







 本文介绍了Elasticsearch在Linux环境中的基本操作,包括数据模型、PUT、POST、GET等操作。详细讲解了如何创建、更新、删除和查询文档,以及批量操作和各种查询方式的应用。
本文介绍了Elasticsearch在Linux环境中的基本操作,包括数据模型、PUT、POST、GET等操作。详细讲解了如何创建、更新、删除和查询文档,以及批量操作和各种查询方式的应用。
一、ES数据模型简介
Elasticsearch是一个实时的分布式搜索和分析引擎,它可以处理大规模数据的速度。
1、基础数据模型
Index : 索引,由多个Document组成
Type : 索引类型
Document : 文档,由多个Field组成
Field : 字段,包括字段名与字段值,对应数据库中的字段
2、 Document管理
ps:文档是ES最小数据单元
1) 原始数据
_source:原始JSON格式文档
2) 文档元数据
_index:索引名
_type:索引类型
_id:文档编号
_version:文档版本号用于并发控制
_score:在搜索结果中的评分
3)文档的基本操作
PUT 创建
POST 创建、修改(增加、删除、修改)
DELETE 删除
GET 查询
二、PUT操作
PUT 一般用于插入数据,也可用于更新,但是会使得更新的字段替换原有的所有字段,如果无需全部替换不建议使用;也可用于创建索引
用法:
PUT 索引/类型
{
JSON串
}
PUT 索引/类型/类型的编号
{
JSON串
}
eg:

 PS:一个索引下只能存在一种类型
PS:一个索引下只能存在一种类型
三、POST
POST 一般用于更新数据、删除数据,以及批量插入数据
1、更新数据:
POST /索引/类型/编号/_update
{
“doc”:{
列名:值------------>精准修改
}
}
eg:

执行结果:
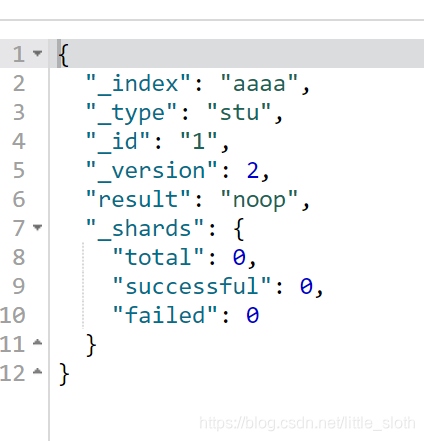
修改后的数据:
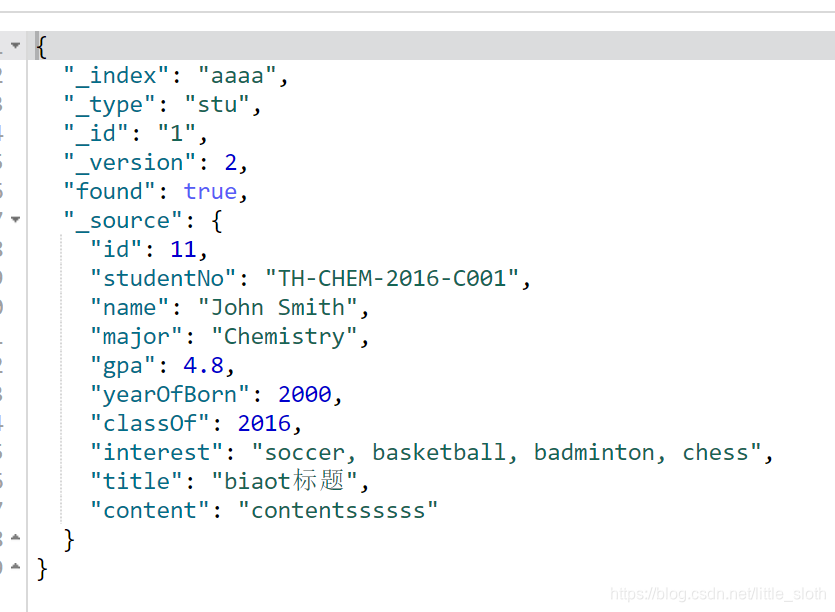
2、批量插入数据:
POST /_bulk ----代表批量操作
ps:必须写在同一行 ,create语句一行,json串一行
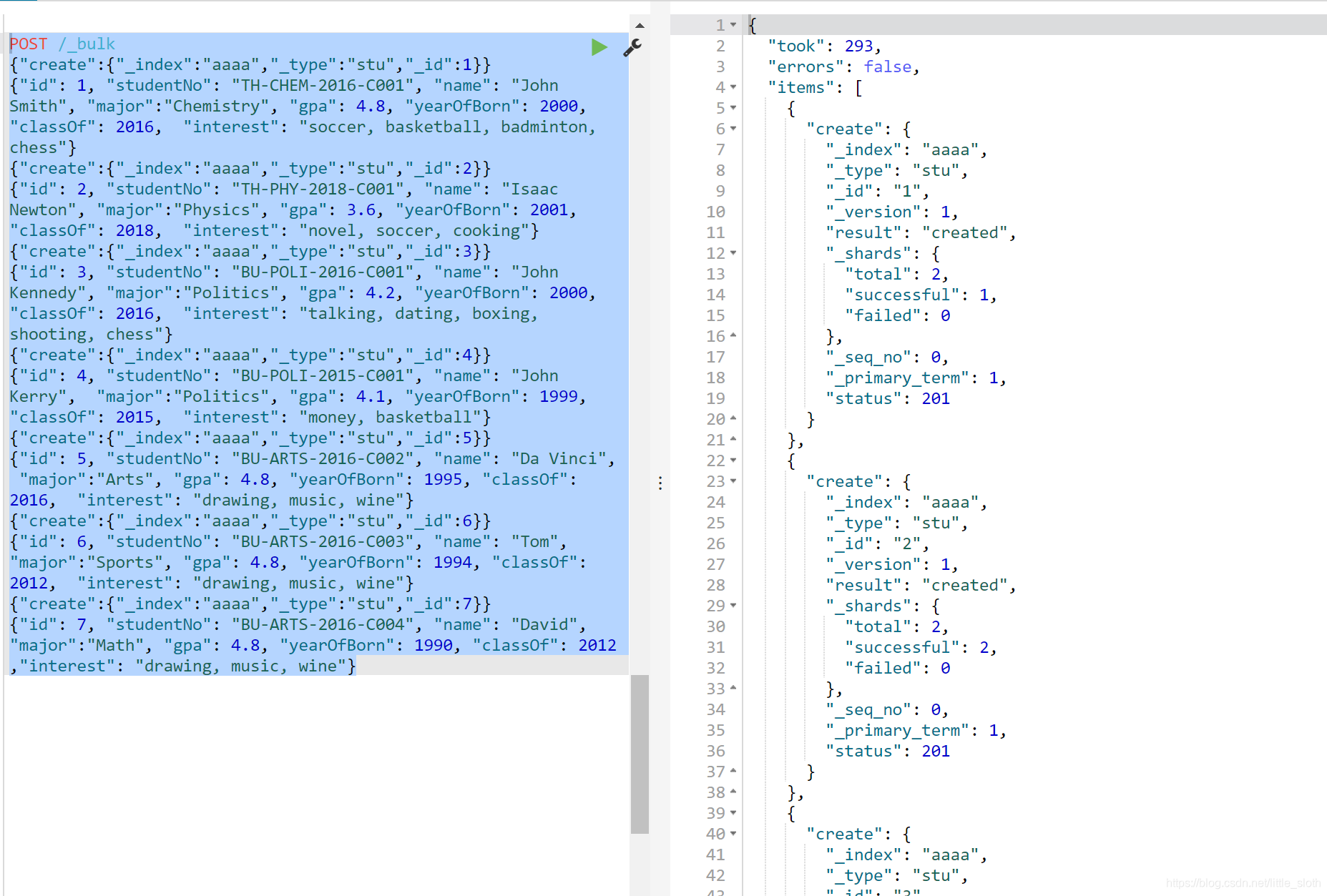
- 创建:
{“create“:{“_index”:索引,“_type”:类型,”_id”:编号}}
{json串}
eg:
2)、 删除数据
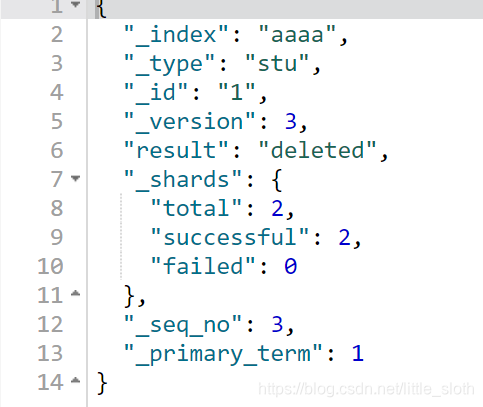
{“delete“:{“_index”:索引,“_type”:类型,”_id”:编号}}-----指定编号
eg:

或者:
delete 索引/类型/编号 -----指定编号
eg:

执行结果:
3)更新数据
{“updata“:{“_index”:索引,“_type”:类型,”_id”:编号}}
eg:
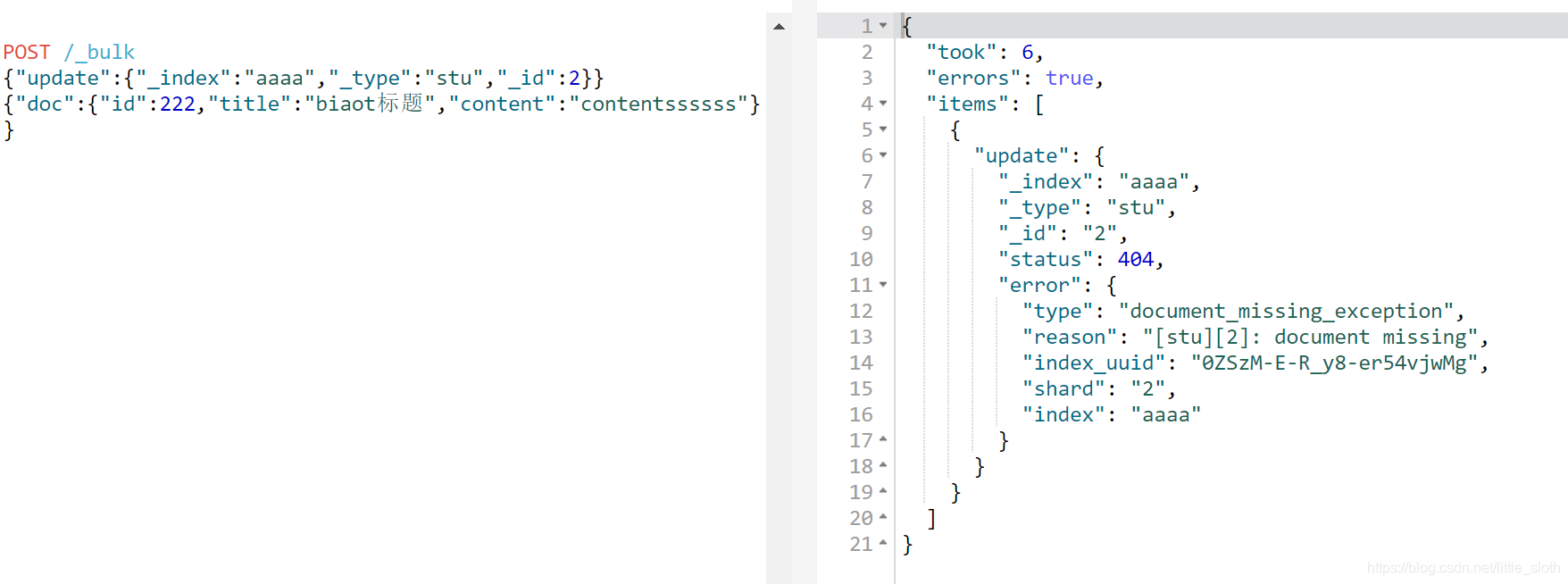
或者

四、GET
- GET /索引/类型/_search ----------查询所有
{“query“:{“match_all”:{}}}
eg:
GET /aaaa/stu/_search
{
"query": {
"match_all": {}
}
}
-
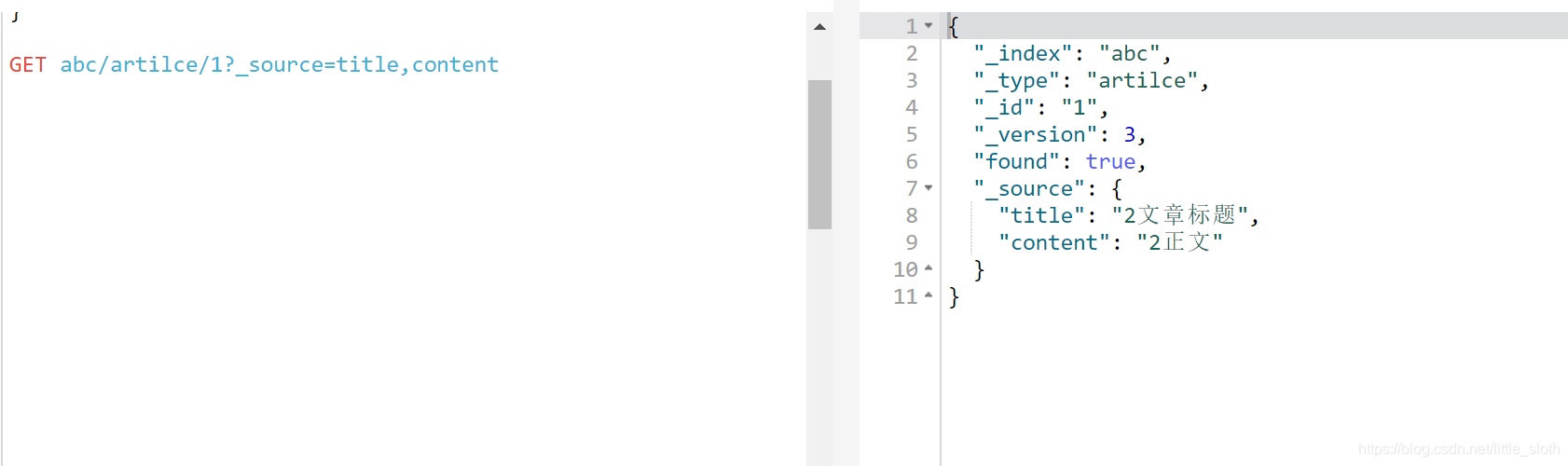
GET /索引/类型/1?_source=字段列表1,字段列表2
用于查询指定字段
eg:
-
GET /索引/类型/_search
1)match类
{“query”:{
“match”:{json串}
}
}
eg:
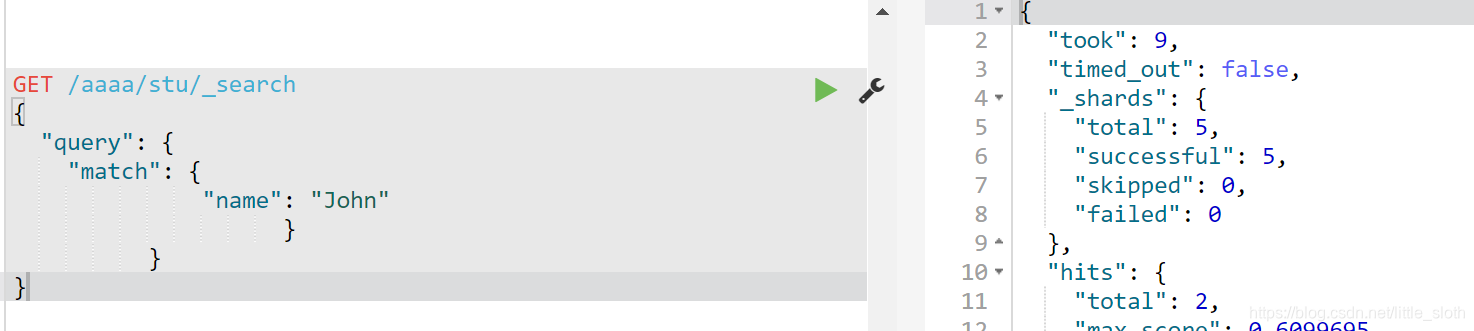
ps: 对查询字符串进行分词,根据分词结果构造布尔查询,字段中包含John就行
match_phrase:短语匹配查询,对查询字符串进行分词,字段值必须依次匹配所有分词,各分词位置不能改变
match_phrase_prefix:短语前缀匹配查询,最后一个分词作为前缀匹配
multi_match:多字段匹配查询
eg:

ps:multi_match 是模糊查询,只要包含fields中的字段包含了query中字段的都能匹配出来 -
term/terms:词条查询
按照存储在倒排索引中的确切字词,对字段进行匹配
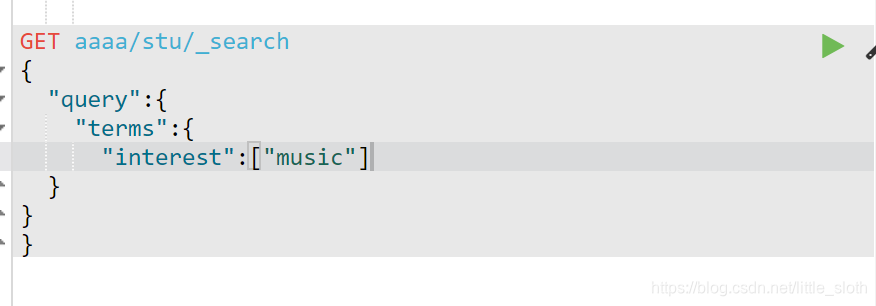
ps:不支持多字段查询,[]必须有,如果字段多个值匹配用terms,单个字段值可以用term
3)range:范围查询
eg:
GET aaaa/stu/_search
{
"query": {
"range" : {
"yearOfBorn":{
"gte":1995,
"lte":2000
}
}
}
}
- bool:布尔查询------must \ must not \should
eg:
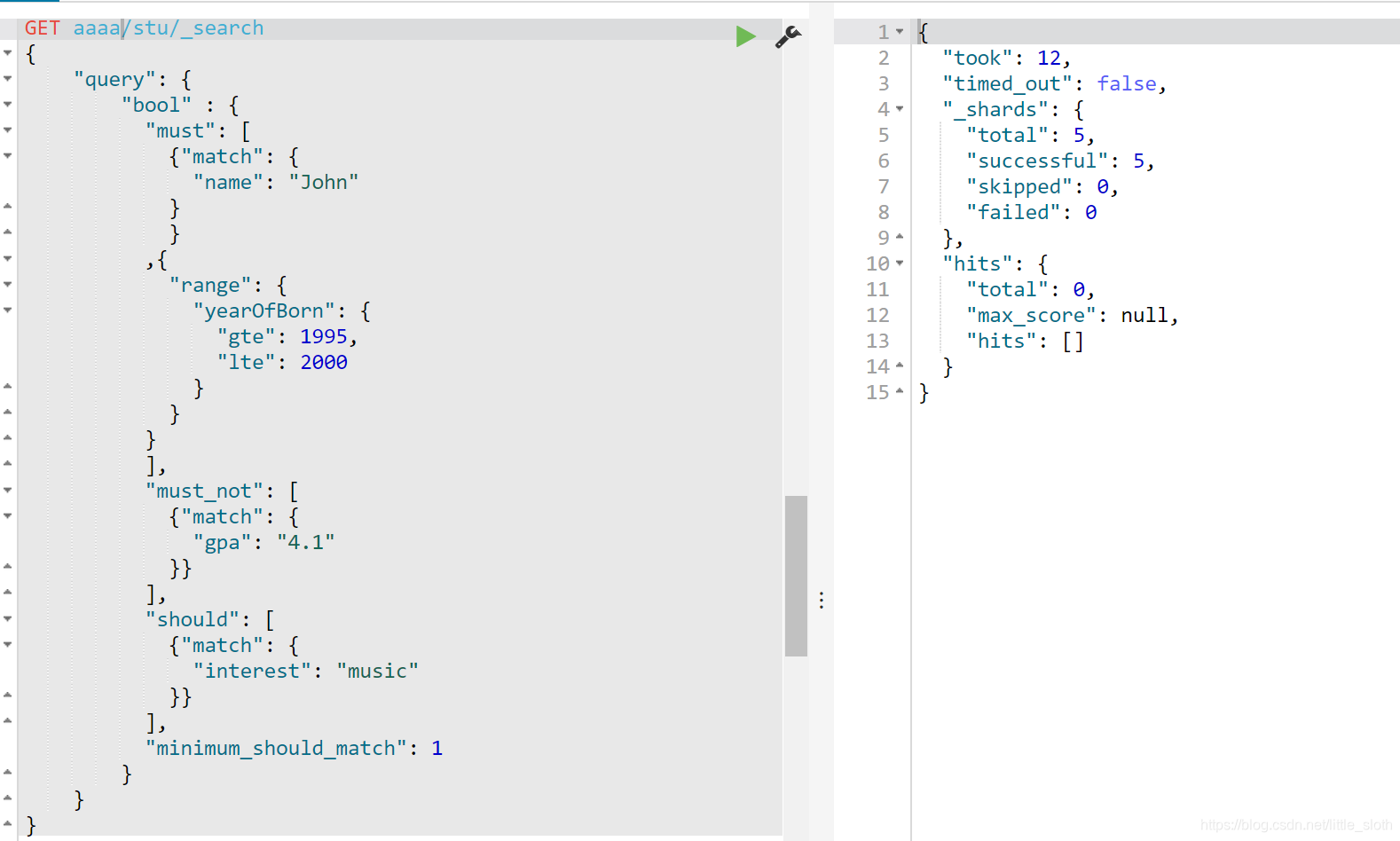
ps:should查询的值可以为空,返回的是结果数,返回结果为0不影响查询语句的执行,可以通过规定返回结果数进行设置
5)from+size浅分页
eg:
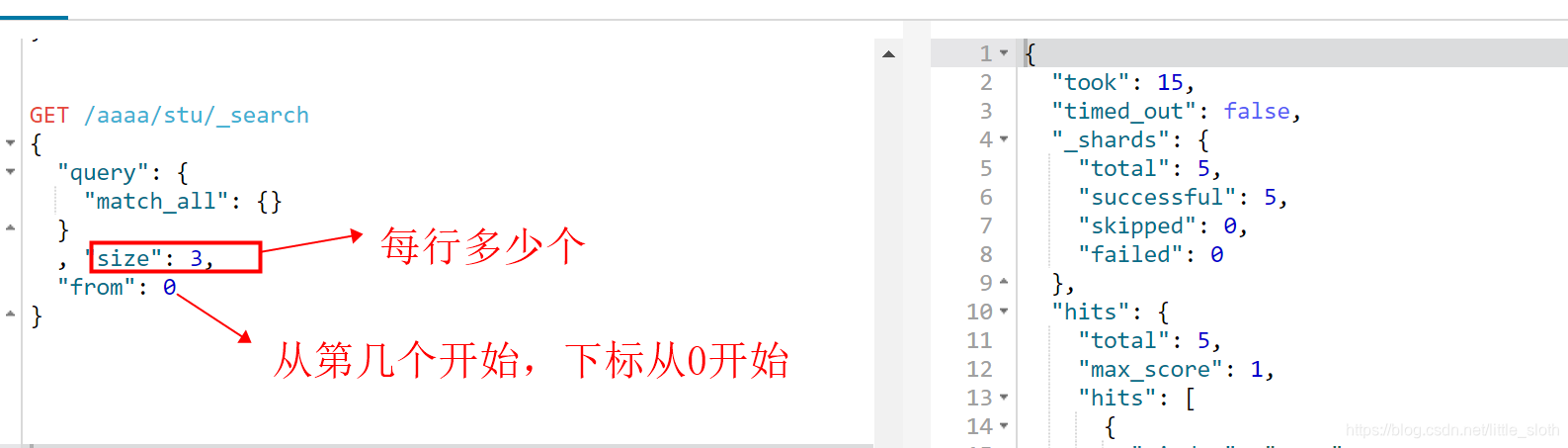
- scroll深分页
保存结果快照,需要分页时,直接从结果中获取
eg:
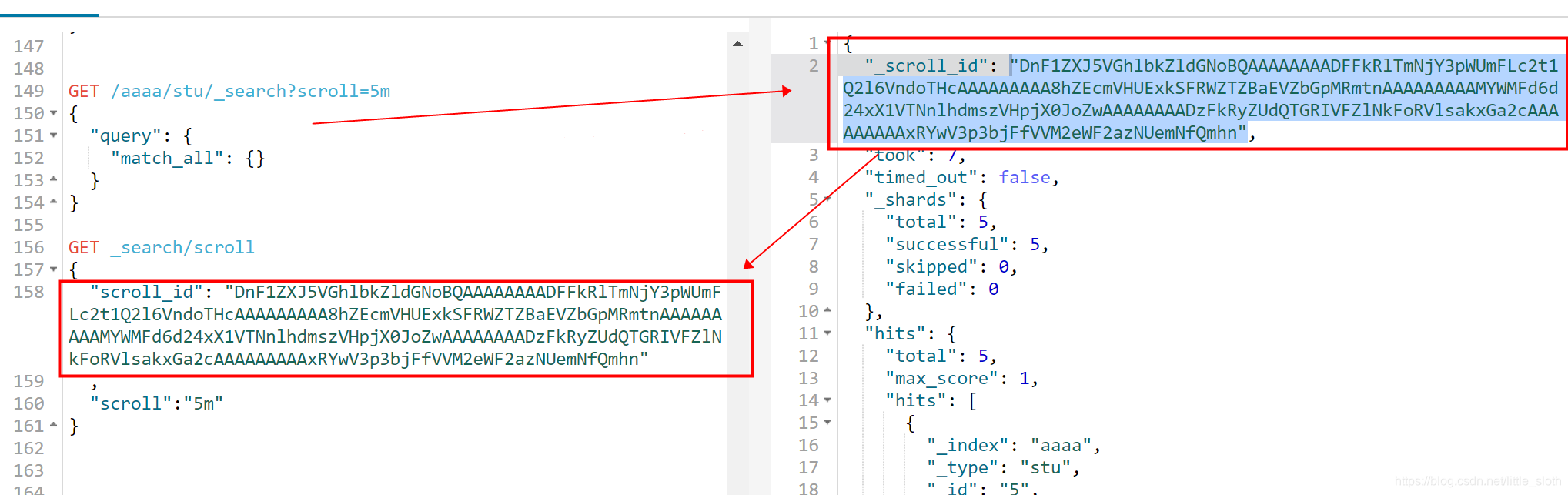

















 548
548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









