




 本文介绍了深度学习中优化器的重要性和配置方法,包括如何给不同层设置不同的学习率及冻结特定层。通过mmcv库的具体实例,展示了SGD、Momentum、Nesterov等常见优化算法的工作原理和实现细节。
本文介绍了深度学习中优化器的重要性和配置方法,包括如何给不同层设置不同的学习率及冻结特定层。通过mmcv库的具体实例,展示了SGD、Momentum、Nesterov等常见优化算法的工作原理和实现细节。

深度学习中opitmizer是一个十分重要的组成部分,在一些任务中,我们需要给不同 layer 设置不同的学习率以及冻结特定层。为了更好的掌握和使用mmcv,这里留下一些笔记。我会不定期更新mmcv,mmdetection内容,有兴趣的同学可以留言。
首先介绍一些经常出现的梯度优化方法。
SGD
随机梯度下降,随机选取一批样本计算梯度,并更新一次参数。梯度更新公式如下:
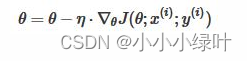
SGD存在一些问题:在梯度平缓的维度下降非常慢,在梯度险峻的维度容易抖动,且容易陷入局部极小值或鞍点。
Momentum
Momentum在每次下降时都加上之前运动方向上的动量,在梯度缓慢的维度下降更快,在梯度险峻的维度减少抖动。
对于在梯度点处具有相同的方向的维度,其动量项增大,对于在梯度点处改变方向的维度,其动量项减小。因此,我们可以得到更快的收敛速度,同时可以减少摇摆。
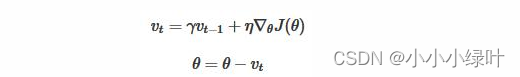
Nesterov
Nesterov是Momentum的变种。与Momentum唯一区别就是,计算梯度的不同。Nesterov动量中,先用当前的速度 临时更新一遍参数,在用更新的临时参数计算梯度。因此,Nesterov动量可以解释为在Momentum动量方法中添加了一个校正因子。
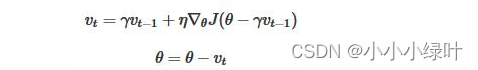
看一下pytorch的源码
Optimizer 是所有优化器的父类,它主要有如下公共方法:
- add_param_group(param_group): 添加模型可学习参数组
- step(closure): 进行一次参数更新
- zero_grad(): 清空上次迭代记录的梯度信息state_dict(): 返回 dict 结构的参数状态
- load_state_dict(state_dict): 加载 dict 结构的参数状态
def _single_tensor_sgd(params: List[Tensor],
d_p_list: List[Tensor],
momentum_buffer_list: List[Optional[Tensor]],
*,
weight_decay: float,
momentum: float,
lr: float,
dampening: float,
nesterov: bool,
maximize: bool,
has_sparse_grad: bool):
for i, param in enumerate(params):
##d_p是参数的梯度
d_p = d_p_list[i]
if weight_decay != 0:
##weight_decay其实是用来正则化的,提高模型泛化能力
d_p = d_p.add(param, alpha=weight_decay)
##参数正则化
if momentum != 0:
##buf=buf*momentum + d_p(1-dampening),buf用来寄存动量
buf = momentum_buffer_list[i]
if buf is None:
buf = torch.clone(d_p).detach()
momentum_buffer_list[i] = buf
else:
buf.mul_(momentum).add_(d_p, alpha=1 - dampening)
if nesterov:
##d_p=d_p + momentun*buf,在梯度上加上动量
d_p = d_p.add(buf, alpha=momentum)
else:
d_p = buf
alpha = lr if maximize else -lr
param.add_(d_p, alpha=alpha)
mmcv构建optimizer源码
在mmcv中,optimizer构造较为复杂,为了给不同 layer 设置不同的学习率以及冻结特定层,我们需要知道如何注册优化器,并利用DefaultOptimizerConstructor针对不同情况构造优化器
注册pytorch中的优化器
# mmcv/runner/optimier/builder.py
import inspect
import torch
from mmcv import Registry, build_from_cfg
OPTIMIZERS = Registry('optimizer') # 定义一个注册器类,用来注册pytorch中的优化器
def register_torch_optimizers():
for module_name in dir(torch.optim) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 487
487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









