




此文来自于AndresFreund,PG社区资深开发,探讨IO对于PG方面的问题。此翻译和文字来自于视频,因为部分英文听的比较费劲,所以可能有失误的地方,尽请见谅。
最近问问题的同学挺多的,也有问有没有群的,实在是忙没有建群,所以问的人多了,想想还是建一个群,但本人写文章不懒,其他的比较懒,因为问POLARDB的问题的多,所以建立了一个POLARDB和PG,MYSQL,MOGNODB,REDIS,数据库 以及文章问题的讨论群。希望能帮助自己也帮助大家共同提高,要进群的,可以添加微信 liuaustin3 ,来申请加群.
——————————————————————————————
正文

HI, 我是 Andres, 今天我们来讨论一些IO 在POSTGRESQL 中的我们想做的一些改变,和我们已经做了的一些改变。对于POSTGRESQL 我已经工作了大约15年,并且一直从事这个工作....(口头禅听不懂)
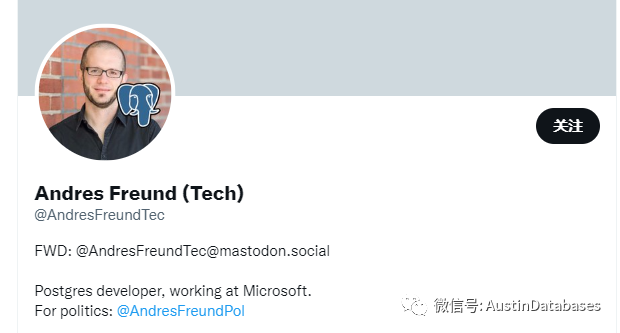
下面这是简单的与POSTGRESQL IO 有关的设计,这一个部分,至少有15-20年的时间,这里的buffer pool是shared buffer pool的一部分,这些部分被bufferIO填充,如pread,pwrite ,whatever ,

我们来看下一张图,如我们所知,应用要访问数据,不能直接到系统层面,而是要先到我们的kernel page cache 中,如果要的数据库不在page cache中,我们会和drive打招呼,hi我这没有数据,然后drive 就给我返回了数据。数据会经过dma, dma就是拷贝数据不经过CPU 获得数据并且这个copy是通过kernel ,然后page cache将数据返回给应用。
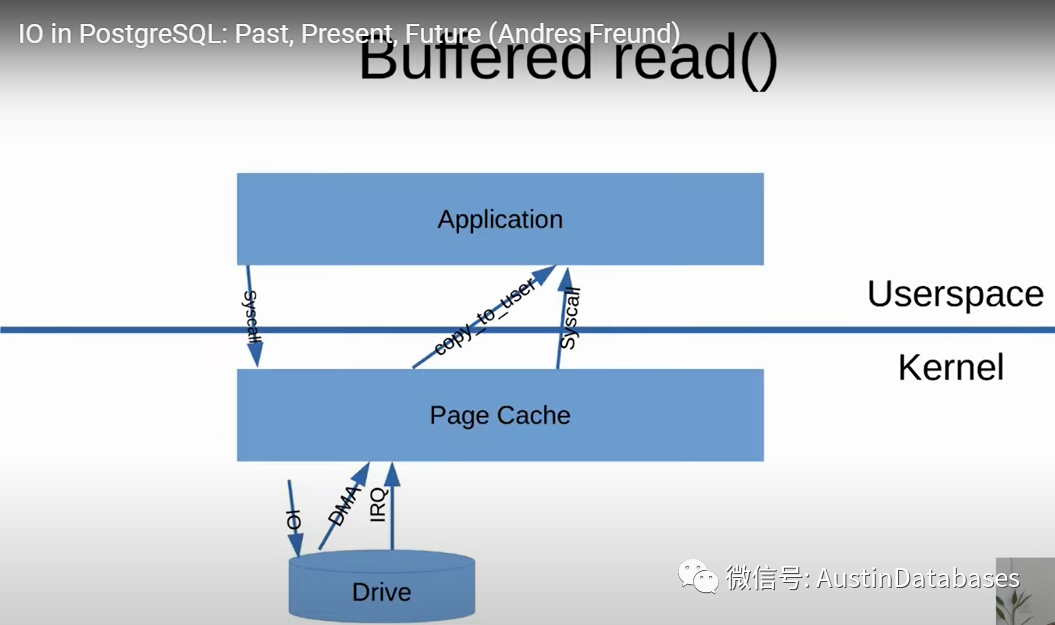
这里的操作是直接内存对内存的操作,在硬件层面,所以这里的操作都是自动的
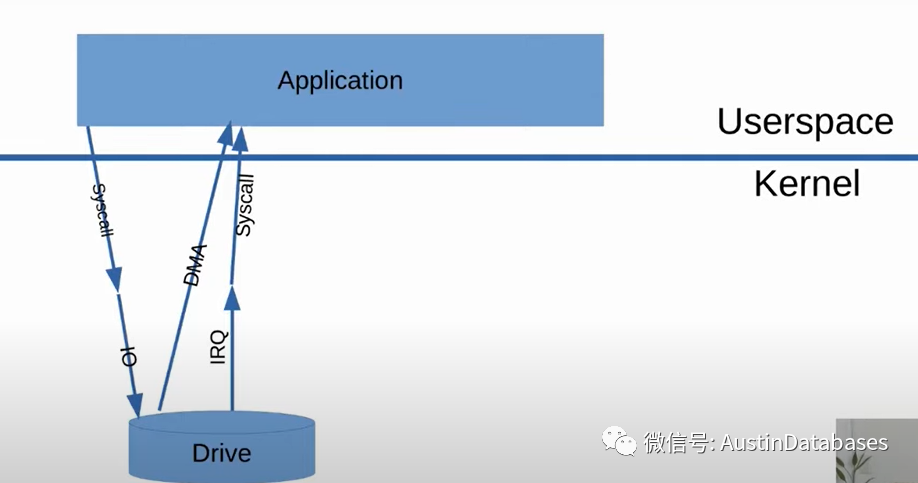
让我们回到数据的写出,这里之前的操作是写一个head lock ,数据来自于shared buffer pool要写出的数据,首先我们要异步的将日志写入到磁盘在我们写数据到磁盘之前。这里我们改进了一些瓶颈有关于并行操作,组提交的部分,同时我们改进了checkpoint异步操作,以及wal写和backgroup写。
这里我们改进walwriter同时对于buffer replacement 我们优化了,让替换的操作不用维护成本非常高的 linked lists 的模式,或者多次进行buffer 的替换的行为,以及定期的backend process 对于buffer 的更新的工作。(这点个人认为是一个重点,如果sharedbuffer pool 进行更新,导致所有的用户进程都进行定时的同步或替换,成本的确很高)

说到这里,这个小哥好像语塞了,出现了一个提出问题的人。
问题是:你们优化了扫描的部分是因为你们知道在切换的过程中,扫描会像洪水一样将 cache中的数据挤出吗?
小哥回答问题:POSTGRES 有ring buffer 我们习惯把他们叫做bulk io这有点像顺序的vacuumscan, 这些 ring buffer 是有固定的SIZE,新的页面的读取,举例我认为默认我们有128KB的 ring buffer,新的页面的读取不会超过这个固定的SIZE, 大部分情况下,你可能看到一个问题,问题是如果你在cold cache 中进行顺序的扫描,将不能快速的将share buffers 进行非常快的填充,因为他们将用 ring buffer ,这个问题有一个不太好的地方,就是如果你使用了 4分之三的 SHARE BUFFER, 也就是工作负载太大,那么数据将不会直接有效的加载到 share buffer 中,这尤其在数据的读取中会产生这样的问题,
说完这个,问题继续,问题: 意思是 ring buffer 被work memory 控制吗,在每一个worker
回答问题:不不对,这只在特殊的情况下发生,尤其在读取一些比较大的数据,如16KB 的数据等
小哥回答讲述,继续,我们回到checkpiont的部分,checkpoint 的工作就是将数据进行同步,这里我们有一件需要说的就是buffer io 中并没有完全添加控制刷脏的部分在 kernel中,举例,当 checkpiont需要写出大量的脏数据,kernel 突然收到指令会进行延迟的操作,有可能会延迟300秒,很明显有些问题是在linux中的,这是一个hugeproblem,如果 postgres 写出100 G的脏数据,到kernel page cache,即使你的存储非常的快,但是kernel 刷脏大量数据不会很快,这是一个瓶颈。这里使用了 同步文件range和msync和其他有关的部分,这里多个不同的POSTGRES 对于写应该有控制,这样的情况下就有利于改进延迟的问题。所以我们的说下面的问题
那么我们说了这么多问题,非常非常非常的糟糕,而这些问题,没有让POSTGRES变得糟糕,这里有一个需要说的原因,我认为就是我们使用LINUX 来做了非常好的工作,有read ahead internally,相对于其他系统LINUX在这方面做的是很出色的.另外buffer 数据的替换过程也使用的 doublebuffer的方式,这浪费了不少的内存,尤其在使用了 shared buffer pool 和 kernel buffer 的情况下。

问问题的又来了,问题,你刚才说LINUX 系统非常棒,那么什么系统非常的糟糕, windows?
回答:对windows 非常的糟糕,远远的不如LINUX(大家注意这个小哥是微软的公司的开发者),然后这个小哥说了一句,哦不我的意思是,我对WINDOWS 的方面的经验有限,我是说metadata 读取的部分要慢一些。
问问题说:我不会宣扬这个事情,但是他们是付你工资的,但我想你的老板不会关心这个事情。
小哥继续说,有些问题被掩盖是基于原有的存储系统太慢,同时尤其在 IO STACK 部分,所以这里并没有产生大问题,同时我们还进行了并行的方式让一些缓慢的问题被隐藏了。
然后我们说说为什么会发生这样的问题?

POSTGRESQL是一个非常非常小的TEAM 相对于其他数据库产品来说,你会看到一些商业数据库有成百上千的人做核心引擎部分,而我们的POSTGRESQL team完全投入到这个工作中的,不到10个人。
待......
(目前是整个视频的20%,后面会继续学习和翻译与分享)


















 3674
3674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









