



 FastR-CNN解决了R-CNN在目标检测中的速度与效率问题,通过改进的RoI池化层减少计算冗余,同时整合分类与回归任务,提升模型训练与测试速度。
FastR-CNN解决了R-CNN在目标检测中的速度与效率问题,通过改进的RoI池化层减少计算冗余,同时整合分类与回归任务,提升模型训练与测试速度。
Fast R-CNN的提出解决了目标检测发展历程中存在的重要问题,我们想要很好的理解Fast R-CNN必须对之前的论文有所了解(R-CNN,spp-net)。
R-CNN回顾
首先,我们回顾一下R-CNN:
简单来说,RCNN使用以下四步实现目标检测:
a. 利用selective search,在图像中确定约2000个候选框 (region proposal)
b. 对于每个候选框内图像块,使用深度网络提取特征 (2000个候选框即要重复2000次深度网络特征提取,计算冗余)
c. 对候选框中提取出的特征,使用分类器判别是否属于一个特定类 (svm分类)
d. 对于属于某一特征的候选框,用回归器进一步调整其位置
(bounding boxes regression)
R-CNN论文理解请参看我的博客
Fast R-CNN对比改进
Fast R-CNN的提出,解决了R-CNN的三个重要缺陷问题:
问题一:测试时速度慢
R-CNN中用CNN对每一个候选区域反复提取特征,而一张图片的2000个候选区域之间有大量重叠部分,这一设定造成特征提取操作浪费大量计算。
Fast R-CNN将整个图像归一化后直接送入CNN网络,卷积层不进行候选区的特征提取,而是在最后一个池化层加入候选区域坐标信息,进行特征提取的计算。
问题二:训练时速度慢
原因同上。
在训练时,本文先将一张图像送入网络,紧接着送入从这幅图像上提取出的候选区域。这些候选区域的前几层特征不需要再重复计算。
问题三:训练所需空间大
RCNN中独立的分类器和回归器需要大量特征作为训练样本。
本文把类别判断和位置精调统一用深度网络实现,不再需要额外存储。
下面我们着重分析Fast R-CNN如何解决这些问题。
Fast R-CNN模型的流程图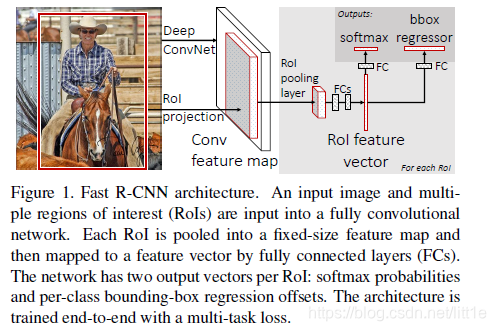
训练步骤如下:
1.输入是224×224的固定大小图片。
2.经过5个卷积层+2个降采样层(分别跟在第一和第二个卷积层后面)
进入ROIPooling层(其输入是conv5层的输出和region proposal,region proposal个数大约为2000个)
3.再经过两个output都为4096维的全连接层
4.分别经过output各为21和84维的全连接层(并列的,前者是分类输出,后者是回归输出)
5.最后接上两个损失层(分类是softmax,回归是smoothL1)
一.RoI池化层
rolpooling层可以说是解决计算冗余,提高训练测试速度的关键步骤。Rol池化层应该是SPP(spatial pyramid pooling)的简化版,关于SPPnet的总结见我的另一篇文章https://blog.youkuaiyun.com/litt1e/article/details/88369115。
RoI池化层去掉了SPP的多尺度池化,直接用MxN的网格,将每个候选区域均匀分成M×N块,对每个块进行max pooling。从而将特征图上大小不一的候选区域转变为大小统一的特征向量,送入下一层。
因为RCNN对Selective Search提取出来的2000多个候选框都需要进过CNN来4096维提取特征,对于一张图片提取出来的2000多个4096维数据包含大量的计算冗余。fast每张图片只提取一次特征,SS选出来的候选框的特征可以通过其在原图中的位置映射到最后的特征层,但是SS选出来的候选框大小不一,在特征层对应的特征的尺寸肯定也会大小不一,为了让所有的候选框产生相同的输出特征,在最后加上一个SPP层,这样不管候选框的尺寸是多少,最终产生的特征的尺寸都是一样大的。但是fast里面不是叫SPP,而是叫ROI,其实差不多。
总结一下:
由于region proposal的尺度各不相同,而期望提取出来的特征向量维度相同,因此需要某种特殊的技术来做保证。ROIPooling的提出便是为了解决这一问题的。其思路如下:
1.将region proposal划分为H×W大小的网格
2.对每一个网格做MaxPooling(即每一个网格对应一个输出值)
3.将所有输出值组合起来便形成固定大小为H×W的feature map
如此就解决了我们上述的问题。
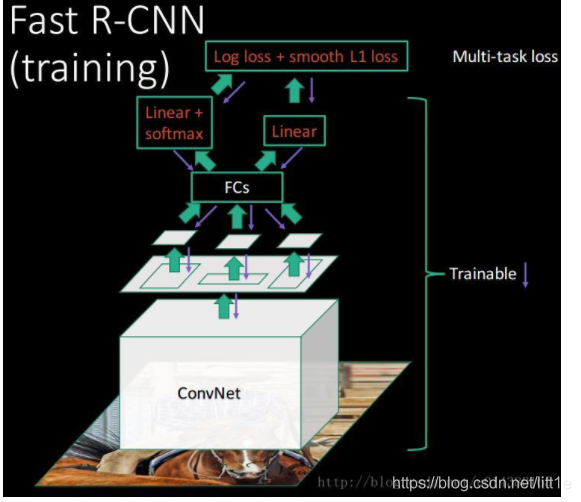
二.联合候选框回归与目标分类的全连接层
在R-CNN中的流程是先提proposal,然后CNN提取特征,之后用SVM分类器,最后再做bbox regression进行候选框的微调;Fast R-CNN则是将候选框目标分类与bbox regression并列放入全连接层,形成一个multi-task模型。
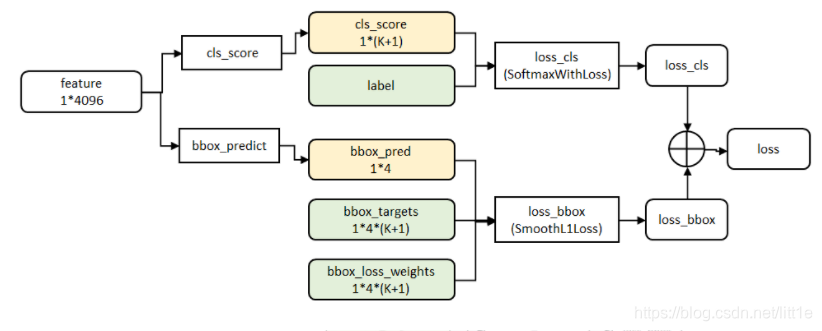
cls_ score层用于分类,输出K+1维数组p,表示属于K类和背景的概率。 bbox_predict层用于调整候选区域位置,输出4*K维数组t,表示分别属于K类时,应该平移缩放的参数。
网络的代价函数细节如下图所示:

Fast R-CNN的训练与测试
训练
首先用ILSVRC 20XX数据集进行预训练,预训练是进行有监督的分类的训练。然后在PASCAL VOC样本上进行特定调优(fine tunning),调优的数据集中25%的正样本(与真实框IoU在0.5-1的候选框)、75%的负样本(与真实框IoU在0.1-0.5的候选框)。PASCAL VOC数据集中既有物体类别标签,也有物体位置标签,有20种物体;正样本仅表示前景,负样本仅表示背景;回归操作仅针对正样本进行。
在调优训练时,每一个mini-batch中首先加入N张完整图片,而后加入从N张图片中选取的R个候选框。这R个候选框可以复用N张图片前5个阶段的网络特征,文章中N=2,R=128。微调前,需要对有监督预训练后的模型进行3步转化:
1.RoI池化层取代有监督预训练后的VGG-16网络最后一层池化层;
2.两个并行层取代上述VGG-16网络的最后一层全连接层和softmax层,并行层之一是新全连接层1+原softmax层1000个分类输出修改为21个分类输出【20种类+背景】,并行层之二是新全连接层2+候选区域窗口回归层;
3.上述网络由原来单输入:一系列图像修改为双输入:一系列图像和这些图像中的一系列候选区域;
测试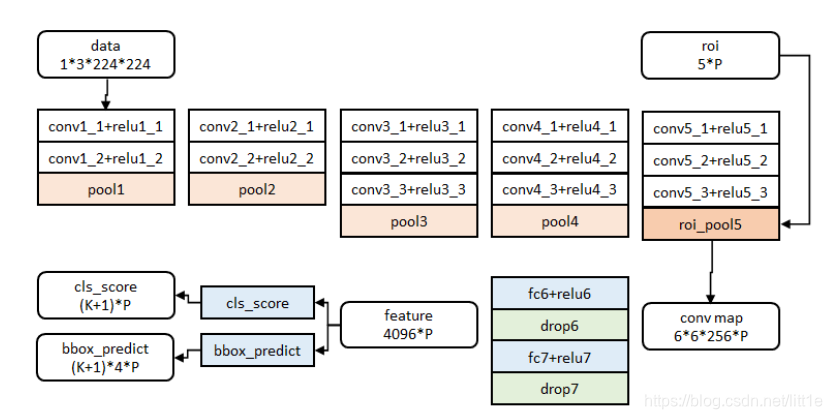
论文原文:
https://www.semanticscholar.org/paper/Fast-R-CNN-Girshick/3dd2f70f48588e9bb89f1e5eec7f0d8750dd920a
参考文章:
https://blog.youkuaiyun.com/shenxiaolu1984/article/details/51036677
https://www.jianshu.com/p/fbbb21e1e390
https://www.cnblogs.com/CZiFan/p/9903518.html

















 1673
1673

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









