




1.前言
因为项目的开发需要用到这一块的API,结果发现自己对这块内容的理解已经很模糊了。抓起书重新理解了一下。了解这一块内容的话完全没有必要阅读本文。
2.问题
2.1为什么不用锁?
因为锁太“重”了。本质上原子操作不过是对一小块内存区域的操作,或读或写,或加或减。用锁当然可以实现独占原子性的操作,但是要么引发调度,要么自旋空转,对于简单的内存操作没有必要。现代CPU架构可以从硬件指令的层面实现原子操作,是一种更合适的做法。
本文基于v.5.0.0版本进行讨论。
2.2 原子操作是怎么实现的?
Linux内核中如果搜索ATOMIC_OP宏定义,可以看到arch目录下每个架构 都有自己的实现。include目录下还有个共用的实现。
公共的实现在include/asm-generic/atomic.h中。
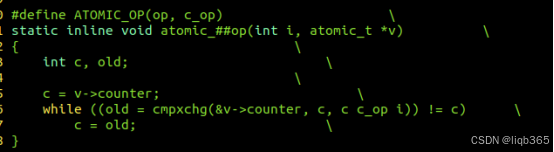
可以看到cmpxchg操作是实现原子操作的核心机制。
cmpxchg在各个平台都有各自的实现,且其实现的方式都以原子性指令实现,比如x86架构的cmpxchg指令,ARM64架构的ldxr和stxr指令。所以cmpxchg的通用性和原子性使得其称为ATOMIC_OP实现的基础。
除了上面的公共实现,各个架构对ATOMIC_OP有各自的实现,比如ARM64架构上,
arch/arm64/include/asm/atomic_ll_sc.h提供了ARM64架构专属版本。
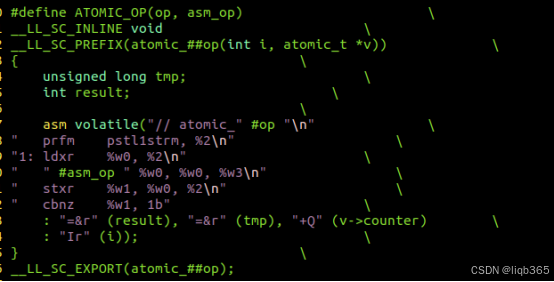
可以看到实现的的基础还是ldxr和stxr指令。
各个架构实现的版本理论上可以提供更好的性能。
2.3 ARM64架构的LDXR和STXR指令如何具有魔力?
手边的ARMV8.x手册找不到了,这里就不截图了。主要是ldxr可以标记访问内存的独占访问标记,stxr可以解除这个独占访问标记。这两条指令中间的操作就具有了内存访问的原子性。
2.4 RISC-V架构有类似的指令吗?
是的,相关的指令定义在A拓展指令集中。
2.5 比较交换操作有哪些实现方式?
首先,armv8.0架构上可以调用casx指令,但是个人理解应该是伪指令的形式实现的,本质上还是利用ldxr和stxr实现的。armv8.1架构提供了实质的casx指令。
总结一下:
|
指令 |
隐含内存屏障操作 |
解释 |
|
casa |
Load-Acquire |
防止后续指令重排在当前指令前面。 |
|
casl |
Store-Release |
防止前面指令重排在当前指令后面。 |
|
cas |
/ |
/ |
|
casal |
Load-Acquire + Store-Release |
防止后续指令重排在当前指令前面,同时防止前面指令重排在当前指令后面。 |
以cmpxchg的实现来讲,也有下面几个方式:
|
宏 |
隐含内存屏障操作 |
解释 |
|
cmpxchg_acruire |
Load-Acquire |
防止后续指令重排在当前指令前面。 |
|
cmpxchg_release |
Store-Release |
防止前面指令重排在当前指令后面。 |
|
cmpxchg_relaxed |
/ |
/ |
|
cmpxchg |
Load-Acquire + Store-Release |
防止后续指令重排在当前指令前面,同时防止前面指令重排在当前指令后面。 |
3. 总结
高并发访问的时候可以根据需求使用原子操作API,可以使用共用定义基于cmpxchg实现的API也可以使用架构优化的版本。
精力有限,开发场景也十分依赖原子操作,所以本文理解非常粗糙,仅供参考。

















 1533
1533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









