



开头还是介绍一下群,如果感兴趣PolarDB ,MongoDB ,MySQL ,PostgreSQL ,Redis, Oceanbase, Sql Server等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,(共2280人左右 1 + 2 + 3 + 4 +5) 新人奖直接分配到5群,5群即将达到400,停止自由申请 已建立6群。

说句不怕笑话的话,MongoDB使用也有6 7 8 年了,但对于聚合一般我是抗拒的,可能是MOGNODB 3.X落下的顽疾,一听到用MongoDB 做聚合操作,一般都不想听 不想听。但时代不一样,MongoDB已经走到了 8.0UP,聚合早就和之前不一样了。
所以怕也的上,还的学习。 以上学习基于MOGNODB7.0 ,聚合操作中首选的方案是聚合管道,或者使用单一聚合的方法。一般来说聚合操作中的管道操作,主要是通过多个阶段来处理数据,比如第一需要先过滤数据,然后对过滤的数据进行文档的分组并计算聚合操作后的结果。同时聚合还可以进行聚合后的数据更新,当然这需要在4.2后的版本才有此功能。
我们先产生测试数据,先简单产生 4万条数据
mongo7 [direct: primary] test> function insertData(dbName, colName, num) {
...
... var col = db.getSiblingDB(dbName).getCollection(colName);
...
... for (i = 0; i < num; i++) {
... col.insert({x:i});
... }
...
... print(col.count());
...
... }
[Function: insertData]
mongo7 [direct: primary] test> insertData("test", "testData", 40000)
DeprecationWarning: Collection.insert() is deprecated. Use insertOne, insertMany, or bulkWrite.
DeprecationWarning: Collection.count() is deprecated. Use countDocuments or estimatedDocumentCount.
40000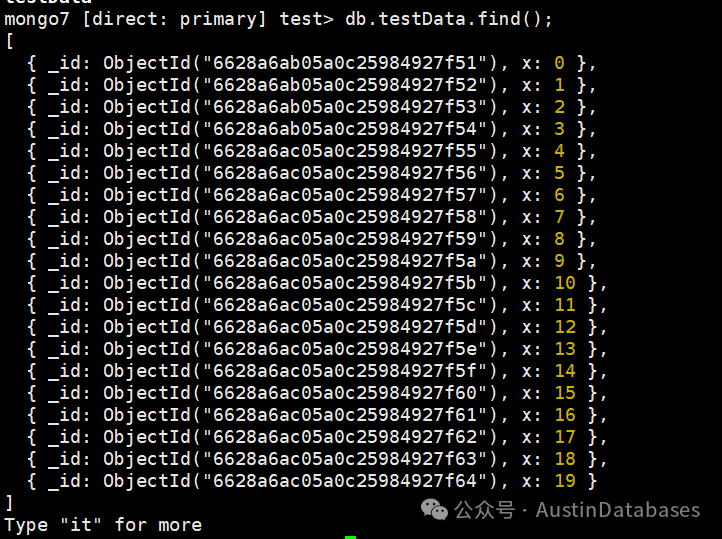
下面我们开始,假设一个需求,我需要计算插入数据中 10000 到 20000 ,20000 到 30000 之间的数据值的累加和并展示出来。
mongo7 [direct: primary] test> db.testData.aggregate([
... {
... $match: {
... x: { $gte: 10000, $lt: 30000 }
... }
... },
... {
... $group: {
... _id: null,
... sum1: { $sum: { $cond: [{ $and: [ { $gte: ["$x", 10000] }, { $lt: ["$x", 20000] } ] }, "$x", 0] } },
... sum2: { $sum: { $cond: [{ $and: [ { $gte: ["$x", 20000] }, { $lt: ["$x", 30000] } ] }, "$x", 0] } }
... }
... }
... ])
[ { _id: null, sum1: 149995000, sum2: 249995000 } ]
mongo7 [direct: primary] test>上面的语句,直接将结果进行了计算和展示非常快。
首先这边语句分为两个部分,第一部分是限制数据进入,因为这里计算是大于等于10000 和 小于30000,所以我们需要根据match 来进行数据的排除,将9999以内的数字和30000以外的数据进行,排除。
$match: { x: { $gte: 10000, $lt: 30000}
然后留下的是我们的要处理的数据,进行数据的聚合操作。
$group: {
_id: null,
sum1: { $sum: { $cond: [{ $and: [ { $gte: ["$x", 10000] }, { $lt: ["$x", 20000] } ] }, "$x", 0] } },
sum2: { $sum: { $cond: [{ $and [ { $gte: ["$x", 20000] }, { $lt: ["$x", 30000] } } }, "$x", 0] } }
这里在过滤出我们要的数据后,首先我们遇到的是针对什么进行分组,如果是传统数据库,这里面一般就头疼了,分组是没有字段的,这里MongoDB 是可以针对没有分组的聚合数据进行分组的,上面就是一个案例,我们只有object_id , x 两个字段,我们怎么聚合分组我们的分组实际是值,这也是传统DBA 烧脑的开始。
我们这里根据过滤出的条件,分别对于符合条件的数据进行聚合。
sum1: { $sum: { $cond: [{ $and: [ { $gte: ["$x", 10000] }, { $lt: ["$x", 20000] } ] }, "$x", 0] } }
这条的意思是,首先要表达的是我们要进行 sum的操作,也就是累加和,然后 cond 的意思是在我们match后的数据还需要进行条件的筛选,也就是我这里只要大于等于10000 和小于20000的数,进行累加和,如果这里条件都不符合的话,我们就给一个默认的值 0
mongo7 [direct: primary] test> db.testData.aggregate([
... {
... $match: {
... x: { $gte: 10000, $lt: 30000 }
... }
... },
... {
... $group: {
... _id: null,
... sum1: { $sum: { $cond: [{ $and: [ { $gte: ["$x", 10000] }, { $lt: ["$x", 20000] } ] }, "$x", 0] } },
... sum2: { $sum: { $cond: [{ $and: [ { $gte: ["$x", 20000] }, { $lt: ["$x", 30000] } ] }, "$x", 0] } },
... sum3: { $sum: { $cond: [{ $and: [ { $gte: ["$x", 40000] }, { $lt: ["$x", 50000] } ] }, "$x", 0] } }
... }
... }
... ])
[ { _id: null, sum1: 149995000, sum2: 249995000, sum3: 0 } ]
mongo7 [direct: primary] test>上面的例子中我们可以看到,最后一句明显就是找茬的,我们在顾虑数据的时候值包含了10000 到 30000的数据,而下面是要40000到50000的数据,这里cond 条件就产生效用了,如果符合条件则打印结果,如果不符合条件,则选择后面的给定的结果进行打印,很明不符合条件的为0
那么这样的语句还有其他的写法吗,有的,例如下面的写法
mongo7 [direct: primary] test> db.testData.aggregate( [
... {
... $match: { x: { $gte: 10000, $lt: 30000} }
... },
... {
... $group: {
... _id: null,
... sum1: { $sum: { $cond: [{ $and: [ { $gte: ["$x", 10000] }, { $lt: ["$x", 20000] } ] }, "$x", 0] } },
... sum2: { $sum: { $cond: { if: { $gte: ["$x", 20000] }, then: "$x", else: 0 } } }
... }
... }
... ] )
[ { _id: null, sum1: 149995000, sum2: 249995000 } ]
mongo7 [direct: primary] test>我们可以看到,结果是一样的,但写法的确是不同,第二个我们采用了是条件的方式来撰写的,也就是最后一个20000到3000,所以用了另一种Mongodb的语句的写法。
sum2: { $sum: { $cond: { if: { $gte: ["$x", 20000] }, then: "$x", else: 0 } } }
这个写法的意思是,如果值大于等于20000的话,那么就取值,否则就是0
明显这里是一个判断的方式的表达,如果想用SQL 来表达类似的意思可以写成,下图方式
SELECT
NULL AS _id,
SUM(CASE WHEN x >= 10000 AND x < 20000 THEN x ELSE 0 END) AS sum1,
SUM(CASE WHEN x >= 20000 AND x < 30000 THEN x ELSE 0 END) AS sum2,
SUM(CASE WHEN x >= 40000 AND x < 50000 THEN x ELSE 0 END) AS sum3
FROM
testData
WHERE
x >= 10000 AND x < 30000;最后在给传统数据库DBA 来一个烧脑的作为此次的结尾,这样的数据查询如果是在传统数据库,相比是有索引也走不了,作为传统的DBA 对于这样的语句,在X列加索引,是不会抱有希望的。
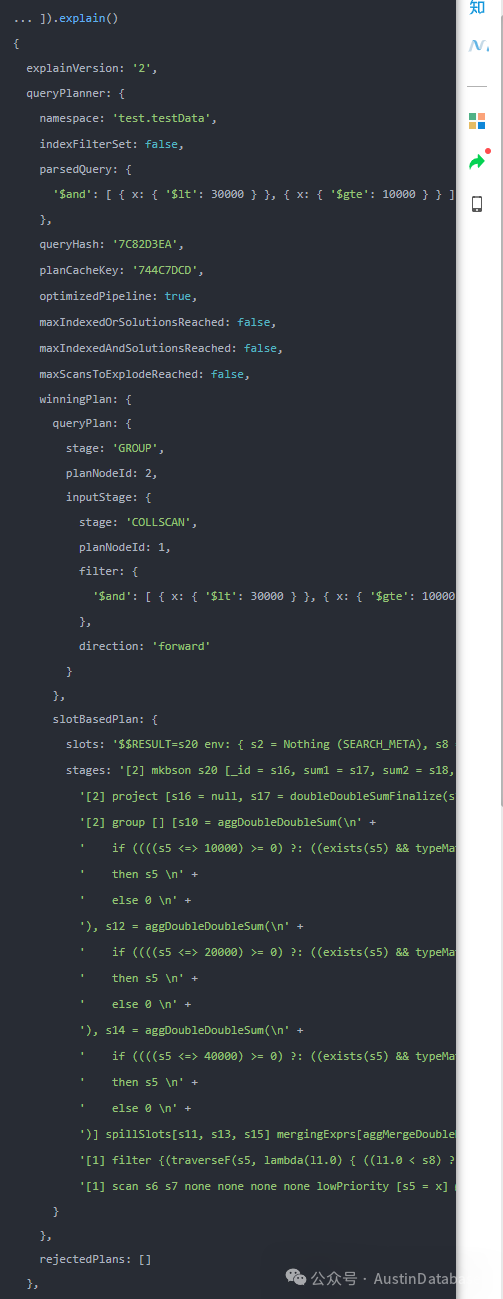
这里我们也比较一下,在对X key 加索引后的查询执行计划,是否有不同,答案是当然有不同。
1 不加索引,时从执行计划看,走了全collection扫描是没跑了
2 添加索引后
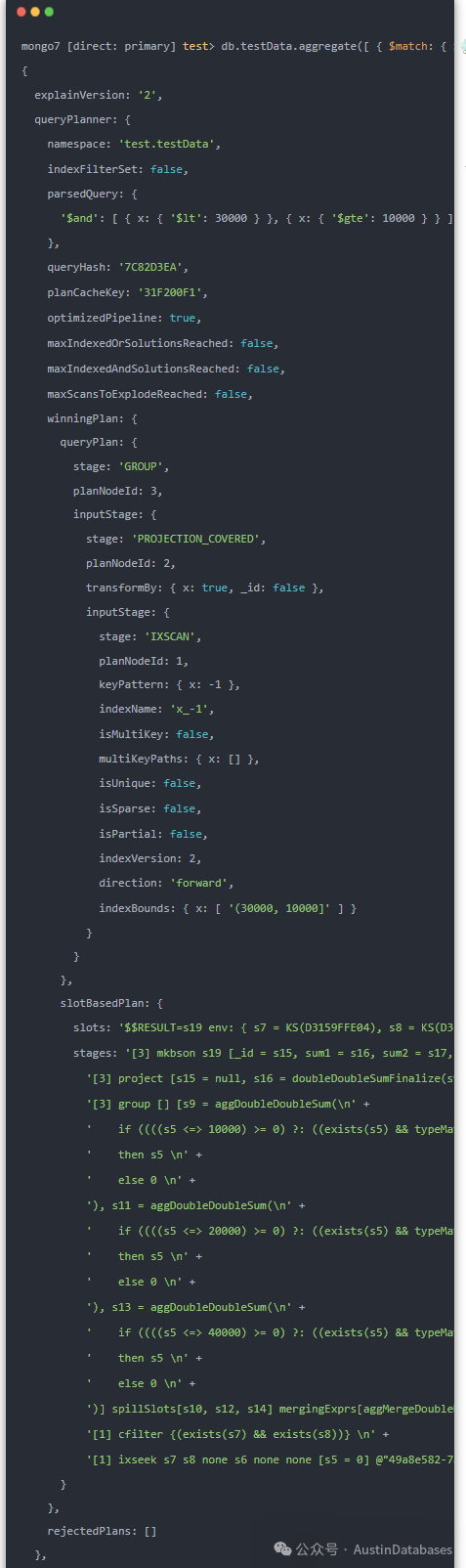
结果与传统数据库的思路不一样,传统思路这样的查询这样的量是无法走索引的,全表扫描是一定的,而在NOSQL数据库中,这样的情况添加了索引也可以运行并使用,后续还的学习和发现,目前写不下去了,需要散热
后记,随着文档型数据库的被熟知,并且步步紧逼传统数据库一些事务,跨表,跨库查询,以及聚合查询等方案的退出,以及天然的分布式存储方式,和传统数据库打死都没有的灵活性,文档数据库和传统型数据库PK 的还在后面。
待.....
今天本账号同时发售
置顶
临时工访谈:无名氏意外到访-- 也祝你好运(管理者PUA DBA现场直播)
往期热门文章:
PostgreSQL 分组查询可以不进行全表扫描吗?速度提高上千倍?
JunkFood读者说你文章不对,作者被鞭策后,DBA 开始研究JAVA程序锁
PostgreSQL PG_DUMP 工作失败了怎么回事及如何处理
临时工说:经济规律解读ORACLE 工资低 --读 Roger 数据库专栏
PostgreSQL 为什么也不建议 RR隔离级别,MySQL别笑
临时工访谈:OceanBase上海开大会,我们四个开小会 OB 国产数据库破局者
临时工说:OceanBase 到访,果然数据库的世界很卷,没边
PolarDB for PostgreSQL 有意思吗?有意思呀
PostgreSQL 玩PG我们是认真的,vacuum 稳定性平台我们有了
临时工说:裁员裁到 DBA 咋办 临时工教你 套路1 2 3
临时工说:OceanBase 到访,果然数据库的世界很卷,没边
MONGODB ---- Austindatabases 历年文章合集
MYSQL --Austindatabases 历年文章合集
POSTGRESQL --Austindatabaes 历年文章整理
POLARDB -- Ausitndatabases 历年的文章集合
PostgreSQL 查询语句开发写不好是必然,不是PG的锅
SQL SERVER 如何实现UNDO REDO 和PostgreSQL 有近亲关系吗
MongoDB 2023纽约 MongoDB 大会 -- 我们怎么做的新一代引擎 SBE Mongodb 7.0双擎力量(译)
MongoDB 2023年度纽约 MongoDB 年度大会话题 -- MongoDB 数据模式与建模
MongoDB 会丢数据吗?在次补刀MongoDB 双机热备
临时工说:从人性的角度来分析为什么公司内MySQL 成为少数派,PolarDB 占领高处
PostgreSQL 字符集乌龙导致数据查询排序的问题,与 MySQL 稳定 "PG不稳定"
PostgreSQL Patroni 3.0 新功能规划 2023年 纽约PG 大会 (音译)
Austindatabases 公众号,主要围绕数据库技术(PostgreSQL, MySQL, Mongodb, Redis, SqlServer,PolarDB, Oceanbase 等)和职业发展,国外数据库大会音译,国外大型IT信息类网站文章翻译,等,希望能和您共同发展。
截止今日共发布 1134 篇文章


















 871
871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









