




目录
一、RAG时代的关键拼图:为何高质量Embedding如此重要?
二、腾讯KaLM-Embedding:登顶全球第一的“含金量”

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 腾讯KaLM-Embedding开源
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
在深入探讨腾讯KaLM-Embedding之前,我们有必要先理解什么是Embedding(嵌入)。简单来说,它是一种将复杂的文本信息“翻译”成计算机能够理解和计算的高维数学向量的核心技术。这个过程的关键在于捕捉语义关系,让“意义”变得可度量、可计算,从而为搜索、推荐、问答等所有AI应用奠定精准理解用户意图的基石。
一、RAG时代的关键拼图:为何高质量Embedding如此重要?
进入大语言模型(LLM)时代,Embedding的重要性不降反升,尤其是在当前最火热的RAG(检索增强生成)架构中。
我们都知道,大模型虽然知识渊博,但有两个致命缺陷:
(1)知识存在“保质期”:它的知识截止于训练数据的某个时间点,无法获取最新信息。
(2)容易产生“幻觉”:在回答其知识范围外或模糊的问题时,它可能会“一本正经地胡说八道”。
RAG的出现,就是为了解决这两个问题。其核心思想是:当大模型接到一个问题时,不让它直接回答,而是先用一个工具去外部知识库(如公司的内部文档、最新的网络新闻等)里,把最相关的几段信息“找出来”,然后把这些信息连同原始问题一起,作为参考资料交给大模型,让它基于这些资料来组织答案。
在这个流程中,第一步“找出来”的环节,就是由Embedding模型负责的。我们需要提前将知识库里所有的文档都通过Embedding模型转化成向量,存入专门的向量数据库。当用户提问时,他的问题也会被同一个Embedding模型转化为一个查询向量。然后,系统会在向量数据库中,寻找与这个查询向量“距离最近”的文档向量,从而精准地捞出最相关的信息。
显而易见,如果Embedding模型的“翻译”能力不强,语义理解有偏差,那么第一步就会找错、找偏资料。给大模型提供了错误的参考信息,它自然也无法生成准确的答案。可以说,Embedding模型的质量,直接决定了RAG系统效果的上限。一个高质量的Embedding,是抑制大模型幻觉、保证生成内容准确可靠的“压舱石”。
二、腾讯KaLM-Embedding:登顶全球第一的“含金量”
了解了Embedding的重要性之后,我们再来看腾讯这次开源的KaLM-Embedding-Gemma3-12B-2511。它登顶的 MTEB(Massive Text Embedding Benchmark)榜单,是目前业界公认的、评估Embedding模型综合能力最权威、最全面的平台。
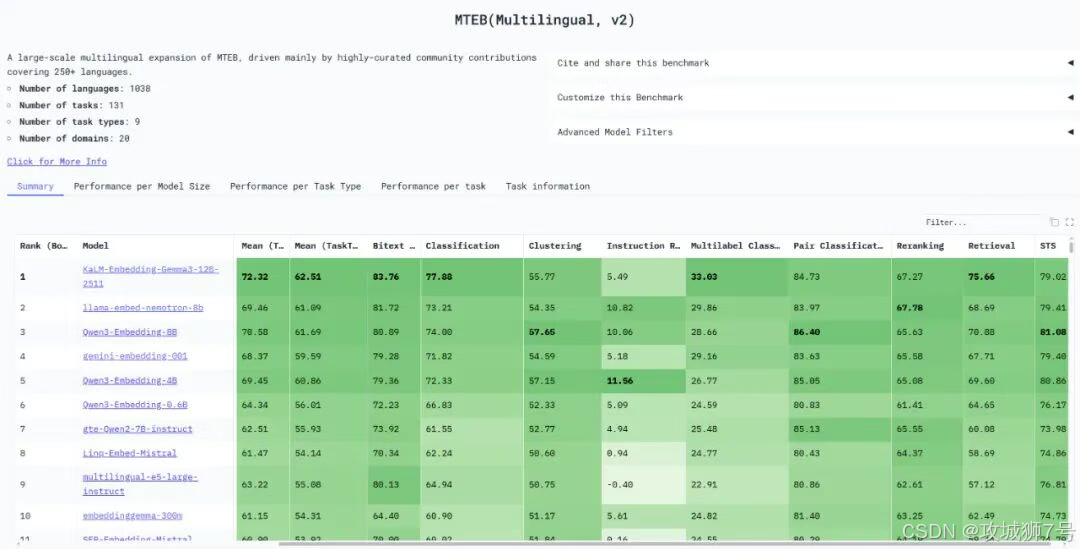
这个榜单的“含金量”极高,因为它不是只考一两个单项,而是进行“全能摸底考”:
(1)语言覆盖广:涵盖全球超过1000种语言,是真正的“多语言”评测。
(2)任务类型全:包含检索、分类、聚类、重排序等9大类、131项细分任务。
(3)竞争对手强:榜单上汇集了来自谷歌、NVIDIA、阿里巴巴等全球顶级科技公司的开源和闭源模型。
KaLM-Embedding能在这样一个高手如林的竞技场上拿到综合排名第一,充分证明了其在多语言语义理解与信息处理方面的顶尖实力。
那么,它是如何做到的呢?
2.1 强大的基座与精妙的训练策略
KaLM-Embedding并非从零开始,而是站在了巨人的肩膀上——它基于Google新发布的Gemma-3-12B模型进行微调。但更重要的是其独特的训练方法,这才是腾讯团队的核心技术所在。文档中提到的多阶段对比学习、Embedding蒸馏、难负样本在线挖掘等技术,可以通俗地理解为一套“高级教练法”:
(1)不仅告诉模型什么是“对”的(正样本),还不断给它看各种看似相似但实际错误的“迷惑选项”(难负样本),从而锻炼模型精准的辨别能力。
(2)通过“蒸馏”等技术,将更强大模型的“知识精华”提炼并注入到当前模型中,提升其泛化能力。
(3)辅以海量、经过深度清洗的高质量语料,确保模型学到的知识是纯净、可靠的。
2.2 “丰俭由人”的灵活性:多维度嵌入
这是KaLM-Embedding一个非常实用的亮点。它采用了Matryoshka Representation Learning (MRL)技术,即“俄罗斯套娃式”表示学习。这意味着,同一个模型可以输出从3840维到64维共七个不同长度的向量。
这有什么用?
(1)高维度(如3840维):包含的语义信息最丰富,精度最高,适合对效果要求极致的离线分析、大规模检索等场景。
(2)低维度(如128维、64维):向量更短,计算速度更快,占用存储和内存更少,非常适合部署在手机、边缘设备等资源受限的环境,或用于实时性要求高的在线推荐等场景。
这种设计,让开发者可以根据自己的应用场景和计算资源,在“效果”和“成本”之间做出最灵活的平衡,极大地拓宽了模型的适用边界。
三、开源的意义:AI普惠的又一块基石
更令人振奋的是,腾讯将这款全球第一的模型,以MIT许可证在Hugging Face等平台完全开源,并明确表示支持商业用途。
这意味着,无论是个人开发者、初- 公司,还是大型企业,都可以免费地、无限制地将这款顶级的语义理解能力,集成到自己的产品和服务中。
(1)一家做跨境电商的公司,可以用它来构建一个能理解全球用户查询意图的智能搜索引擎。
(2)一个内容平台,可以用它来对多语言文章进行精准的自动分类和标签化。
(3)任何一个希望构建高质量RAG应用的企业,都有了一个免费且顶级的“语义基座”可用。
腾讯此次的开源,不仅是其技术实力的展现,更是对整个AI开源生态的巨大贡献。它进一步降低了中小企业和开发者使用前沿AI技术的门槛,为全球范围内的AI应用创新,提供了一块坚实、可靠的基石。随着KaLM-Embedding的广泛应用,我们有理由相信,一个语言无界、信息共享的智能世界正在加速到来。
模型地址:https://huggingface.co/tencent/KaLM-Embedding-Gemma3-12B-2511
GitHub 项目:https://github.com/HITsz-TMG/KaLM-Embedding
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!



















 1086
1086

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











