







前面我们学习了机器学习任务之同步的序列到序列模式:循环神经网络 - 机器学习任务之同步的序列到序列模式-优快云博客
本文我们来学习循环神经网络应用中的第三种模式:异步的序列到序列模式!
一、基本概述:
异步的序列到序列模式也称为编码器-解码器(Encoder-Decoder)模型,即 输入序列和输出序列不需要有严格的对应关系,也不需要保持相同的长度。比如在机器翻译中,输入为源语言的单词序列,输出为目标语言的单词序列。
在异步的序列到序列模式中,输入为长度为 𝑇 的序列 𝒙1∶𝑇 = (𝒙1, ⋯ , 𝒙𝑇 ),输出为长度为𝑀的序列𝑦1∶𝑀 =(𝑦1,⋯,𝑦𝑀)。
异步的序列到序列模式一般通过先编码后解码的方式来实现.先将样本 𝒙 按不同时刻输入到一个循环神经网络(编码器 ) 中 ,并得到其编码 𝒉 𝑇 。然后再使用另 一 个循环神经网络 ( 解码器 ),得到 输出序列 𝑦̂1∶𝑀。
为了建立输出序列之间的依赖关系,在解码器中通常使用非线性的自回归模型。令 𝑓1 (⋅) 和 𝑓2 (⋅) 分别为用作编码器和解码器的循环神经网络,则编码器-解码器模型可以写为:
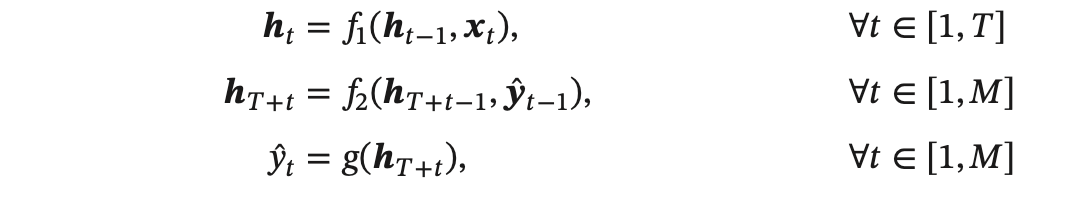
其中𝑔(⋅)为分类器,𝒚̂ 为预测输出𝑦̂ 的向量表示。在解码器通常采用自回归模型,每个时刻的输入为上一时刻的预测结果 𝑦̂𝑡−1。
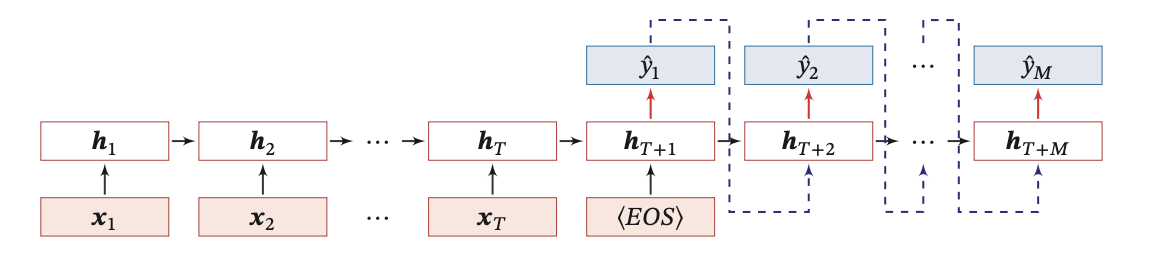
下图给出了异步的序列到序列模式示例,其中 ⟨𝐸𝑂𝑆⟩ 表示输入序列的结束, 虚线表示将上一个时刻的输出作为下一个时刻的输入。
二、具体案例
循环神经网络(RNN)在异步的序列到序列(Asynchronous Sequence-to-Sequence)模式中的应用,主要解决输入序列和输出序列在时间或长度上不对等的场景。以下是通俗易懂的解释和两个具体案例:
核心概念:异步的序列到序列
-
同步模式:输入和输出的时间步严格对齐(如视频逐帧分类,每帧对应一个标签)。
-
异步模式:输入和输出的序列长度不同、时间不对齐,且输出可能滞后于输入。
典型特征:-
输入序列:
[x₁, x₂, ..., xₘ](长度m) -
输出序列:
[y₁, y₂, ..., yₙ](长度n,且n ≠ m) -
模型需要动态调整输入与输出的时序关系。
-
案例1:实时语音翻译(同声传译)
场景描述
-
输入:一段连续的中文语音(如"今天天气很好"),按时间分帧输入。
-
输出:对应的英文翻译("The weather is nice today"),输出可能比输入延迟几秒。
异步性体现
-
输入(语音帧)是实时流入的,而输出(翻译结果)需要积累足够上下文后才能生成。
-
输入序列长度(语音时长)与输出序列长度(英文单词数)不匹配。
RNN处理过程
-
编码器(Encoder):使用RNN(如LSTM)逐步处理语音帧,生成隐藏状态。
-
解码器(Decoder):在输入未完全接收时,解码器已开始生成部分翻译,但需等待关键信息(如动词位置)后再输出完整句子。
-
注意力机制(Attention):动态对齐输入语音帧与输出单词的对应关系。
示例
-
输入语音帧序列:
[今, 天, 天, 气, 很, 好](逐帧输入) -
输出翻译序列:
[The, weather, is, nice, today](可能在输入到"气"时开始输出"The weather",后续调整)
案例2:股票价格预测(多步预测)
场景描述
-
输入:过去5天的股票数据(开盘价、成交量等),按时间顺序输入。
-
输出:未来3天的价格预测,但预测需要在第3天就给出全部3天的结果。
异步性体现
-
输入是连续的历史数据流,输出需要一次性预测多步未来值。
-
输入长度(5天)与输出长度(3天)不同,且输出需要提前生成。
RNN处理过程
-
编码器:用RNN编码过去5天的数据,生成隐藏状态(包含趋势信息)。
-
解码器:从隐藏状态出发,通过自回归(Auto-regressive)方式逐步预测未来3天的值。
-
第1步预测
y₁(第6天价格),将其作为输入预测y₂(第7天),依此类推。
-
-
教师强制(Teacher Forcing):训练时使用真实值作为解码器输入,测试时使用预测值迭代生成。
示例
-
输入序列:
[Day1, Day2, Day3, Day4, Day5](历史数据) -
输出序列:
[Day6, Day7, Day8](未来预测,需在第5天结束时全部输出)
异步模式的关键技术
-
编码器-解码器架构:分离输入处理和输出生成。
-
注意力机制:解决长距离依赖和对齐问题。
-
自回归生成:解码器逐步生成输出,每一步依赖前一步结果。
-
动态长度支持:通过
<EOS>(结束符)标记灵活控制输入输出长度。
与传统同步模式对比
| 任务类型 | 同步模式(如情感分析) | 异步模式(如机器翻译) |
|---|---|---|
| 输入输出对齐 | 严格对齐(1输入 → 1输出) | 动态对齐(多输入 → 多输出) |
| 典型应用 | 视频逐帧分类、实时传感器监测 | 翻译、语音识别、文本摘要 |
| RNN结构 | 单层RNN直接映射 | 编码器-解码器 + 注意力机制 |
异步的序列到序列模式是RNN在动态时序场景下的核心能力,它允许模型灵活处理输入与输出的复杂对应关系。无论是同声传译中的"边听边译",还是股票预测中的"多步前瞻",都体现了RNN对现实世界异步任务的强大建模能力。
三、上面提到“自回归Auto-regressive”怎么理解?
自回归(Auto-regressive)的核心思想是:用过去的数据预测未来的数据,且每一步的预测都依赖之前的预测结果。这种“逐步生成”的方式就像“自己给自己提供线索”,非常适用于生成序列数据(如文本、语音、时间序列等)。
通俗理解
想象你在写一篇文章:
-
你写下第一个词:“今天”。
-
根据“今天”,你接着写“天气”。
-
根据“今天天气”,你继续写“很好”。
-
最终得到完整的句子:“今天天气很好”。
这就是自回归:每一步生成新内容时,都依赖之前生成的所有内容。机器学习的自回归模型和你的思考过程类似,只是用数学方法实现。
自回归的两种场景
1. 时间序列预测(如股票价格)
-
目标:用历史数据预测未来值。
-
方法:每一步预测都基于前几步的真实值或预测值。
例子:预测未来3天的温度
-
输入:过去5天的温度
[20℃, 22℃, 21℃, 23℃, 24℃] -
自回归预测过程:
-
根据过去5天,预测第6天是
25℃; -
用第6天的预测值
25℃和之前的数据,预测第7天是26℃; -
再用第6-7天的预测值,预测第8天是
27℃。
-
问题:如果第一步预测错了(比如实际第6天是 23℃),后续预测会越来越偏离真实值。
2. 文本生成(如GPT写文章)
-
目标:生成连贯的句子或段落。
-
方法:每生成一个词,都依赖之前生成的词。
例子:生成句子
-
输入提示:“人工智能”
-
自回归生成过程:
-
模型生成“是” → “人工智能是”;
-
基于“人工智能是”,生成“未来” → “人工智能是未来”;
-
基于“人工智能是未来”,生成“的” → “人工智能是未来的”;
-
继续生成,直到得到完整句子:“人工智能是未来的核心技术”。
-
关键特点:生成过程像“滚雪球”,每一步都基于前面的结果。
自回归在模型中的实现
以GPT-3生成文本为例:
-
输入:用户提供开头(如“人工智能”)。
-
第一步:模型计算“人工智能”后面最可能的词(假设是“的”)。
-
第二步:将“人工智能的”输入模型,计算下一个词(可能是“发展”)。
-
循环:重复此过程,直到生成完整的句子。
数学表达:
模型每次预测第t个词的概率:
P(词ₜ | 词₁, 词₂, ..., 词ₜ₋₁)
自回归的优缺点
| 优点 | 缺点 |
|---|---|
| 生成结果连贯,上下文逻辑一致 | 生成速度慢(必须一步步计算) |
| 适合长序列生成(如文章、对话) | 错误会累积(一步错,步步错) |
| 技术成熟(GPT、LSTM均采用) | 无法并行计算(依赖前序结果) |
自回归 vs 非自回归
| 对比项 | 自回归(如GPT) | 非自回归(如BERT填词) |
|---|---|---|
| 生成方式 | 逐词生成,依赖前文 | 可同时生成所有词 |
| 速度 | 慢 | 快 |
| 质量 | 更连贯 | 可能逻辑跳跃 |
| 典型应用 | 文本生成、翻译 | 文本纠错、摘要 |
生活中的自回归例子
-
导航路线规划:
-
你开车时,每到一个路口都根据当前位置重新规划路线。
-
类似自回归:每一步决策依赖之前的路径。
-
-
音乐即兴创作:
-
音乐家根据已弹奏的音符决定下一个音符。
-
自回归模型生成音乐时也是同理。
-
自回归是机器生成序列数据的核心方法,本质是“用过去推导未来”。无论是让AI写诗、预测股票,还是生成对话,都依赖这种“步步为营”的逻辑。它的缺点(速度慢)和优点(结果连贯)就像硬币的两面,选择使用时需权衡任务需求。

















 2184
2184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









