



 文章围绕MySQL展开,深入讲解其锁机制与索引的关系。介绍了MVCC、聚簇索引和二级索引、索引下推等概念,通过不同Update语句和查询语句的示例,分析了在各种情况下索引与锁的操作,指出因MySQL二级索引的ICP下推特性,看似无关的语句可能产生死锁。
文章围绕MySQL展开,深入讲解其锁机制与索引的关系。介绍了MVCC、聚簇索引和二级索引、索引下推等概念,通过不同Update语句和查询语句的示例,分析了在各种情况下索引与锁的操作,指出因MySQL二级索引的ICP下推特性,看似无关的语句可能产生死锁。
 最近读了一篇关于MYSQL的文章,主要是更深入化的讲解MYSQL的锁机制,写的真是好。但里面细细的读,发现一个问题,索引的问题,一般我们都人为索引是我们查询中的救星,他可以帮助我们摆脱,全表扫描,加快查询的速度,让查询更快减少系统性能上的瓶颈。
最近读了一篇关于MYSQL的文章,主要是更深入化的讲解MYSQL的锁机制,写的真是好。但里面细细的读,发现一个问题,索引的问题,一般我们都人为索引是我们查询中的救星,他可以帮助我们摆脱,全表扫描,加快查询的速度,让查询更快减少系统性能上的瓶颈。
其实我之前也是这么人为的,期间我知道的是,索引会引起插入,UPATE 性能的问题,看完这篇文字,我深刻的理解到,之前的一些想法的浅薄。
我到底浅薄在哪里,索引的灾星又是在哪里体现的。
我们需要确定及格事情
1 MVCC 是多少 (不知道MVCC 是何物的 DBA 可以退休了)
2 聚簇索引 和 二级索引 (ORACLE, PG 的DBA 对聚簇索引应该是陌生的)
3 索引下推
下面我们就开始再次重新认识一下,索引和锁之间的关系
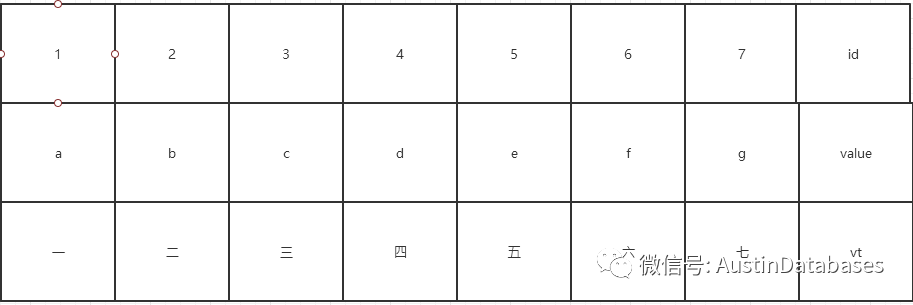
上面是一个表,有三个column , id 是主键并且是聚簇索引, value上建有索引,前提的情况的交代, MVCC 是 read commited
情况1
Update 语句更新 (Update 更新等值情况,并且有索引的情况)
update table set value = 'w' where ID= 2;
1 首先把ID =2 的聚簇索引记录上加 x 锁
2 把对应该聚簇索引记录对应的二级记录加锁
然后更新数据
情况 2
Update 语句更新 (Update 不等值的情况)
update table set value = 'w' where ID <= 2;
ICP 索引下推,主要的功能是根据查询条件,直接在INNODB 存储引擎中进行判断,而不再将信息返回到server层在判断。前提是二级索引,因为聚簇索引数据本身就在里面了,不需要回表。
上面的例子是直接在聚簇索引上进行判断,但和第一个更新哪里不一样,问题在于索引下推,上面的例子不存在索引下推,1 查询的是主键 2 是等值计算。 现在的查询不是,虽然在主键,但是一个范围查询,所以在查询时就需要在找到 Id = 1 由于是主键并且是聚簇索引,所以就没有索引下推的在INNODB数据层进行,符合的结果会返回SERVER 层 然后在判断,原因是没有进行ICP下推查询的会在SERVER 层在判断一遍,然后释放相关的锁。
但这里有一个小问题,
就是在锁定ID =2 的时候,需要先锁定 ID =3 原因是要从最后一个不符合要找的记录开始。
所以就有下面的死锁问题了
Session 1
Begin;
update table set vt = “十” where id = 3;
..
..
Session 2
Begin;
select * from table where id <=2;
..
看似不搭嘎的两个Session 由于刚才的那个锁,产生了死锁,然后SESSION 2 就有可能被牺牲掉。
这就是有的时候,看似两个无关的语句,但最后产生死锁的原因。
情况3 ,我们把情况弄的复杂一些
update table set value = 't' where id <= 2;
我们根据上面的问题可以继续分析这条语句,
1 ID = 3的先X 锁,然后马上释放
2 ID = 2 ,的记录上锁X 锁
3 由于更新的值是索引,所以需要对索引VALUE 对应的 ID = 2 的位置也上X锁
4 ID =1 的记录上X 锁
5 对ID=1 的 索引 VALUE 加X 锁
此时如果同时还有一个语句
我们有一个查询语句
select * from table where value = 2;
则会对value =2 的索引先加S 锁,在对注记录加 S锁,(如果 select 不是* 的情况,查询的值都包含在索引,那又是另一个情况)
则和上面的语句冲突,update语句是 先占 主键,在占索引, 而下面的查询语句是先先占索引,在去占主键,
则这两个语句就冲突了,死锁,查询语句牺牲。
如果换另外的查询语句 select * from table where value >2
则根据使用索引ICP的原则,下推的原则 id =1 会被锁,则和上面的update table set value = 't' where id <= 2; 会有可能进行互锁,虽然看似之间不应该有锁之间的冲突。
所以综上所述,由于MYSQL二级索引又下推的处理过程,ICP,所以看似不可能有锁的语句之间可能会因为这个特性,产生死锁。

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









