1
USR2
以上的信号name 来配合pg_ctl 命令来进行相关的操作。
这里我们可以尝试 ABRT ,QUIT ,KILL 等信号量,当然如果使用这些信号量,你得到就如下图 GAME OVER
2024-05-08 21:00:33.659 CST [75017] LOG: database system is ready to accept connections
2024-05-08 21:00:49.629 CST [133468] LOG: PID 133316 in cancel request did not match any process
2024-05-08 21:00:53.418 CST [133469] LOG: duration: 2.046 ms
2024-05-08 21:01:44.877 CST [75017] LOG: server process (PID 133469) was terminated by signal 6: Aborted
2024-05-08 21:01:44.877 CST [75017] DETAIL: Failed process was running: select * from pg_database;
2024-05-08 21:01:44.877 CST [75017] LOG: terminating any other active server processes
2024-05-08 21:01:44.885 CST [75017] LOG: all server processes terminated; reinitializing
2024-05-08 21:01:45.104 CST [133481] LOG: database system was interrupted; last known up at 2024-05-08 21:00:33 CST
2024-05-08 21:01:45.128 CST [133481] LOG: database system was not properly shut down; automatic recovery in progress
2024-05-08 21:01:45.131 CST [133481] LOG: redo starts at 2/14874A10
2024-05-08 21:01:45.131 CST [133481] LOG: invalid record length at 2/14874A48: wanted 24, got 0
2024-05-08 21:01:45.131 CST [133481] LOG: redo done at 2/14874A10 system usage: CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s
2024-05-08 21:01:45.135 CST [133482] LOG: checkpoint starting: end-of-recovery immediate wait
2024-05-08 21:01:45.149 CST [133482] LOG: checkpoint complete: wrote 3 buffers (0.0%); 0 WAL file(s) added, 0 removed, 0 recycled; write=0.012 s, sync=0.001 s, total=0.016 s; sync files=2, longest=0.001 s, average=0.001 s; distance=0 kB, estimate=0 kB
2024-05-08 21:01:45.154 CST [75017] LOG: database system is ready to accept connections你可以使用 TERM 信号名字来进行相关的操作,你得到的结果是
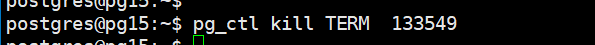
2024-05-08 21:07:31.522 CST [75017] LOG: database system is ready to accept connections
2024-05-08 21:08:39.731 CST [133548] LOG: PID 133512 in cancel request did not match any process
2024-05-08 21:08:42.808 CST [133549] LOG: duration: 1.829 ms
2024-05-08 21:09:00.033 CST [133549] FATAL: terminating connection due to administrator command
2024-05-08 21:09:12.860 CST [133557] LOG: duration: 0.856 ms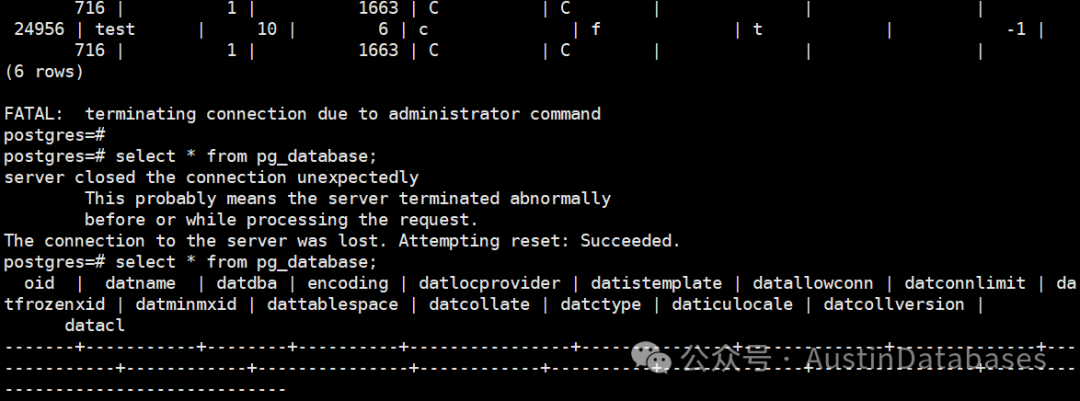
客户端的连接会被终止掉,同时数据库系统不会进行重启初始化所有的进程。
这里解释一下,pg_ctl kill term process id, 这是一种优雅的发送给postgresql 服务器信号请求其终止的方法,通过命令将term 终止信号发送给PostgreSQL 服务器进程,请求他正常的终止运行,在此之前让工作的进程进行它应该进行的工作,并正常清理相关的资源,然后正常退出。
那么今天就到这里了,22:00PM ,下班后还这么卷的也没几个了,相信今天大家都学会了。
画外音:学废了,下次找熊老师不出来回答问题,我们就一起喊 kill -9 PostgreSQL 召唤他 !


今天本账号同时发售的文章:
置顶
临时工访谈:无名氏意外到访-- 也祝你好运(管理者PUA DBA现场直播)
往期热门文章:
PostgreSQL 分组查询可以不进行全表扫描吗?速度提高上千倍?
JunkFood读者说你文章不对,作者被鞭策后,DBA 开始研究JAVA程序锁
PostgreSQL PG_DUMP 工作失败了怎么回事及如何处理
临时工说:经济规律解读ORACLE 工资低 --读 Roger 数据库专栏
PostgreSQL 为什么也不建议 RR隔离级别,MySQL别笑
临时工访谈:OceanBase上海开大会,我们四个开小会 OB 国产数据库破局者
临时工说:OceanBase 到访,果然数据库的世界很卷,没边
PolarDB for PostgreSQL 有意思吗?有意思呀
PostgreSQL 玩PG我们是认真的,vacuum 稳定性平台我们有了
临时工说:裁员裁到 DBA 咋办 临时工教你 套路1 2 3
临时工说:OceanBase 到访,果然数据库的世界很卷,没边
MONGODB ---- Austindatabases 历年文章合集
MYSQL --Austindatabases 历年文章合集
POSTGRESQL --Austindatabaes 历年文章整理
POLARDB -- Ausitndatabases 历年的文章集合
PostgreSQL 查询语句开发写不好是必然,不是PG的锅
SQL SERVER 如何实现UNDO REDO 和PostgreSQL 有近亲关系吗
MongoDB 2023纽约 MongoDB 大会 -- 我们怎么做的新一代引擎 SBE Mongodb 7.0双擎力量(译)
MongoDB 2023年度纽约 MongoDB 年度大会话题 -- MongoDB 数据模式与建模
MongoDB 会丢数据吗?在次补刀MongoDB 双机热备
临时工说:从人性的角度来分析为什么公司内MySQL 成为少数派,PolarDB 占领高处
PostgreSQL 字符集乌龙导致数据查询排序的问题,与 MySQL 稳定 "PG不稳定"
PostgreSQL Patroni 3.0 新功能规划 2023年 纽约PG 大会 (音译)
Austindatabases 公众号,主要围绕数据库技术(PostgreSQL, MySQL, Mongodb, Redis, SqlServer,PolarDB, Oceanbase 等)和职业发展,国外数据库大会音译,国外大型IT信息类网站文章翻译,等,希望能和您共同发展。
截止今日共发布 1134 篇文章

















 2220
2220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









