







目录

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 Gemini 2.5 Pro升级
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
2025年6月初,就在人们还沉浸在各大科技公司 AI 模型你追我赶的激烈竞赛中时,谷歌悄无声息地放出了一记"王炸"——发布了 Gemini 2.5 Pro 的最新预览版。这并非一次常规的小修小补,而是一次脱胎换骨的全面升级,其性能表现之强悍,让它在多个权威的 AI 基准测试中"屠榜",重新夺回了多项第一的宝座。
谷歌 CEO 桑达尔·皮查伊(Sundar Pichai)也亲自下场,在社交媒体上为新版本站台,预告其将在未来几周内作为稳定版正式推出。消息一出,立刻在开发者社区和科技圈引发了热议。
那么,这个新版的 Gemini 2.5 Pro 究竟"新"在何处?它比之前的版本以及竞争对手们又强了多少?这篇文章将为你深入浅出地剖析这次更新的核心亮点,带你了解数据背后的真正实力。
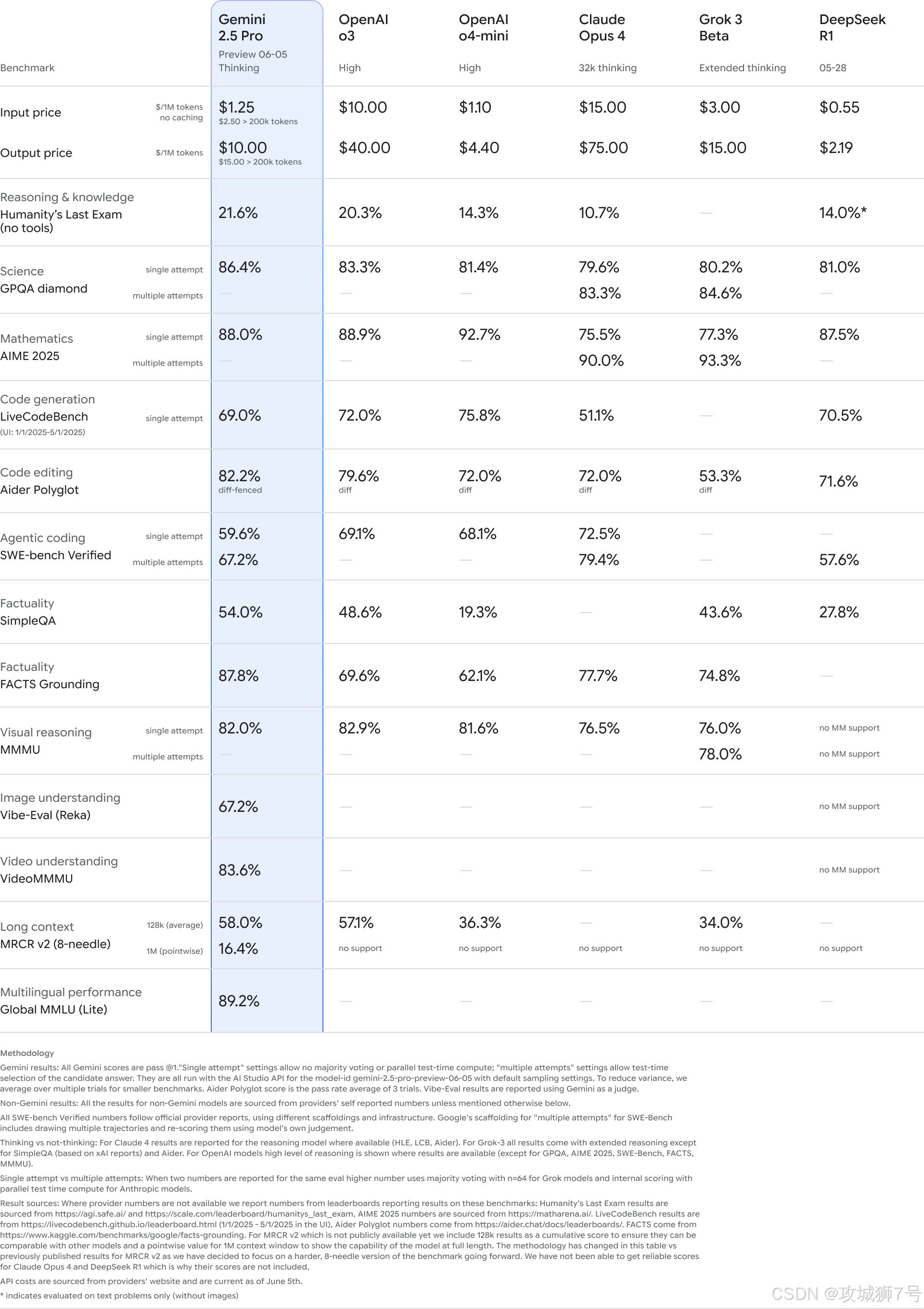
一、"屠榜"的性能:数据不会说谎
"是骡子是马,拉出来遛遛。" 在 AI 领域,衡量一个模型真实能力的"遛马场"就是各种公开的基准测试平台。在这些平台上,不同的 AI 模型会在相同的匿名条件下回答来自人类的各种问题,其表现由其他用户进行投票排名,这在很大程度上能客观反映模型的真实水平。
而新版 Gemini 2.5 Pro(版本号 06-05)在这些测试中,交出了一份近乎完美的答卷。
(1)综合能力登顶:在著名的 `LMArena` 文本基准测试中,新模型的 Elo 评分(一种衡量对战水平的积分系统)跃升了 24 分,以 1470 分的高分稳坐榜首,超越了包括 OpenAI GPT-4o、Claude 4 在内的所有对手。
(2)网页开发能力大幅领先:在专注于衡量网页开发能力的 `WebDevArena` 测试中,它的表现更为惊人,Elo 评分飙升了 35 分,以 1443 分的成绩遥遥领先。这意味着在生成和理解前端代码方面,它有了巨大的进步。
(3)编程能力成为新王者:对于开发者来说,最直观的感受可能来自于编程能力的提升。在 `Aider Polyglot` 这种高难度的编程基准测试中,新版 Gemini 2.5 Pro 的通过率达到了 82.2%,一举超过了此前在该领域备受赞誉的 Claude Opus 4。
(4)挑战"人类极限"的推理能力:除了写代码,它在处理高难度科学问题和复杂推理方面的能力也达到了顶尖水平。在 `GPQA`(谷歌证明的问答,一个包含研究生级别科学问题的测试)和 `HLE`(人类终极考试)这类极具挑战性的测试中,它的表现同样名列前茅。这些测试远非简单的知识问答,而是考验模型真正的逻辑推理和深度理解能力。
简单来说,数据清晰地表明,无论是在通用的文本对话、专业的编程任务,还是在极度考验智商的科学推理上,新版 Gemini 2.5 Pro 都已经达到了业界顶尖,甚至在多个维度上成为了新的领跑者。
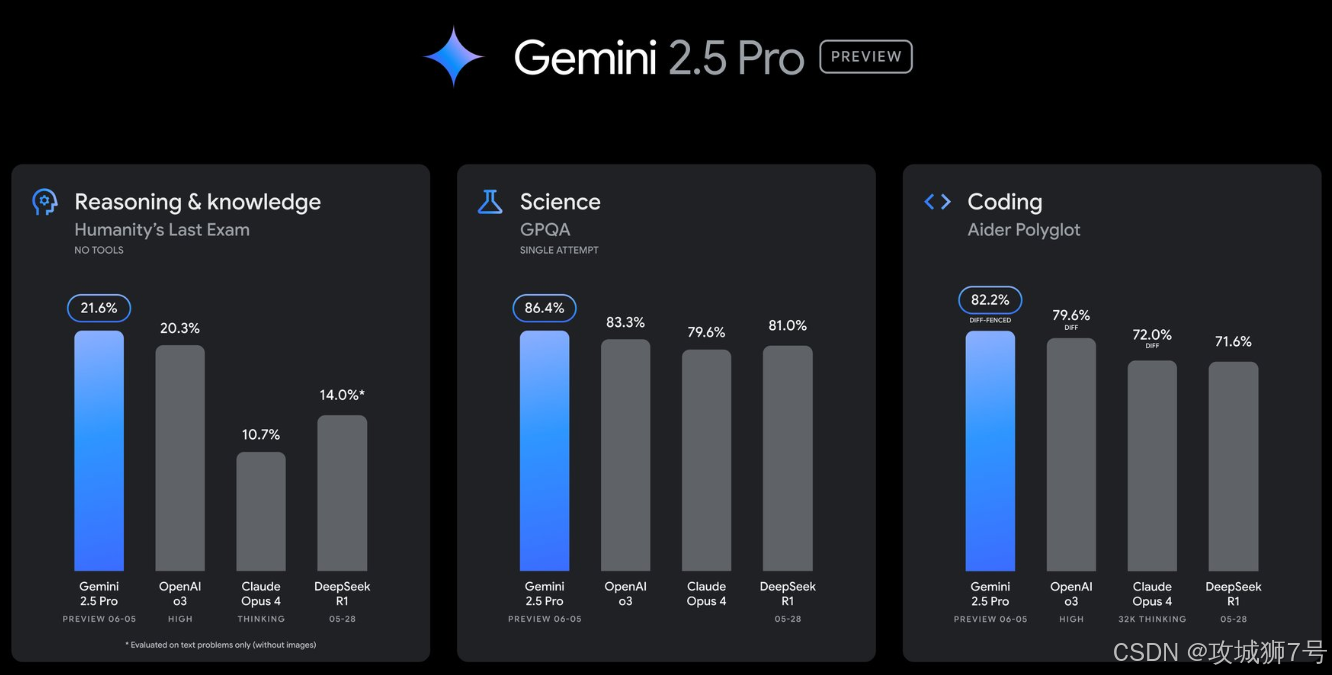
二、不只更快更强,还更"会思考"、更具"性价比"
如果说性能的提升是"硬实力",那么在功能和成本上的优化,则让 Gemini 2.5 Pro 的"软实力"也同样诱人。
(1)输出风格更佳,更具创造力
根据谷歌的官方介绍和用户的反馈,新模型的输出风格和结构也得到了显著改善。它不再只是一个冷冰冰的"答案生成器",而是可以根据你的要求,提供更有创意、格式更优美的回答。例如,有用户测试让它模仿一只"500岁的猫"的口吻进行对话,其角色扮演的细腻程度和语言风格的把握都相当到位。这意味着它在内容创作、营销文案、剧本构思等需要创造力的场景中,将会有更好的表现。
(2)"思考预算":给开发者更大的控制权
这是一个专为开发者设计的全新功能。简单来说,"思考预算"(Thinking Budgets)允许开发者在调用模型时,可以更灵活地去平衡"效果"、"成本"和"速度"这三者。你可以允许模型花费更多的"思考时间"(消耗更多的计算资源)来处理一个复杂问题,以求获得更高质量的回答;或者,在对响应速度要求很高的场景下,限制它的思考时间,以换取更快的响应和更低的成本。这种精细化的控制,让开发者在构建自己的 AI 应用时有了更大的自由度。
(3)价格屠夫:高性能下的"卷王"本色
最让市场震惊的,可能就是它的定价策略。在性能全面超越对手的同时,谷歌并未提高 Gemini 2.5 Pro 的价格。其每百万 Token(可以理解为处理文本的基本单位)的输入价格为1.25美元,输出价格为10美元。
这是什么概念?这个价格大约只有 OpenAI GPT-4o 的八分之一,Claude 4 的十分之一。当性能和对手处于同一水平线甚至更高时,如此悬殊的价格差距无疑会成为其最具杀伤力的武器。对于需要大量调用 AI 模型的企业和开发者来说,这意味着可以用远低于以往的成本,获得目前市面上最顶级的 AI 服务。
三、真实世界中的表现:从代码到3D建模
理论和跑分固然重要,但一个模型好不好用,最终还是要看它在真实任务中的表现。在新版模型发布后,全球的开发者和AI爱好者立刻对其进行了五花八门的"极限测试"。
(1)复杂的物理模拟:有用户成功让 Gemini 2.5 Pro 通过了一项高难度的"六边形物理模拟"测试,这需要模型对物理规律有深刻的理解才能生成正确的代码。
(2)一行指令生成交互式3D模型:一位开发者仅仅用了一句指令——"用 Three.js 创建一个 3D DNA 模型",Gemini 2.5 Pro 就生成了效果惊艳的交互式 3D 粒子系统代码,让这位开发者直呼"这不可能是真的!"
(3)代码质量对比:在生成 Python 代码模拟交通灯的测试中,Gemini 2.5 Pro 生成的动画效果精美,车辆运行符合物理逻辑;而作为对比,其他一些知名模型生成的代码则显得相对粗糙,甚至出现了车辆重叠等不合逻辑的现象。
(4)原生UI代码生成:在移动开发领域,它也能直接生成 Android Jetpack Compose 的 UI 代码,并且包含了详细的注释和必要的导入语句,可用性非常高。
这些真实的案例,从不同侧面印证了基准测试中的优异成绩并非虚名。它强大的代码生成和理解能力,已经能够胜任许多过去难以想象的复杂开发任务。
总结:AI 竞赛进入"快迭代"时代
从 DeepSeek 的异军突起,到 OpenAI 的 GPT-4o 技惊四座,再到谷歌携 Gemini 2.5 Pro 王者归来,AI 大模型的"头把交椅"在短短几个月内几度易主。这充分说明,我们已经告别了 AI 技术偶尔才有一次大爆发的时代,进入了一个迭代速度越来越快的"快迭代"周期。
谷歌这次的更新,不仅在性能和功能上迎头赶上甚至反超,更用极具竞争力的价格,向整个市场宣告了其抢占开发者生态的决心。正如一位分析师所言,Gemini 2.5 Pro 可能是"最被低估的智能模型",而现在,它正在用实力证明自己的价值。
对于我们普通用户和开发者而言,这种"神仙打架"无疑是最好的消息。激烈的竞争将不断催生出更强大、更易用、也更便宜的 AI 工具,而这些工具,正在以前所未有的方式,改变着我们的工作、学习和生活。我们有理由期待,即将到来的 Gemini 2.5 Pro 正式版,以及它未来与谷歌全家桶产品的深度融合,将会带来怎样的惊喜。
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!



















 2697
2697

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











