




开头还是介绍一下群,如果感兴趣PolarDB ,MongoDB ,MySQL ,PostgreSQL ,Redis, Oceanbase, Sql Server等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,在新加的朋友会分到2群(共1450人左右 1 + 2 + 3 + 4) 3群突破 460已关闭自由申请如需加入请提前说明,新人会进4群,另欢迎 OpenGauss 的技术人员加如入。
每日感悟
人生是有限的,一定要谨记,你成功99%都是偶然,1%是你能掌控的,敬畏每时每刻的顺心如意,释然99%的糟心和无奈。
2023 Postgres Citus Con 主题PostgreSQL performance tips you have never seen before
非常高兴有这次的机会来介绍这个话题,希望我的话题能带来一些您从未见过的东西。我是汉斯,目前担任Cybertec CEO ,我们在PostgreSQL 方面的经验到目前有23年了,我们提供的基于PostgreSQL服务遍布全球。

下面的一些品牌也是我们的客户,相信大家对于一些品牌都是熟悉的,我们提供性能优化,高可用,以及各种疑难杂症的解决。今天我要讲的是PostgreSQL 那些你从未建立过的优化的点子。


这里很多的优化的点子中,包含了PostgreSQL部分的一些奇怪参数的优化,修改以及添加内存或CPU的电子等等,但是我今天要说的都不是这些,我要说说之前你们可能没有见过的。

我们用一个实例来说明,参见下图,我们执行一个特别简单的语句select 1,然后我们查看压测的结果,给出的结果是100000 每秒TPS,然后我什么都没有变,只是改变了连接的方式,给出的结果是200000每秒TPS,是什么导致不同的结果。这里最大的不同是本地的主机不见了,实际上这里比较的是
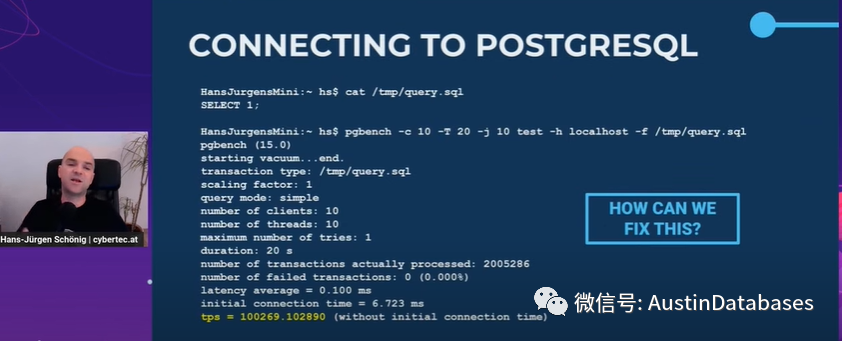
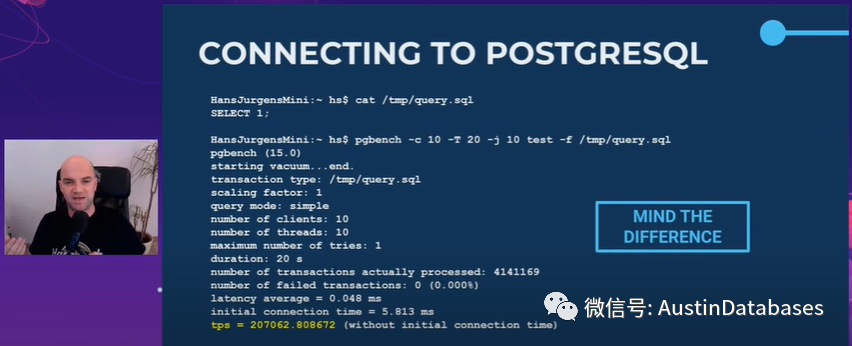
本地主机和本地UNIX 套接字这两种连接的方式已经造成在同样的语句执行方式上产生TPS测试后极大的不同。这意味这什么,延迟的问题很重要,我经常举一个例子,我们如果要发送货品给Chnia,这里我们不管是50个货柜还是200个货柜,这都不是问题,带宽不是问题,我们有很大的集装箱货船,但是重要的问题是时间,中转的问题。

回到我们的实验,在同一台主机,仅仅是本地访问和UNIX SOCKET 的访问模式,最后的结果就不一样,那么这个问题放到云主机,放到使用K8S的PostgreSQL上那么问题是一样的,访问延迟了。
这里我们的访问,有多少防火墙,多少电缆多少虚拟层,这些很重要,上面的例子中,我仅仅是消除了网络而已(注明:消除了网络协议,整体测试是在一台主机上完成的)。
所以我们把SQL的问题放到一边,网络的问题在数据传输中的延迟就是一个问题。下面我们来说第二个问题,

下面我们来说说存储的问题,这里有一个例子,我创建了表,并且插入数据,这里我们的表非常的小是varchar 和 int 混合的表 1000万行的表,这是一张651MB 的表。我们怎么来更有效的存储数据,我们看下一张图,同样的,但是我们不在将这些字段混合起来,而是整合起来,这可以保证表的大小缩小,表的大小从 651MB 到 574MB,的确我们的表缩小了,原因是对其,把固定的字段放到前面,把变化不固定的字段放到后面可以使我们的表在存储同样数据的情况下,变小。
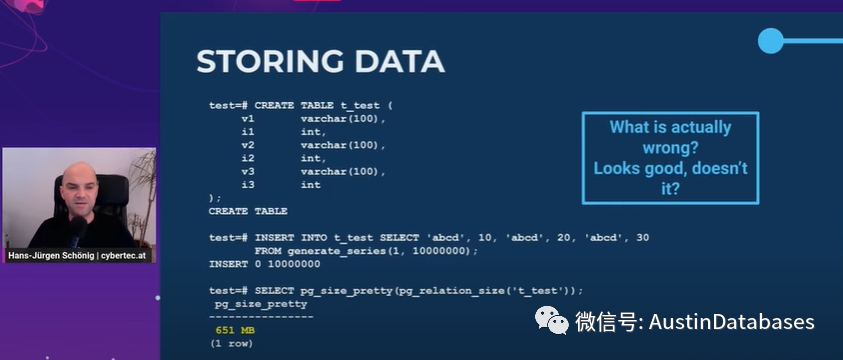

这里我们还有一个例子,

这里我们有两个表一个 胖表 一个小表,数据量是一样的,唯一不同的一个表是包含4列的,一个表是一开始两列而后面加了两列,并且我们给了默认值,这样的情况下,我们可以看到一次性加入的表里的大小比后添加字段的表的大小要大。

在我们建立数据表后,我们有大量的索引需要建立,通常我们要建立很多的索引,索引需要很大的空间,如果你使用的是 INT ,时间类型,等固定的字段来建立索引,大约一行在每个索引中需要25bytes 来存储数据,在这里案例中我们创建了一个表,表里有电子邮件地址,并且这里有1000万的数据


这里我们做了一个比较,我们为邮件地址创建的索引的大小是 825MB 而我们如果把邮件地址HASH话在进行存储,需要214MB,这里邮件地址是很大的,虽然他可以存储在数据库中,但是他不适合存储在内存中,非常的不适合,索引是要在内存中工作的,这里我们通过这样的方法减少了75%的存储,对较小的值进行索引。

当然这里如果你使用的的磁盘是Nvme 磁盘,你的带宽足够的话,当然你可以直接使用邮件索引化的处理方式,更少的使用内存,并且有助于在内存和磁盘间的带宽进行节省,当然这只是举一个有趣的小例子。当然如果你有10G的索引呢,如果你有60G的索引呢,这就不是一个有趣的小例子了。
一旦你使用了POSTGRESQL 通过pgstattuple来检查数据库中表的膨胀率这在PG是一个常见的东西,我们注意看第一个部分,其中我消耗的时间是接近4秒,当我换了一种写法后,执行的时间变为0.4秒。

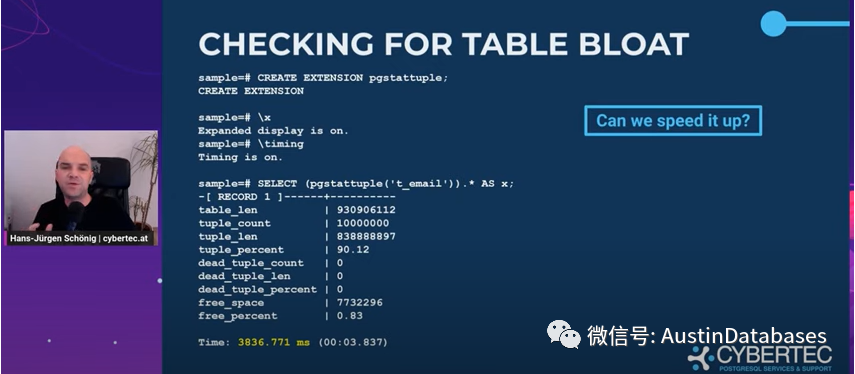

这里的不同在于两个语句中星号的位置,一个是以函数的方式展现的,一个是以子句的方式展现的,第一个部分实际上是多次调用这个函数,每列调用一次,而后面是一次性调用,在展开,所以使用这个函数的时候,两种不同的方式调用起来的时间不同。所以必须小心查询扩展中使用组合类型的函数。


接下来是PostgreSQL的FDW ,一般来说我们通过FDW 把外部的数据嵌入进PG中,在使用FDW的时候我们经常会遇到一个问题,查询的速度提升的问题,这里我们举一个例子。我们创建一个FDW ,data wapper ,mapping 然后我们读取数据。


这里我们看读取的数据的时间是5.2秒,1000万行数据库这样的速度很慢这里我们优化的手段可以通过下面的手段来进行,改变外部表中 fetch_size ,在改变设置后,我们再次读取数据,发现时间变为了3.6秒,这里外部的读取数据的是分步读取数据的方式,读取50行,传递50行,在读取50行,在传递50行,所以我们用了这么多次来传递数据,耗费了多少网络延迟,我们的优化方式是每次获得更大的数据表来避免多次的访问。

后面还有一部分是基于FULL INDEX 这里由于在PG中使用FULL INDEX的较少,所以略过。最后总结,我们这里讲了如何创建表,创建索引,以及如何传递数据等等,实际上我们最终的目的是让应用更好的处理数据,提供一个更好的用户体验,很希望下次很快见到你,同时我们也在招聘相关的PostgreSQL 的工作者,如果你感兴趣可以到我们的招聘主页看一下。





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









