




目录
一、AI界的“以小博大”:VibeThinker带来了什么?

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 新浪微博开源小参数模型VibeThinker
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
一、AI界的“以小博大”:VibeThinker带来了什么?
长期以来,AI领域似乎遵循着一个简单粗暴的“铁律”:模型参数量越大,能力就越强。从GPT-3到GPT-4,再到各类万亿参数模型,科技巨头们在“军备竞赛”的道路上越走越远,训练成本也随之飙升至数十万甚至数百万美元。这道高耸的资源壁垒,让许多中小型企业、研究机构乃至个人开发者望而却步。
然而,新浪微博于2025年11月开源的VibeThinker-1.5B模型,向这一“铁律”发起了公开挑战。
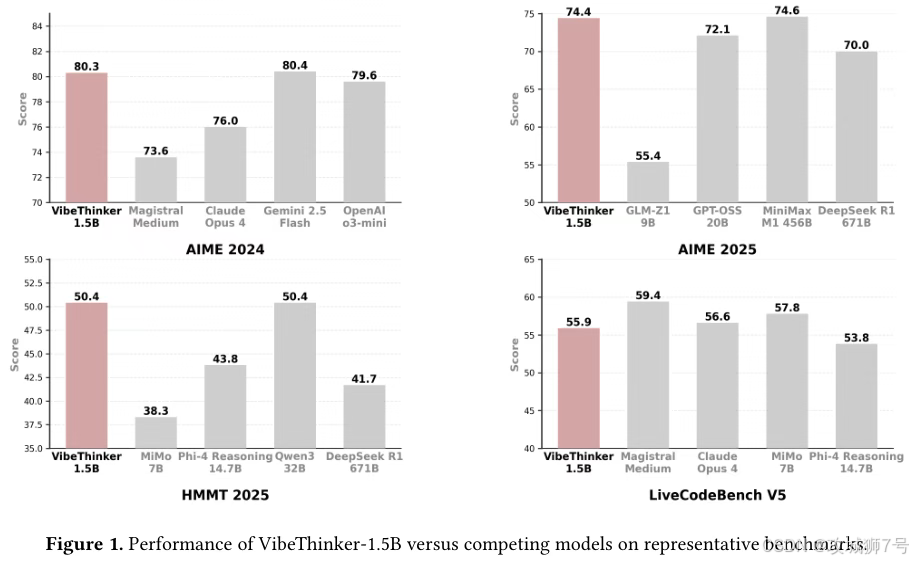
这个仅有15亿参数的“小个子”,在一系列高难度数学和编程评测中,交出了一份令人难以置信的成绩单:
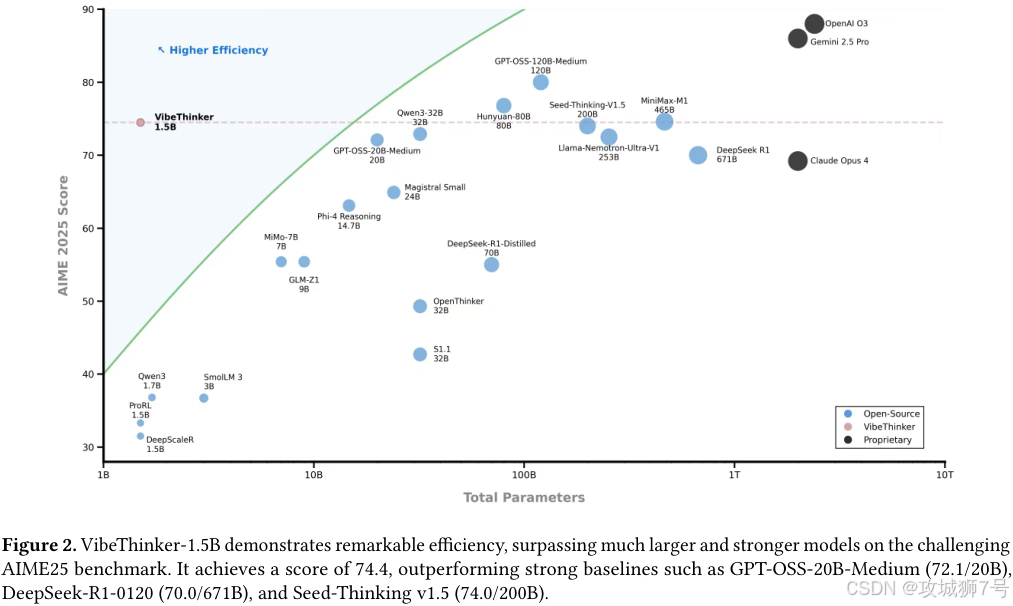
(1)数学竞赛:在美国数学邀请赛(AIME)和哈佛麻省理工数学锦标赛(HMMT)等顶级测试中,得分全面超越了参数量是其400多倍的6710亿参数模型DeepSeek R1。
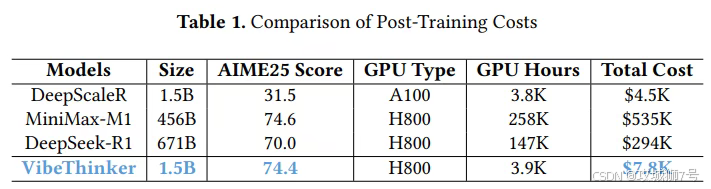
(2)成本效益:其总训练成本仅为7800美元,不到DeepSeek R1(29.4万美元)或MiniMax-M1(53.5万美元)的几十分之一。
VibeThinker的出现,似乎讲述了一个“小模型通过智慧战胜蛮力”的完美故事。它不仅挑战了“大即是好”的行业共识,更点燃了AI民主化的希望:如果小模型也能拥有强大的推理能力,那么AI创新的门槛将被大大降低。
但它真的如此完美吗?要回答这个问题,我们必须先理解它取得惊人成绩的秘密武器。
二、核心理念:“先发散,再收敛”的频谱到信号原理(SSP)
VibeThinker的成功,并非源于模型架构的革新,而是一套名为“频谱到信号原理”(Spectrum-to-Signal Principle, SSP)的训练哲学。
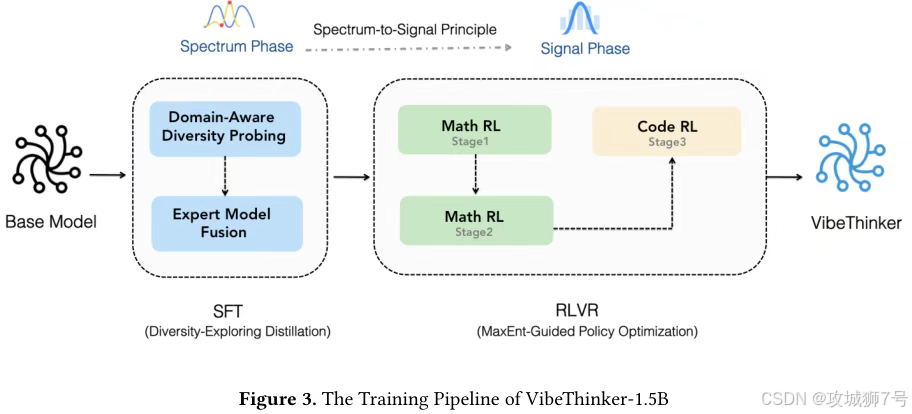
传统的模型训练方法,无论是监督微调(SFT)还是强化学习(RL),都像是一种“应试教育”。它们的目标很直接:针对一个问题,让模型学会给出那个唯一的“标准答案”,并最大化单次答对的概率(Pass@1)。这种方式容易让模型思维僵化,过早地收敛到一条狭窄的解题路径上,限制了其推理能力的上限。
SSP原则则反其道而行之,它更像是一种“素质教育”,将训练分为两个目标截然不同的阶段:
(1)频谱阶段(SFT):此阶段的目标不是“答对”,而是“多想”。它鼓励模型针对一个问题,进行“头脑风暴”,生成一个丰富多样的、包含各种合理解题思路的“解决方案频谱”。评价指标也从Pass@1 变为 Pass@K ——即模型生成K个不同答案,只要其中有一个正确就算成功。这旨在最大化模型思维的广度。
(2)信号阶段(RL):在模型学会了发散思维后,这一阶段的任务就变成了“收敛聚焦”。它像一个决策者,从上一阶段生成的广阔“频谱”中,识别出最正确、最高效的那个“信号”,并通过奖励机制进行强化,提高模型生成最佳答案的概率。
SSP原则的精髓在于,它认为先系统性地优化思维多样性,再从中提炼准确性,比从头到尾只追求准确性,能达到更高的性能天花板。一个能举一反三的模型,远比一个只会死记硬背的模型强大。
三、实现路径:两步走的“高手速成法”
VibeThinker团队设计了一套精妙的流程,将SSP原则落地。
3.1 第一步:多样性探索蒸馏(萃取思维精华)
为了打造最广阔的“解决方案频谱”,团队设计了一套巧妙的两阶段流程:
(1)领域感知多样性探测:他们没有将所有知识“一锅炖”,而是将数学细分为代数、几何、微积分等子领域。在训练过程中,模型会定期在各个子领域的“考场”上接受Pass@K指标的评估。最终,每个子领域中表现最好的那个模型版本,被加冕为该领域的“多样性专家模型”。
(2)专家模型融合:选出各领域专家后,团队通过“模型合并”技术,将这些专家模型的参数进行加权平均,最终融合出一个集各家之长、多样性最大化的全能SFT模型。这个模型知识面广、思路灵活,为下一阶段的优化奠定了坚实基础。
3.2 第二步:最大熵引导策略优化(聚焦学习“甜点区”)
进入强化学习阶段,团队面临一个新问题:如何最高效地利用训练数据?对此,他们引入了最大熵引导策略优化(MGPO)框架。
这个框架的核心思想非常符合直觉:一个问题对模型训练的价值最大化,是在模型对这个问题“最不确定”的时候。
* 如果一个问题模型已经100%掌握,反复练习是浪费时间。
* 如果一个问题远超其能力,强行学习也效果甚微。
* 只有那些模型“半懂不懂”、做起来时对时错的题目,才是它能力边界上的“学习甜点区”。
在信息论中,这种“时对时错”的50/50状态,就是熵最大的状态。MGPO框架通过算法动态识别出这些让模型“最纠结”的问题,并分配更高的训练权重,引导模型将学习资源优先投入其中。通过这种方式,模型总是在最需要提升的地方下功夫,极大地提升了学习效率。
四、冰与火之歌:惊艳的评测与“翻车”的实测
经过上述精巧的训练,VibeThinker在多个权威基准测试中取得了颠覆性的成绩,尤其是在与远超其规模的模型的对比中:

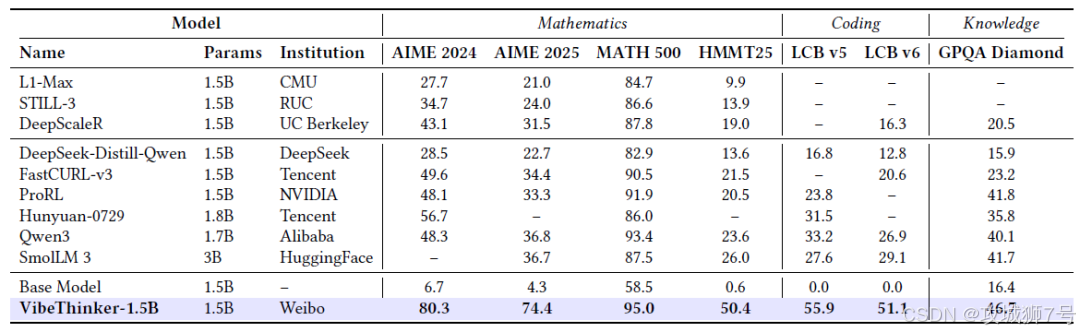
在编程能力测试LiveCodeBench中,它的表现也超越了一些商业模型。这些数据雄辩地证明,在逻辑推理这类特定任务上,精巧的算法设计确实可以超越蛮力的参数堆砌。
然而,模型的局限性也同样明显。在考验广博知识的GPQA(研究生级别问答)测试中,VibeThinker得分仅为46.7,远低于大模型普遍的70-80分。这暴露了小模型在知识存储和处理海量信息方面固有的物理限制。
更关键的是,当VibeThinker走出“考场”,面对社区用户的实际应用时,表现却不尽如人意。
许多开发者下载模型进行实测后,在社交媒体和技术论坛上给出了反馈,主要集中在以下几点:
(1)通用能力差:有用户反馈,模型“根本不如Qwen3-4B”,在处理常规问题时“一塌糊涂”。
(2)思维模式单一:与评测中展现的“多样性”相反,用户感觉它“只有一种思考模式,思考了半天,得不出个结果”。
(3)多轮对话能力弱:在多轮交流中,模型很容易“认准了第一个问题”,无法进行有效的上下文跟踪和深入探讨。
这些来自一线的“差评”与官方公布的惊艳评测结果形成了鲜明对比。一个普遍的猜测是:VibeThinker可能存在“应试偏科”的问题。其训练数据和优化目标可能高度针对AIME、HMMT这类竞赛风格的题目,从而在这些特定“考场”上取得了高分。但这并不等同于它真正获得了通用的、可泛化的逻辑推理能力。就像一个奥数冠军,未必能解决生活中遇到的所有实际问题。
五、结论:VibeThinker的真正价值是什么?
综合来看,VibeThinker-1.5B并非一个能全面取代大模型的“屠龙勇士”,它更像一个在特定领域表现出众的“偏科天才”。
它向我们证明了:
(1)“大”不一定等于“强”:在逻辑推理等特定领域,先进的训练理念和算法设计,其重要性可能超过单纯的参数规模。
(2)AI可以更高效、更经济:VibeThinker极致的成本效益,为AI民主化带来了曙光,让更多力量能够参与到前沿AI的探索中。
但同时,社区的实测也提醒我们:
(1)警惕“评测陷阱”:基准测试分数与真实世界中的泛化能力之间可能存在巨大鸿沟。
(2)小模型的边界:在通用知识和复杂多轮交互方面,小模型目前仍有其难以逾越的局限性。
VibeThinker的故事,为AI界“唯大模型论”的狂热注入了一剂冷静。它开辟了一条“小而美、专而精”的新路径,未来的AI生态,可能不再是巨型模型的一家独大,而是大小模型各司其职、百花齐放的景象:大模型作为知识渊博的“通才”,小模型则在推理、边缘计算等特定场景扮演“专家”角色。
对于AI开发者和使用者而言,VibeThinker最重要的启示是:在选择和评估模型时,不能只看榜单上的数字,更要深入其应用场景,实事求是地检验其解决实际问题的能力。
参考资料:
论文地址: `https://arxiv.org/abs/2511.06221`
GitHub: `https://github.com/WeiboAI/VibeThinker`
Hugging Face: `https://huggingface.co/WeiboAI`
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!



















 76
76

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











