



 本文介绍如何使用PostgreSQL的auto_explain模块自动记录慢查询的执行计划,包括配置参数详解及注意事项。
本文介绍如何使用PostgreSQL的auto_explain模块自动记录慢查询的执行计划,包括配置参数详解及注意事项。

在数据库的执行SQL的语句中,有很多语句在执行中,执行计划会变化,而执行计划的变化会导致SQL 语句执行时间的变化,如何对在POSTGRESQL 中执行较慢的语句。
auto_explain 模块提供一种自动记录慢语句的执行计划的功能,使用这个功能的同时需要注意,任何功能的开启都需要负担一定的性能损耗,在损耗的情况下,我们应该判断是否开启这个功能。
我们需要在下面的这个位置,将auto_explain 填入到 local_preload_libraries ,并且重启数据库服务器。
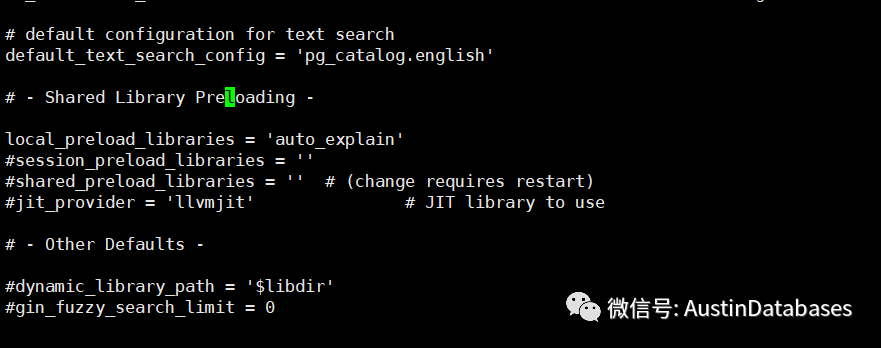
除此以外如果要auto_explain 能良好的完成工作,POSTGRESQL 针对auto_explain 有几个参数需要修改,下面我们一个一个说
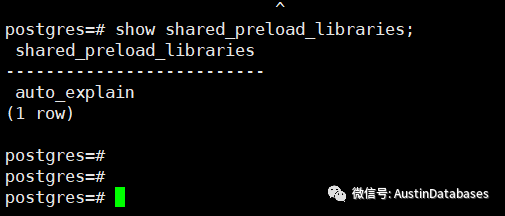
1 auto_explain.log_min_duration
这个参数是启动auto_explain的核心参数,除了在local_preload_libraries 中需要加载auto_explain, 启用这个功能的另一个核心参数就是 auto_explain.log_min_duration. 这个参数代表了决定了超过多长时间的慢SQL 语句需要对执行计划进行记录,默认是-1 ,表名不记录任何慢语句。
2 auto_explain.log_analyze
这个参数主要是在输出的内容上进行调整,如果不写这个参数则输出的内容仅仅是 explain 的内容,而如果将这个值设置为 ON 则可以打开 explain analyze 的值
3 auto_explain.log_buffers
这个值是在开启了 log_analyze 后产生的在analzye后打印 buffers的值,默认也是关闭的,在打开 auto_explain.log_analyz 后这个参数的修改才有效。
4 auto_explain.log_timing
这个值主要控制在打印这个语句执行的时间有多长,这个参数也是 auto_explain.log_analzye 的后置项。
5 auto_explain.log_verbose
这个值主要控制 explain 中的verbose 信息的信息输出。
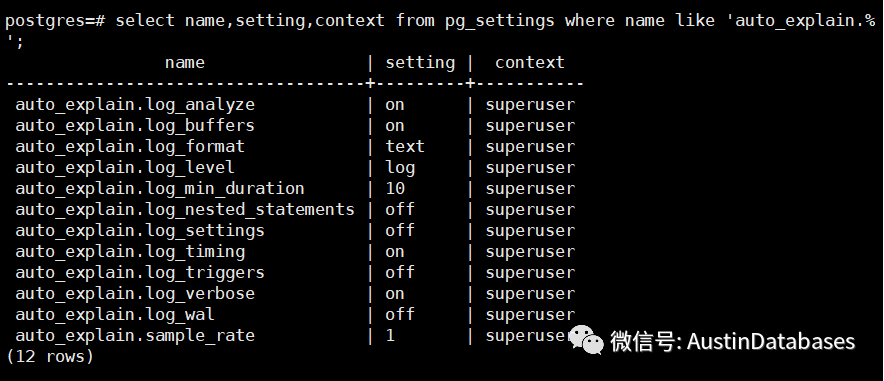
我们执行一个SQL 查看在调整参数并重启后,日志中开始出现慢查询的执行计划的信息。
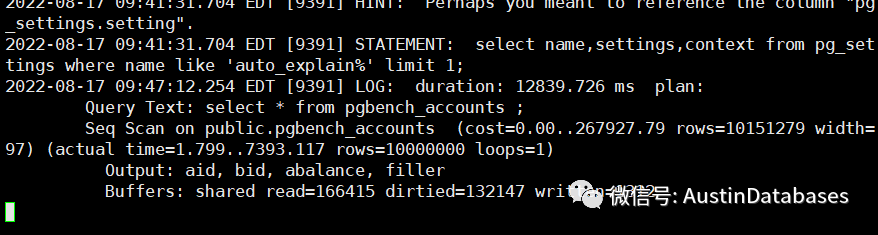
实际上我们也可以修改打印的信息的格式,修改日志输出格式后,整体
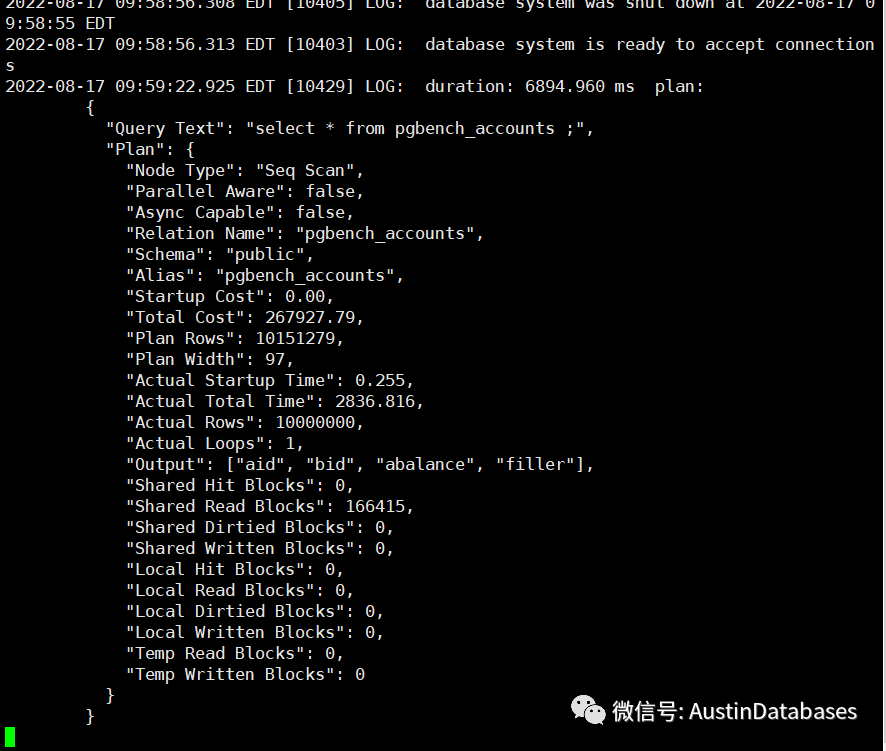
相关 auto_explain功能就直接启用了。那么 auto_explain有什么劣势或者在使用中需要考虑的点
1 PG 中的慢查询和auto_explain 中的log_min_duration 应该设置成一个值吗?
这个问题实际上,个人人为不应该设置成一个值,而是应该设置为一个比 log_duration 更大的值。主要原因是,功能的不同,查看慢查询的执行计划本身并不应该针对每一个慢查询,而是应该对应与一些较长时间执行的SQL 如我们默认 1秒的SQL 就要记录在慢查询记录中,但是我们不应该将慢查询执行计划也设置成一秒,而应该讲时间拉长,例如 10秒,超过10秒的语句我们才需要查看他的实际执行计划,如果将每个超过1秒的语句都记录慢查询分析的话,浪费的日志空间,和消耗的系统IO等资源会比较大。
2 auto_explain 在什么情况下,需要开启 ?
auto_explain本身不适合一些已经运行一段时间的数据库并且数据量较大,平时数据库并没有太大的问题,而是预防一些由于数据量突然加大,导致执行计划和数据表analyze 不匹配导致的临时性的执行计划变化导致的问题,一般这样的语句都有执行时间突然变长的情况,在这样的情况下,适当的查看这个语句的执行计划,并记录当时的执行计划,有助于分析问题。
同时这个功能对于高频的,系统性能已经出现问题的数据库,在上线这个功能时候,需要考虑这个系统是否能承受这个功能带来的一些问题的考虑和前摄
1 系统消耗增多
2 磁盘是否能承载更多的日志
3 这个功能能实际解决问题的场景与你的期望是否契合
4 及时调整截取的SQL 的时间,避免大量的不需要的SQL 的分析被记录的日志。


















 816
816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









