



 介绍了MongoDB 4.0版本如何实现事务支持,包括原子性、一致性等特性,并提供了通过mongoshell进行事务操作的具体步骤。讨论了事务在NoSQL数据库中的应用及其可能带来的性能影响。
介绍了MongoDB 4.0版本如何实现事务支持,包括原子性、一致性等特性,并提供了通过mongoshell进行事务操作的具体步骤。讨论了事务在NoSQL数据库中的应用及其可能带来的性能影响。

关系型数据库对事务之间的关系是无法拆分的关系,提到关系型数据库最重要的解决的问题就是事务。MONGODB 之前被人一直无法在核心数据库上应用的时,被攻击的问题就是事务,事务中最重要的原子性,在MONGODB的多collection是无法被满足的。
Mongodb的事务是从什么时间开始的,4.0 ,对4.0 到底MONGODB 怎么就支持事务了,这种事务对处理数据和业务有什么帮助。
实际上事务中的原子性,完整性,可持久性,一致性, ACID 在MONGODB4.0 是存在的,这里MONGODB 的事务完成,提到了复制集合,并且是标注粗体的。

多文档操作的事务是跨 “多个操作”,文档, collection, 数据库,这是MONGODB 在4.0后的支持事务提出的概念和可支持的对象。
传统数据库本身我们对事务如果细致的拆分,也是针对,多个操作,多行,多个表,甚至是多个数据库之间(部分RDMBA 也不存在多数据库之间)
进行 ACID 的操作。
这样的意思我可以理解为,MONGODB 引入了 “REDO”, "UNDO", rollback, 在MONGODB 事务内的操作要么全部成功,要么全部失败, 一切都在commit 的时刻后,事务所做的操作才能被展现,也就是说 MONGODB 也支持MVCC 多版本控制了。
往深入去考虑,如果使用MOGNODB的事务操作,也会有大事务,大事务会带来更多的写入成本,所以这里有一个点,我们会用MONGODB 来做大事务吗?MONGODB 文档中通过IMPORTANT 方式注明了

其中指明了,事务操作会引起性能方面的消耗(greater performance),并且不能因为有了事务,我们就把mongodb 当传统数据库使用,即使是传统数据库,大事务等等也是我们在使用中避免甚至对有些RDBMS是禁止的。
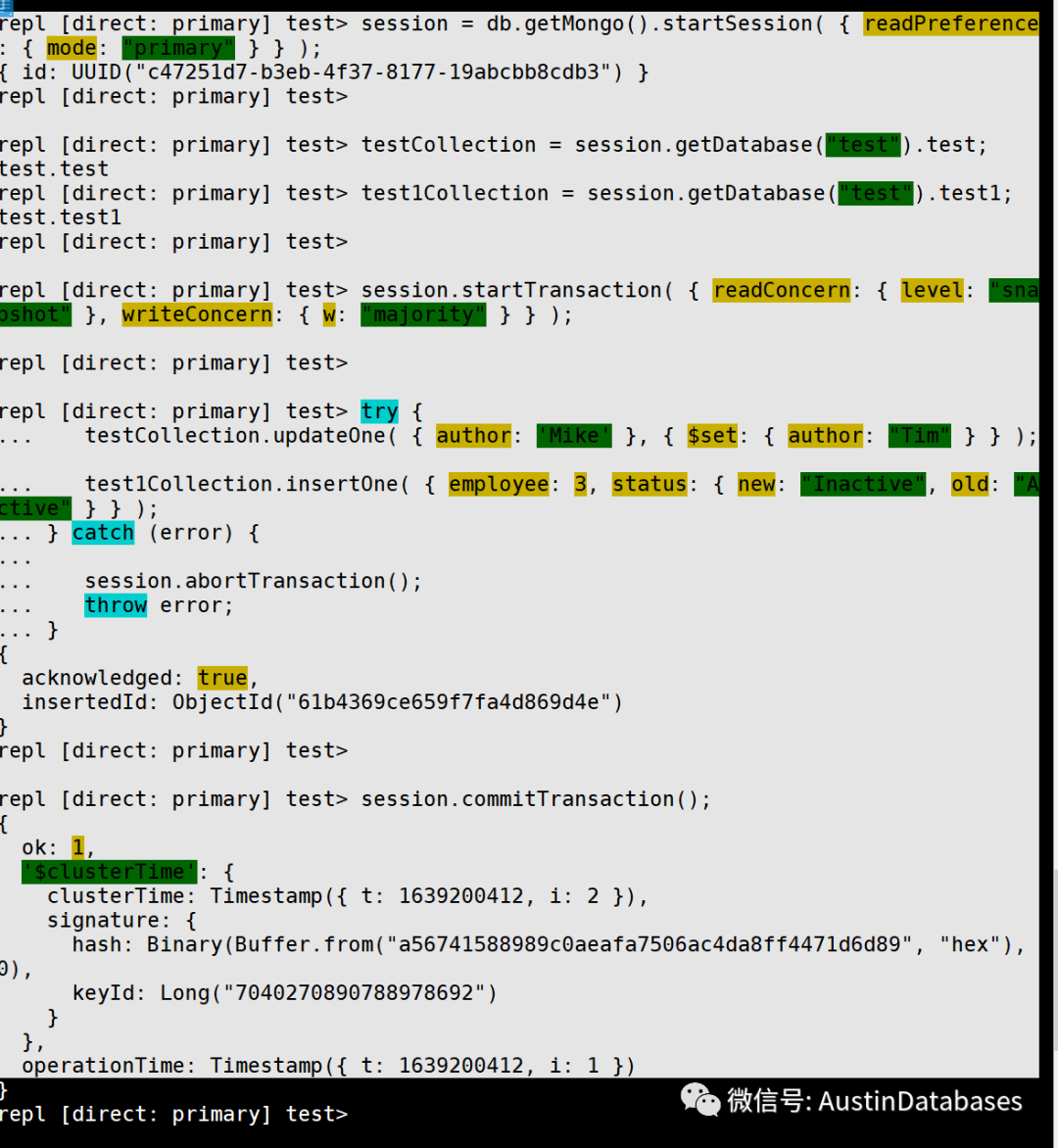
那我们看看MOGNODB 的事务是怎么操作的,次此操作通过mongo shell完成,如需操作请下载mongoshell 通过 mongosh 完成
1 打开session
session = db.getMongo().startSession( { readPreference: { mode: "primary" } } );
2 将需要操作的collection 进行变量绑定
testCollection = session.getDatabase("test").test;
test1Collection = session.getDatabase("test").test1;
3 开始事务标注,指定MVCC的模式,写模式
session.startTransaction( { readConcern: { level: "snapshot" }, writeConcern: { w: "majority" } } );
4 操作封装,将需要一次执行的事务封装
try {
testCollection.updateOne( { author: 'Mike' }, { $set: { author: "Tim" } } );
test1Collection.insertOne( { employee: 3, status: { new: "Inactive", old: "Active" } } );
} catch (error) {
session.abortTransaction();
throw error;
}
5 提交事务
session.commitTransaction();
6 关闭session
session.endSession();
执行结果
产生session ,执行后给session 分配唯一的ID
repl [direct: primary] test> session = db.getMongo().startSession( { readPreference: { mode: "primary" } } );
{ id: UUID("c47251d7-b3eb-4f37-8177-19abcbb8cdb3") }
赋值变量,声明要操作的的collections
repl [direct: primary] test> testCollection = session.getDatabase("test").test;
test.test
repl [direct: primary] test> test1Collection = session.getDatabase("test").test1;
test.test1
repl [direct: primary] test> session.startTransaction( { readConcern: { level: "snapshot" }, writeConcern: { w: "majority" } } );
repl [direct: primary] test> try {
... testCollection.updateOne( { author: 'Mike' }, { $set: { author: "Tim" } } );
... test1Collection.insertOne( { employee: 3, status: { new: "Inactive", old: "Active" } } );
... } catch (error) {
...
... session.abortTransaction();
... throw error;
... }
对事务中插入的document 产生 objectId
{
acknowledged: true,
insertedId: ObjectId("61b4369ce659f7fa4d869d4e")
}
提交事务后告知事务成功运行,以及事务运行的时间戳
repl [direct: primary] test> session.commitTransaction();
{
ok: 1,
'$clusterTime': {
clusterTime: Timestamp({ t: 1639200412, i: 2 }),
signature: {
hash: Binary(Buffer.from("a56741588989c0aeafa7506ac4da8ff4471d6d89", "hex"), 0),
keyId: Long("7040270890788978692")
}
},
operationTime: Timestamp({ t: 1639200412, i: 1 })
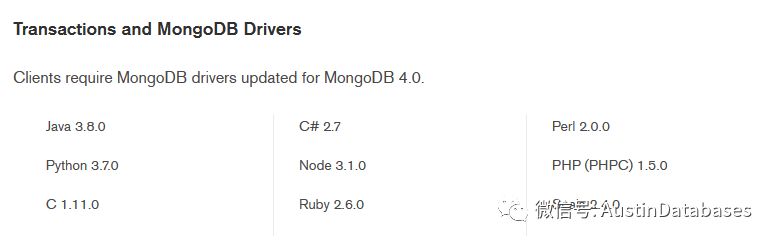
mongodb 操作事务的方式支持 java , python C# 等等具体的版本和语言在下图
本期先到这里,下一期的说说 MONGODB 的事务的参数和注意事项


















 953
953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









