






> 💡 原创经验总结,禁止AI洗稿!转载需授权
> 声明:本文所有观点均基于在新能源车联网、智慧电网、高端制造多个领域的真实项目落地经验总结,数据说话,拒绝空谈!
目录
三、实战为王:用IoTDB+MQTT+Flink搭建车联网平台
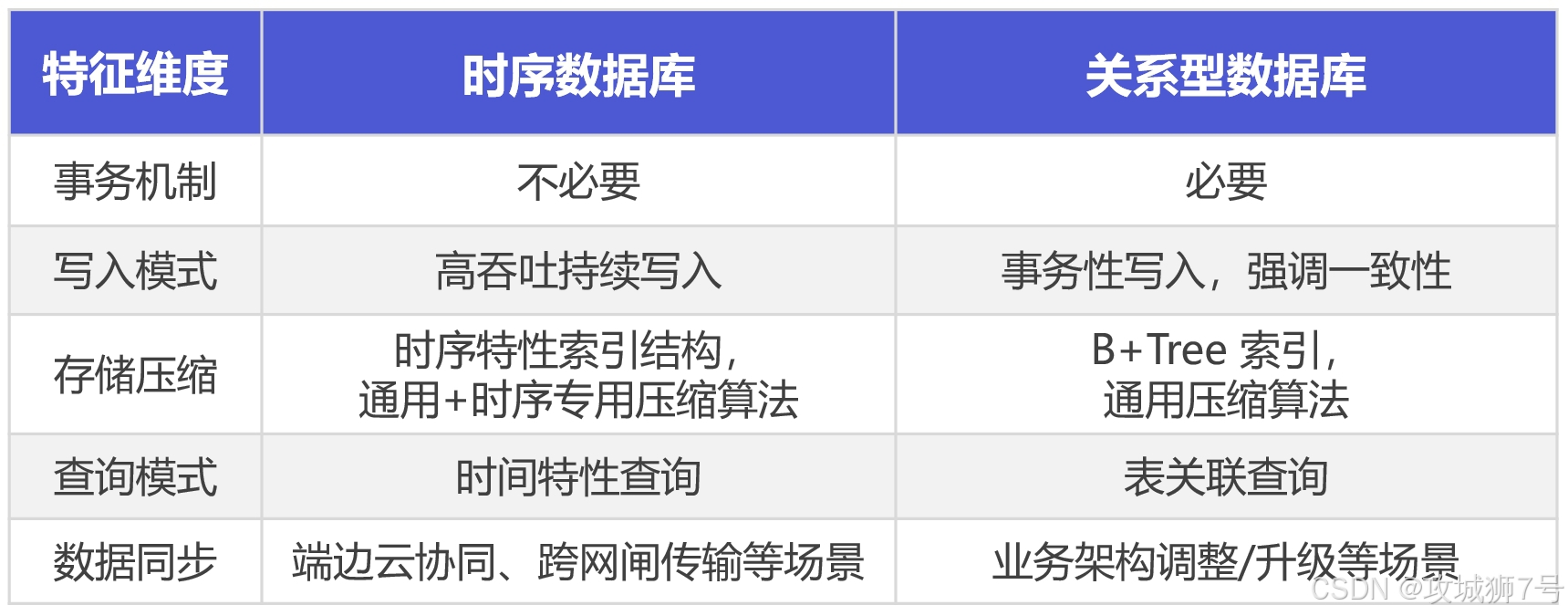
一、不同的场景,肯定是用不一样的数据库
如果你正在负责一个物联网(IoT)或工业互联网项目,并且还在用MySQL、PostgreSQL甚至MongoDB来硬扛时序数据,那么下面这几个场景,你大概率正在经历,或者即将在下一个业务高峰期遇到:
(1)写入瓶颈 (Ingestion Bottleneck):随着设备量和采集频率的提升,你的数据库`INSERT`操作开始频繁超时。DBA团队不断优化索引、分区,甚至上了读写分离,但写入性能的天花板就在那里,怎么也上不去了。单表几亿行后,任何写入都成了一次奢侈。
(2)存储成本失控 (Storage Cost Explosion):时序数据天然的冗余度不高,但关系型数据库的行式存储却无法有效压缩。看着磁盘使用率每月翻番,CFO开始在会议上频繁点名,“数据价值”还没体现,存储预算先爆了。
(3)查询性能雪崩 (Query Performance Collapse):业务方想看一个设备过去一年的趋势分析,一个`GROUP BY time`的查询,能让数据库CPU飙到100%,跑个几十分钟还不出结果。最后只能妥协,“别查了,我们导出来用Python跑吧”,数据平台的脸往哪搁?
这并非危言耸-听,而是无数项目血淋淋的教训。传统数据库在时序数据(Time-Series Data)面前,就像让一个短跑冠军去跑马拉松——专业不对口,累死也白搞!
时序数据库(TSDB)因此应运而生。但市面上产品五花八门,InfluxDB、TimescaleDB、OpenTSDB... 怎么选?作为一名在数据领域互联网老兵,今天我就带大家彻底扒一扒,尤其是国产之光——Apache IoTDB,看看它到底凭什么成为越来越多大厂的“心头好”。

> 互动一下:你的项目里,时序数据存储用的是什么方案?在评论区聊聊你踩过的坑!
二、选型6大维度:别只看TPS,那都是“障眼法”
选型不能只看官方宣传的单项冠军指标。一个成熟的TSDB,必须是“六边形战士”。我总结了6个核心维度,并拉上了几个“老朋友”做个横向对比,高下立判。
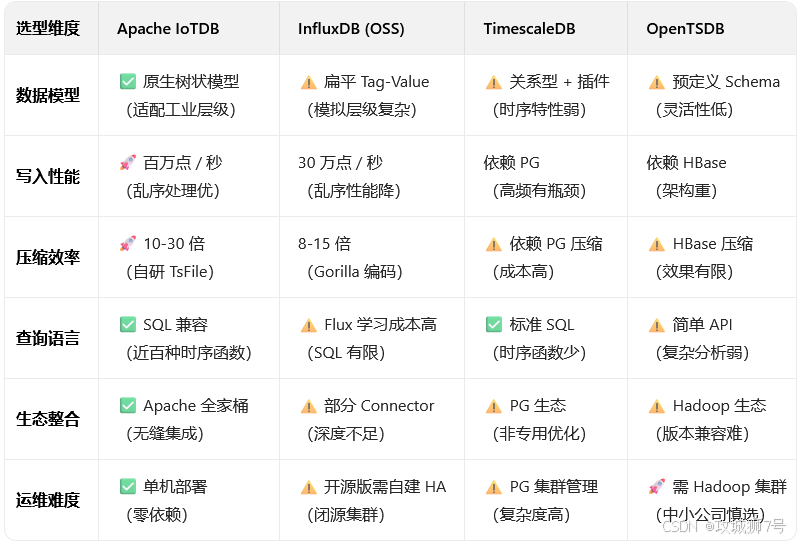
IoTDB 多项性能表现位居国际数据库性能测试排行榜 benchANT(Time Series: DevOps)第一
小结:从表格可以清晰看到,IoTDB在模型、性能、压缩、生态、成本五个维度上几乎是碾压性的优势,尤其适合咱们物联网和工业互联网的场景。它不是简单的“快”,而是一种体系化的领先。
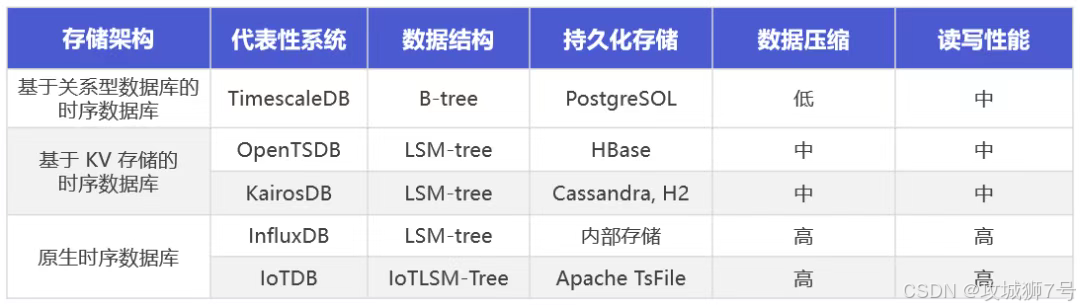
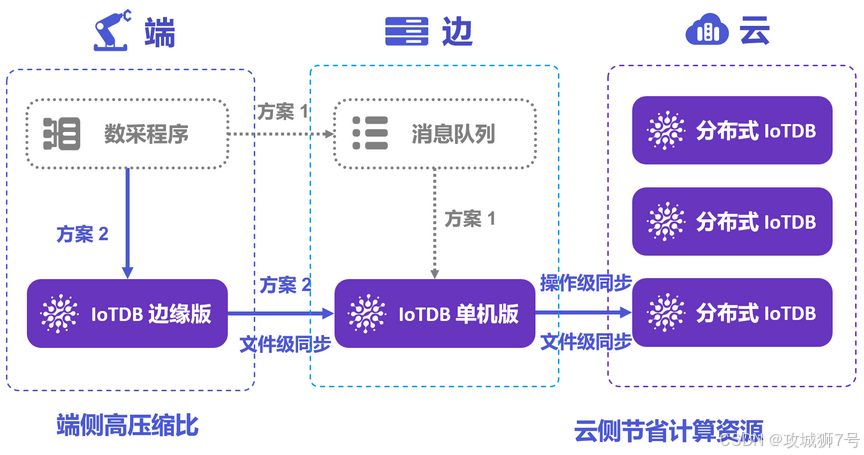
三、实战为王:用IoTDB+MQTT+Flink搭建车联网平台
空谈无益,上实战架构!下面是我们给某车联网客户设计的真实方案,完美解决了他们之前遇到的所有痛点。
3.1 架构描述
(1)数据采集 (MQTT):车载终端通过`MQTT`协议,将GPS、车速、电池SOC等上百个指标实时上报到EMQX等MQTT集群。MQTT的优势是轻量、低功耗,非常适合车端弱网络环境。
(2)数据处理 (Flink):`Flink`作为流处理引擎,订阅MQTT中的车辆数据。在Flink作业中,我们进行实时的数据清洗(过滤无效值)、转换(协议解析)、 enriquecimiento(关联车辆静态信息),并进行一些简单的实时告警判断。
(3)数据入库 (IoTDB):处理干净的数据通过`Flink IoTDB Connector`高效写入`IoTDB`集群。这里我们充分利用了IoTDB的高吞吐能力,从容应对百万车辆的高并发写入。
(4)数据应用 (API/BI):后端服务通过IoTDB的JDBC/SDK接口,为APP提供车辆实时状态查询、历史轨迹回放等功能。同时,数据分析师可以通过Grafana、或者对接Spark,对IoTDB中的海量数据进行深度挖掘,比如分析驾驶行为、预测电池衰减等。
这个架构的核心优势在于边云协同。我们可以在车机端或边缘网关部署IoTDB的轻量级实例(解压即用,资源占用极低),进行本地数据缓存和初步计算,再批量同步到云端IoTDB集群。这极大地降低了云端带宽压力和数据延迟,这在很多国外方案里是做不到的!
3.2 SQL查询示例
来看看从IoTDB里查询数据有多简单。假设我们要查询`粤B12345`这辆车昨天每10分钟的平均车速和最高温度,并找出异常点。
-- 查询指定车辆,按10分钟窗口进行降采样聚合
SELECT
__endTime AS window_end,
max_value(temperature) AS max_temp, -- 计算10分钟内最高温度
avg(speed) AS avg_speed -- 计算10分钟内平均车速
FROM
root.iov.shenzhen.`car_粤B12345` -- 注意反引号包裹中文设备名
WHERE
time >= now() - 1d -- 查询范围:昨天到现在
AND time < now() -- 精确时间范围
GROUP BY
([now() - 1d, now()), 10m -- 时间窗口:10分钟
FILL(previous) -- 缺失值用前值填充
ALIGN BY DEVICE -- 确保结果集对齐👆 就这么几行类SQL代码,比InfluxDB的Flux简单了不止一个数量级!业务开发同学几乎零成本上手。
四、避坑指南:时序数据库选型3大“想当然”
结合踩过的坑,我给大家总结3个最容易犯的选型错误:
(1)误区一:唯“写入TPS”论。
只盯着写入性能,忽视了查询灵活性和压缩比。结果可能是数据写进去了,但查不出来、存不起。查询能力决定了数据价值的上限,存储成本决定了项目的生死。
(2)误区二:忽视数据模型与业务的匹配度。
强行用关系型或扁平模型去套工业设备这种天然的树状层级关系,会导致数据结构臃肿、管理混乱。选型前,先问问自己:我的数据模型,数据库它“懂”吗?
(3)误区三:忽略边缘计算场景的需求。
5G时代,不是所有数据都要无脑上云。一个好的TSDB必须具备“云边协同”的能力。如果一个方案只能部署在云端中心,那它在很多工业场景下,可能已经“输在了起跑线上”。
五、国产技术突围,是时候拥抱变化了!
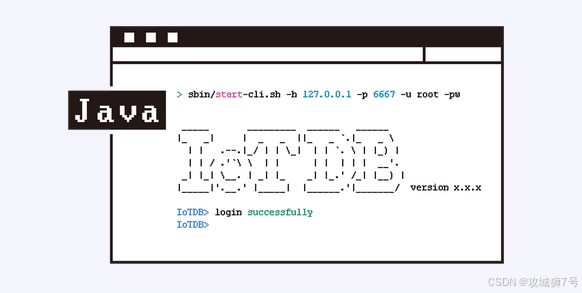
过去,我们在数据库选型上,言必称Oracle、MySQL、MongoDB。但今天,在时序这个细分赛道,以Apache IoTDB为代表的国产力量,已经通过顶级的开源社区运作和坚实的技术实力,做到了全球领先。
它不仅性能卓越,更关键的是,它源于工业场景,深刻理解中国企业的数字化痛点。无论是层级化的设备管理、复杂的网络环境下的数据同步,还是与国内主流大数据生态的集成,IoTDB都提供了“量身定制”的解决方案。
用对工具,才能真正释放时序数据的价值。
> 👉 下载Apache IoTDB开源版:[ https://iotdb.apache.org/zh/Download/ ]
> 👉 官网参考:[ https://timecho.com ]
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!


















 1825
1825

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











