




bp神经网络也即误差后向传播神经网络,顾名思义,即误差是向后传播的。但是对于信号的传播是正向的。
bp神经网络由一个输入层,一个或多个隐含层和一个输出层组成,每层有一些单元组成,输入层的单元称为输入单元,隐层和输出层的单元称为神经节点或者输出单元,它们的网络是全连接的。
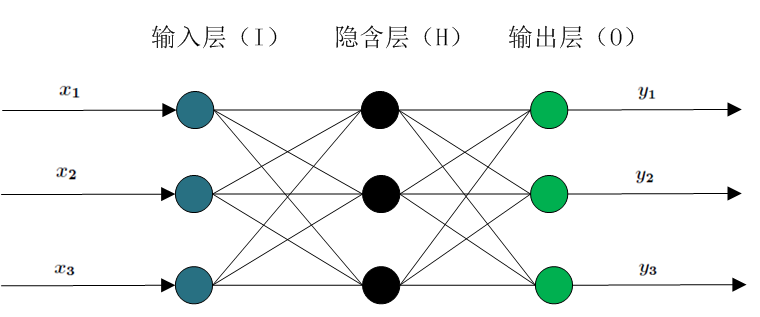
神经网络可以用于分类和数值预测,对于分类,一个输出单元可以用来表示两个类,如果多于两个类,则每个类使用一个输出单元。
向前传播输入
首先,训练元组通过输入单元进行输入,此时的输入IjI_jIj也就是输入层的输出OjO_jOj,没有变化,也没有偏移量。而对于隐藏层和输出层,每个隐藏层或输出层单元都是上一层单元的输出,即每个上一层单元输出的加权和再加上偏移量就是这一层的输入。即,给定隐藏层或输出层的单元j,到单元j的净输入IjI_jIj为:
Ij=ΣiwijOi+θjI_j=\Sigma_iw_{ij}O_i+\theta_jIj=ΣiwijOi+θj
其中,wijw_{ij}wij是上一层单元i到这一层单元j的链接权重;OiO_iOi为上一层单元i的输出;θj\theta_jθj为单元j的偏移量,偏移量充当阈值。
然后将隐藏层或输出层的输入使用激活函数激活,变成本层的输出,一般使用S函数或logistic函数作为激活函数,给定单元j的净输入IjI_jIj,则单元j的输出OjO_jOj为:
Oj=11+e−IjO_j = \frac{1}{1+e^{-I_j}}Oj=1+e−Ij1
后向误差传播
由于得到的输出结果可能与目标结果有很大的差距,所以根据他们的误差反过来修正权重和偏倚,从而使得输出结果与目标结果非常接近。
对于输出层单元j,误差ErrjErr_jErrj用下式计算:
Errj=Oj(1−Oj)(Tj−Oj)Err_j = O_j(1-O_j)(T_j-O_j)Errj=Oj(1−Oj)(Tj−Oj)
其中,OjO_jOj是单元j的实际输出,TjT_jTj是j给定元组的已知目标值,注意,Oj(1−Oj)O_j(1-O_j)Oj(1−Oj)是logistic函数的导数,即f′(x)=f(x)(1−f(x))f'(x)=f(x)(1-f(x))f′(x)=f(x)(1−f(x)).
对于隐藏层单元j,考虑与下一层(即后一层,可能是输出层也可能是隐藏层)中连接J的单元误差加权和,隐藏层单元j的误差为:
Errj=Oj(1−Oj)ΣkErrkwjkErr_j=O_j(1-O_j)\Sigma_kErr_kw_{jk}Errj=Oj(1−Oj)ΣkErrkwjk
其中,wjkw_{jk}wjk是隐藏层单元j到下一层单元k的权重,而ErrkErr_kErrk是下一层单元k的误差。比如最后一层隐藏层的单元j和输出层单元k。
更新权重和偏倚,以反映误差的传播。权重使用下式更新:
△wij=lErrjOiwij=wij+△wij\triangle w_{ij}=lErr_jO_i\\
w_{ij}=w_{ij}+\triangle w_{ij}△wij=lErrjOiwij=wij+△wij
其中,△wij\triangle w_{ij}△wij为权重该变量,lll为学习率。
偏倚更新如下:
△θj=lErrjθj=θj+△θj\triangle \theta_j=lErr_j\\
\theta_j = \theta_j+\triangle \theta_j△θj=lErrjθj=θj+△θj
这里每处理一个样本就更新权重和偏倚,这叫做实例更新。而权重和偏倚的增量可以积累到变量中,使得处理完训练集的所有样本之后再更新,这种策略称为周期更新,实践中,实例更新更常见,它能产生更精确的结果。
终止条件:
- 前一周期所有的△wij\triangle w_{ij}△wij都太小,小于指定的阈值
- 前一周期误分类的元组百分比小于某个阈值
- 超过预先指定的周期数
在实践中,网络收敛的时间非常不确定,可以使用模拟退火的技术加快训练速度,并确保收敛到全局最优。
为了对未知元组X的分类,把该元组输入到训练后的网络中,计算每个单元的净输入与输出,如果每个类有一个输出节点,则具有最高输出值的节点决定X的预测类标号,如果只有一个输出节点,则输出值大于0.5的可视为正类,小于0.5的可视为负类。
bp算法
输入:
D:包含目标值的训练集
l:学习率
**输出:**训练后的神经网络
方法:
初始化网络的所有权重和偏倚
while 种植条件不满足{
\quadfor D中每个训练元组X{
\quad\quad//前向传播输入
\quad\quadfor每个输入层单元j{
\quad\quad\quadOj=Ij;O_j=I_j;Oj=Ij; //输入单元的输出是它的实际输入值}
\quad\quadfor 隐藏或输出层的每个单元j{
\quad\quad\quadIj=ΣiwijOi+θjI_j=\Sigma_iw_{ij}O_i+\theta_jIj=ΣiwijOi+θj;//关于前一层i,计算单元j的净输入
\quad\quad\quadOj=1/(1+e−Ij);//计算单元J的输出O_j=1/(1+e^{-I_j});//计算单元J的输出Oj=1/(1+e−Ij);//计算单元J的输出}
\quad\quad//后向传播误差
\quad\quadfor 输出层的每个单元j{
\quad\quad\quadErrj=Oj(1−Oj)(Tj−Oj);Err_j=O_j(1-O_j)(T_j-O_j);Errj=Oj(1−Oj)(Tj−Oj);//计算误差}
\quad\quadfor 由最后一个到第一个隐藏层,对于隐藏层的每个单元j{
\quad\quad\quadErrj=Oj(1−Oj)ΣkErrkwjk;Err_j=O_j(1-O_j)\Sigma_kErr_kw_{jk};Errj=Oj(1−Oj)ΣkErrkwjk;//计算关于隐藏层单元J的误差}
\quad\quadfor 网络中的每个权重wijw_{ij}wij{
\quad\quad\quad△wij=lErrjOi\triangle w_{ij}=lErr_jO_i△wij=lErrjOi;//权重增量
\quad\quad\quadwij=wij+△wijw_{ij}=w_{ij}+\triangle w_{ij}wij=wij+△wij;//权重更新}
\quad\quadfor 网络中每个偏倚θij\theta_{ij}θij{
\quad\quad\quad△θj=lErrj;\triangle \theta_j=lErr_j;△θj=lErrj;//偏倚增量
\quad\quad\quadθj=θj+△θj\theta_j = \theta_j+\triangle \theta_jθj=θj+△θj;//偏倚更新}
\quad}
}

















 4611
4611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









