



在深度网络中,当批量梯度下降(Batch Gradient Descent)过程过于缓慢时,可以采用以下技术加速训练并帮助成本函数 J快速收敛到较小值:
1. 使用更高效的优化器
(1) 动量(Momentum)
-
原理:引入“惯性”概念,累积历史梯度方向,抑制震荡,加速收敛。
-
更新公式:
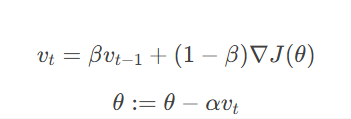
-
效果:在梯度方向一致的维度加速更新,在震荡方向平滑更新。
(2) 自适应学习率优化器
-
Adam(Adaptive Moment Estimation):
结合动量和自适应学习率,对每个参数独立调整学习率。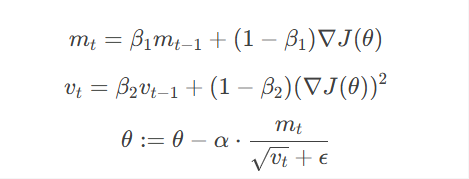
-
RMSProp:
对梯度平方进行指数加权平均,调整学习率。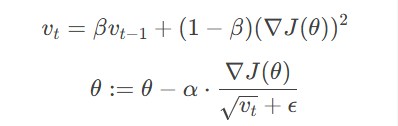
2. 学习率调整策略
(1) 学习率衰减(Learning Rate Decay)
-
原理:随着训练逐步减小学习率,初期快速接近极值,后期精细调整。
-
方法:
-
指数衰减:α=α0⋅e−kt
-
分段衰减:每 N 个 epoch 将学习率减半。
-
余弦退火:
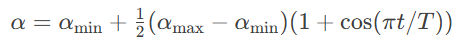
-
(2) 热重启(Warm Restarts)
-
原理:周期性重置学习率至较高值,帮助跳出局部极小值(如SGDR)。
3. 批量归一化(Batch Normalization)
-
原理:对每层的输入进行归一化(均值为0,方差为1),缓解梯度消失/爆炸。
-
公式:
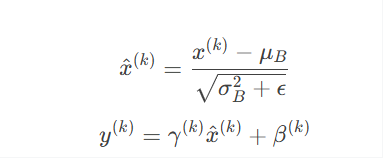
-
效果:允许使用更大的学习率,加速收敛,减少对参数初始化的依赖。
4. 参数初始化优化
-
Xavier/Glorot 初始化:
适用于 Sigmoid、Tanh 激活函数,方差为 1/fan_in。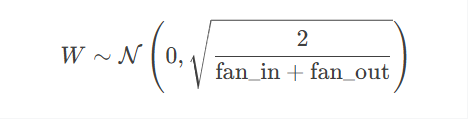
-
He 初始化:
适用于 ReLU 激活函数,方差为 2/fan_in。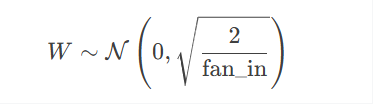
5. 迁移学习与预训练
-
原理:利用预训练模型(如ImageNet上的ResNet)作为初始化,仅微调顶层。
-
适用场景:小数据集、任务相似性高时,显著加速收敛。
6. 网络架构改进
(1) 残差连接(Residual Connections)
-
原理:引入跳跃连接(如ResNet),解决梯度消失问题。
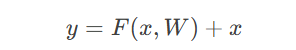
-
效果:允许训练极深层网络(如1000层)。
(2) 注意力机制(Attention)
-
原理:动态调整特征权重(如Transformer),加速信息传递。
-
适用场景:序列建模(NLP、时间序列)。
7. 数据增强与预处理
-
标准化:输入数据归一化至零均值和单位方差(加速梯度下降)。
-
数据增强:通过旋转、裁剪、噪声注入等增加数据多样性,提升泛化能力。
8. 梯度裁剪(Gradient Clipping)
-
原理:限制梯度最大值,防止梯度爆炸(尤其在RNN中)。
-
公式:
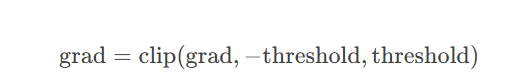
9. 混合精度训练(Mixed Precision Training)
-
原理:使用FP16和FP32混合精度计算,减少显存占用,加速计算(需支持Tensor Core的GPU)。
10. 分布式训练与并行化
-
数据并行:将批量数据拆分到多个GPU,同步更新参数。
-
模型并行:将模型拆分到多个设备(如超大模型训练)。
总结对比表
| 技术 | 核心思想 | 适用场景 |
|---|---|---|
| 动量优化器 | 累积梯度方向,减少震荡 | 高维非凸优化问题 |
| Adam/RMSProp | 自适应调整学习率 | 绝大多数深度学习任务 |
| 批量归一化 | 归一化层输入,稳定训练 | 深层网络、大学习率需求 |
| 残差连接 | 跳过连接解决梯度消失 | 极深层网络(如ResNet) |
| 迁移学习 | 复用预训练模型参数 | 小数据集、相似下游任务 |
| 混合精度训练 | FP16加速计算,FP32保持精度 | GPU训练,显存受限场景 |
实际应用建议
-
优先尝试:
-
使用 Adam优化器 + 批量归一化 + He初始化 作为基准配置。
-
-
调参顺序:
-
优化器选择 → 学习率调整 → 网络架构改进 → 数据增强。
-
-
硬件加速:
-
启用GPU/TPU加速,使用混合精度和分布式训练。
-
通过结合上述技术,可以显著加速深度网络的训练过程,并帮助成本函数 J 更快收敛到较小值。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









