 POLARDB:快速扩容救星,解决高并发业务挑战
POLARDB:快速扩容救星,解决高并发业务挑战




 本文讲述了在面临高并发业务压力时,传统的数据库解决方案如分库分表、分布式数据库等存在的问题。在一次业务高峰期,互联网餐饮行业的排队业务数据库出现压力,通过阿里云的POLARDB,特别是其快速扩容功能,成功解决了突发的高并发问题,使业务起死回生。POLARDB的快速创建从节点能力在几分钟内缓解了数据库负载,证明了其在应对突发流量时的有效性。
本文讲述了在面临高并发业务压力时,传统的数据库解决方案如分库分表、分布式数据库等存在的问题。在一次业务高峰期,互联网餐饮行业的排队业务数据库出现压力,通过阿里云的POLARDB,特别是其快速扩容功能,成功解决了突发的高并发问题,使业务起死回生。POLARDB的快速创建从节点能力在几分钟内缓解了数据库负载,证明了其在应对突发流量时的有效性。

没有不好的数据库,只有不会使用的人,和带有偏见的人,数据库好用不好用,不在数据库,在选择者是否有能力驾驭或懂得数据库设计者设计这个数据库的初衷。那么我们怎么在业务中,选择了POLARDB FOR MYSQL ,同时在上星期,救了我们一命,证明我们的选择的正确性,下面就将这个故事说一说。
8月4日,是一个疯狂的开始,也是一个不普通的日子,在这个日子里面我们验证了POLARDB FOR MYSQL ,如何让一个濒死的业务,起死回生的过程。
故事线交代一下前因后果,公司主要从事的是互联网餐饮行业,七夕,元旦,圣诞节,以及各大节假日一直是我们的痛点,平时没有问题,一到这些日子,我们就深刻感受到--- 访问流量的威胁,即使到了今年的经济这样的地步,餐饮行业还能“欣欣向荣”。
对于数据库来说,这不是一个好日子,程序可以通过K8S 进行快速扩展,而在数据库层面能想到的一般有如下的解决方案
1 通过分库分表,将数据压力分散开来
2 通过分布式数据库,来将数据的压力和访问的压力分散开来
3 通过不同的数据库类型组合来将不同的数据类型和业务类型的数据进行重新组合,达到缓解压力的目的
4 通过垂直拆分对业务拆分,同时对数据库系统的硬件能力进行提高,应对业务爆发式的风险。
呵呵,这些都用了,如何,还是出了问题,当然这也是正常的,在一个短暂的时间,爆发式的人群涌向各大 米西米西的 地方,送花的,求婚的,晚上还有活动的,必然引起数据爆发式的增长和对数据库并发访问的碾压式的压力。
我们把上面的方式一个一个的来拿出来说说
1 分库分表,数据访问和数据存储的压力分散开,这是大部分架构设计中对于业务压力针对数据库方面的必经之路,当然分库也有多重分法,横向的 ,纵向的,横向加纵向的,等等,这里面有一个问题,就是开发针对分库后的数据合并处理和计算的问题,有些时候一个业务在如何拆分,他的量还是很大,所以分库分表不足以是一个完美的方案。
2 分布式数据库,分布式数据库本身来说到目前为止,还是一个新生的事物,针对传统集中化的数据库而言,分布式数据库只能算一个有益的补充,如果将其变成和现在传统数据库的地位,还需要分布式数据库自己突破
1 硬件的高需求 ,只能更高,不能低就
2 分布式协议产生的锁对性能的束缚
3 数据备份,数据日常运行维护的难点和痛点
对于分布式数据库一句话可以总结,很美,但暂时只能远观,近了满脸都是坑。
3 多个数据库混用,这个方法也可以解决一些问题,如 REDIS MYSQL MONGODB ES 联合在一个项目中使用的组合,缓存提高并发访问, MYSQL 做数据分库分表的数据存储,和基础数据存储, MONGODB 日志,加各个接口,外部的信息交互,和高并发查询的需求,ES 作为分库分表后的数据归并,当然还可以在加入 CLICKHOUSE 对一些数据库进行简单的OLAP 的操作,等等
这样的好处很多,不好的地方,就是费人,一个人都把这些数据库掌握了,都精通了,如同让一个人的语言能力,爆发式的增长,中,英,日,德,法,意,拉丁, 要一个人会这些语言?,we are not a robot and get out 996,007,所以必然 DBA 的团队的人数会暴增,10几个DBA 的团队那就很平常了。
4 通过提高硬件的配置来应对,这样的方式也是我们平常选择的方式,缺点也很明显,如果不分库,在一个数据库中,可能内存和CPU 不是问题,而存储成为一个难点,单库,单表的数据太大,最终产生热点,而如果分库分表,每个数据库的配置都高,费用又是一个问题。
所以综上,都是解决高并发业务和高数据量的方法,但都有各自的问题和缺陷,同时上面的方案还有另一个死穴, 就是你的架构和开发不能太垃圾,否则上面你一个都完不成,并且需要时间研究,整改,推翻,在改,摸索经验。
选择POLARDB 之初,其中最大的原因是它的一个特点 ,快速扩容的特点,一个从节点在几分钟之内就能产生,这个特点看上去也就那么回事,尤其在众多数据库都声称可以快速添加节点的今天,言归正传,POLOARDB 怎么就拯救了业务。(至少我们认为他是言行一致的)
先说一下什么业务,这个业务比较简单,主要的工作就是负责各个营业场所的排队业务,一个餐饮门店本身是有客流限制的,一般我们到餐馆后,需要等位,就是拿号,同时这个业务还有叫好,和取消号码,跳号,遍历排队人数,与大屏显示等多种功能,业务高峰时,如果有几十万家店铺,都在使用排队这个业务,都在拿号,叫号,遍历,此时数据库的压力是巨大的。
那么上面的方法都用了吗? 回答是没有
1 这个业务不是核心业务,所以平时很难有资源紧张的时候,因为每个餐厅大多不会等位叫号
2 数据量不大,因为叫号的业务数据基本上不留存,都可以清理
基于以上的问题,分库 ,分表的需求就很难成立,但是又会产生一个难点就是特殊日子,你的业务并发来了,一个数据库撑不住。
那么又有人问了,你提高资源不就行了,加大CPU 和内存,不信搞不定,呵呵 ,我倒是想,钱是大风刮来的,每个数据库都要付费的,我提高资源,平时用不上,一年就几天用,老板知道了估计开了我的心就有了。
怎么说呢,这个问题可以用如下文字来表达, 做也不行,不做也不行,上也不行,下也不行,横批,就是不行。
就在8月4日,这个业务的数据库就突发问题了,系统CPU 已经飙升到 99% 但磁盘IO 不高,基本都是在查询。以为不停的有人的查询自己的号码前面还有多少桌。
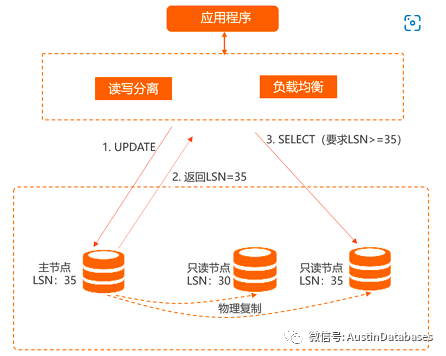
那么此时你该怎么办? 我们在这个业务上使用了POLARDB 作为基础数据库,POLARDB 其中有一个这样的优势,快速产生从节点,基本上 5分钟左右就能产生一个只读节点,这也是基于多少个从库的存储就只有一份,以及REDO LOG 作为数据复制的基础,所以从库的建立异常的快速,在产生从节点后,直接加入到代理中,进行均衡负载,将这个突发的问题,化解在无形之中。
在当日,我们发现问题后,立即启动添加从节点的工作,在几分钟之内,已经有一个自动的新的节点加入到 悲催的 负载中,新的只读节点瞬间让负载下降,业务抗住了那些在8月4日任性消费的 全国的男男女女 和老老少少们。
此时回到主题,POLARDB 让濒死的业务,起死回生,是的他做到了。此时我的想法,什么云原生,什么分布式,什么什么,能解决问题的,才是好猫。
注:(其中添加节点的问题,与后续,我们会找另一期来说说)


















 1944
1944

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









