




 本文总结了深度学习的基础技巧,包括选择合适的损失函数,如平方损失和交叉熵损失;小批量样本的使用,解释了随机梯度下降、批量梯度下降和动量优化;还介绍了防止过拟合的方法,如早停、Dropout,并探讨了卷积神经网络(CNN)和池化层的作用。
本文总结了深度学习的基础技巧,包括选择合适的损失函数,如平方损失和交叉熵损失;小批量样本的使用,解释了随机梯度下降、批量梯度下降和动量优化;还介绍了防止过拟合的方法,如早停、Dropout,并探讨了卷积神经网络(CNN)和池化层的作用。
点击下方图片查看HappyChart专业绘图软件

深度学习基本技巧
选择合适的损失函数
- 平方损失
- 交叉熵损失
- …
小批量样本(mini-batch)
首先打乱数据,然后选择合适的小批量样本,重复epoch次。例如样本量100, 小批量mini-batch样本为20,epoch为10。则先打乱这100个样本,顺序选取20个样本,更新一次参数,然后再选取下20个样本,再更新一次参数,直到把100个样本选取完,这样重复epoch(10)次。
其他的可以使用随机梯度下降为一个一个的选择样本更新参数,而批量梯度下降使用全部样本更新一次参数。
##使用新的激活函数
常用的为sigmoid, tanh。
ReLU(Rectified Linear Unit)

ReLU的变体
LeakyReLU

parametric ReLU

其中,
α
\alpha
α由梯度下降法学习
#Maxout

适应性学习率(adaptive learning rate)
仔细设置学习率,如果学习率偏大,则每次更新后总损失不会下降,而学习率偏小时,训练会很慢。
简单却流行的算法为学习率随着时间变化而减小,
η
t
=
η
t
+
1
\eta^{t} = \frac{\eta}{\sqrt{t+1}}
ηt=t+1η。
Adagrad
w
←
w
−
η
w
∂
L
/
∂
w
w \leftarrow w -\eta_{w}\partial L / \partial w
w←w−ηw∂L/∂w
η
w
=
η
Σ
i
=
0
t
(
g
i
)
2
\eta_{w}=\frac{\eta}{\sqrt{\Sigma_{i=0}^t(g^i)^2}}
ηw=Σi=0t(gi)2η
其中,
η
\eta
η为常数,
g
i
g^i
gi为在第i次更新时的
∂
L
/
∂
w
\partial L / \partial w
∂L/∂w
算法:

RMSprop
算法:


Adam
算法:

动量(Momentum)
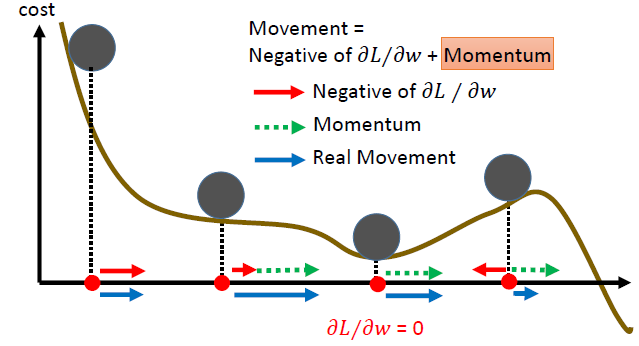
如上图,在物体运动的时候会有一个惯性,即使没有力的作用物体还是会向前运动一段距离,这虽然不能保证到达全局最小值,但给出了一些希望。
而RMSprop算法就是adagrad与momentum的结合。
防止过拟合的技巧
防止过拟合的基本想法就是增加训练数据集,或创造出更多的训练集,但是有时获取更多的训练集有一定难度或成本很高,所以也可以使用其他的办法防止神经网络过拟合。
早停(Early stopping)
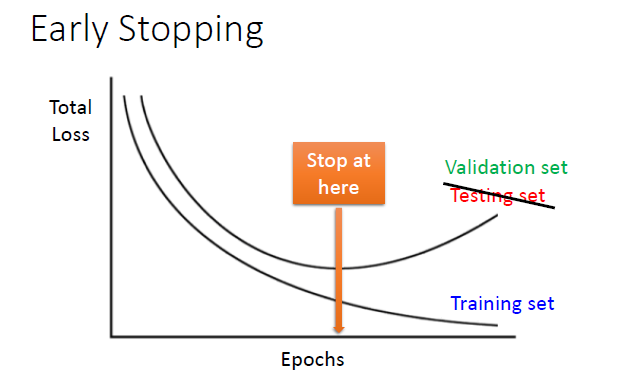
从上图看出,把原始数据集分为训练集,验证集与测试集,训练集训练,总损失减小,而验证集总损失先下降后增加,而早停就是在验证集的损失最小的时候停止训练,然后把获得的模型应用到测试集上。
##正则化(Regularization)
权重衰减是正则化的一种,原始的梯度下降法为:
w
←
w
−
η
∂
L
/
∂
w
w \leftarrow w -\eta\partial L / \partial w
w←w−η∂L/∂w
权重衰减为:
w
←
(
1
−
λ
)
w
−
η
∂
L
/
∂
w
w \leftarrow (1-\lambda)w -\eta\partial L / \partial w
w←(1−λ)w−η∂L/∂w
λ
\lambda
λ可以为0.01
Dropout
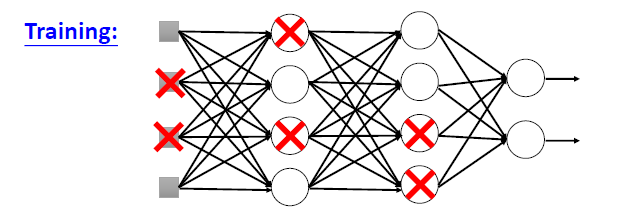
每次更新参数前有p%的神经元被dropout,这时网络的结构就发生了变化:
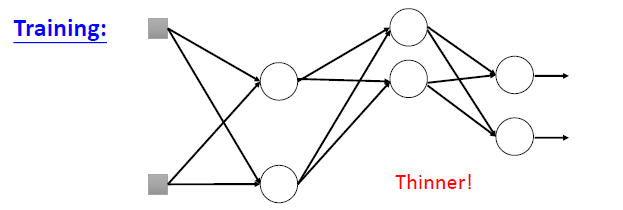
如果训练的dropout为p%,则所有的权重要乘以(1-p)%
新的网络结构
如CNN,RNN等
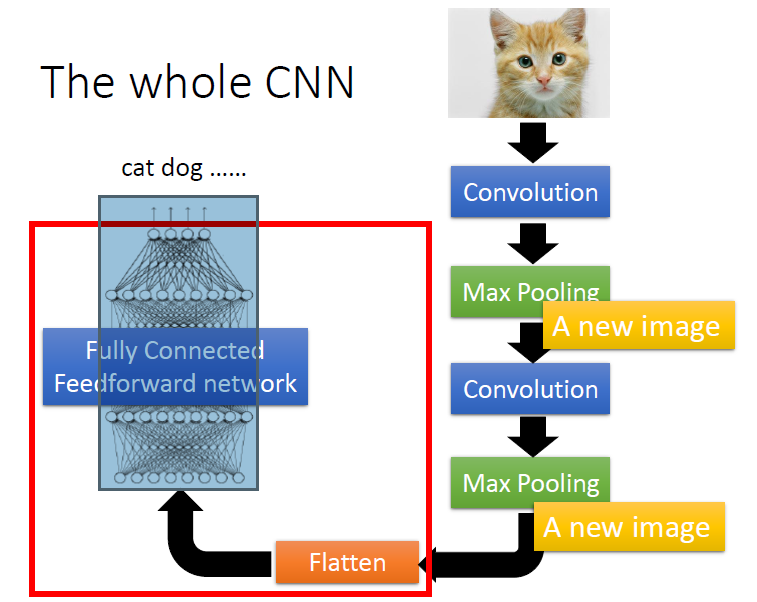
CNN(Convolutional Neural Network)
CNN主要用于处理图像问题。
假设一个
6
×
6
6\times 6
6×6的图像:
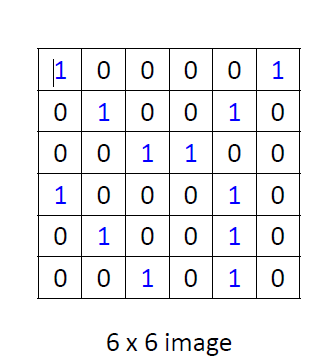
卷积核(convolutional kernel)也即filter为:
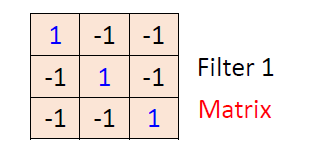
即卷积核的大小为
3
×
3
3\times 3
3×3。
使用上面的卷积核对图片做卷积,假设步长(stride)为1:
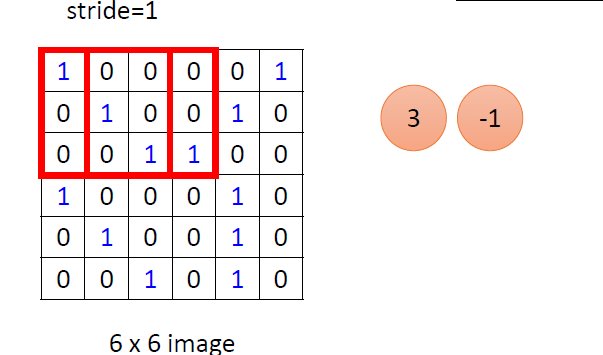
由上图知,对应元素相乘。
最终得到的卷积后的特征图片为:
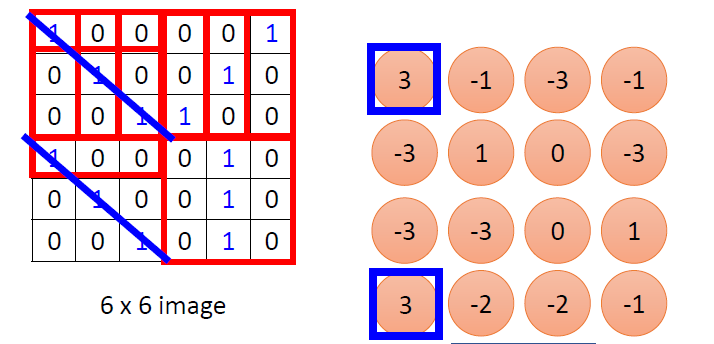
可以设置不同的卷积核及其大小,卷积核的个数有时也称为通道数。
Padding
即在图片的边缘添加元素0,一般有‘valid’和’same’两种 。
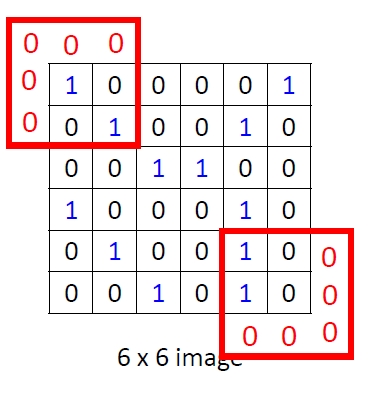
在计算特征图片大小时,假设
图片大小:
H
×
H
H\times H
H×H
filter大小:
F
×
F
F\times F
F×F
padding:P
stride:S
则计算公式为:
H
−
F
+
2
P
S
+
1
\frac{H-F+2P}{S}+1
SH−F+2P+1
池化层(Pooling)
池化层包括Max Pooling 和Avg Pooling等
由上面可知,由Filter 1得到特征图为:
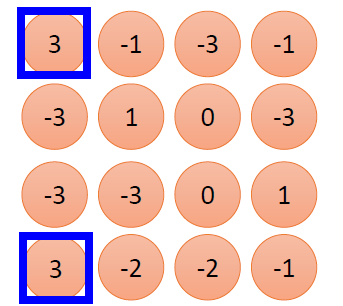
假设Max Pooling的大小为 2 × 2 2\times 2 2×2,
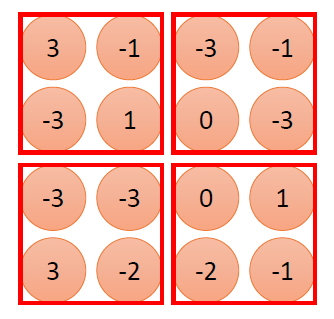
则从上图中求出各个 部分的最大值。
重复上述步骤多次后,最后把得到的特征扁平化:
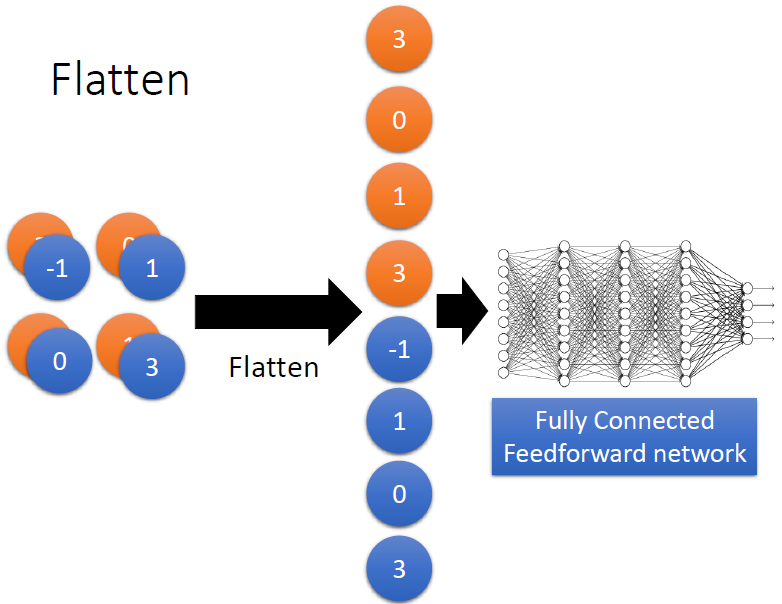
整个过程为:

















 36万+
36万+




 到【灌水乐园】发言
到【灌水乐园】发言







