







 本文详细介绍了DPDK中的多队列技术和流分类技术,包括RSS和Flow Director,阐述了多队列的由来、DPDK如何利用多队列提升性能,并探讨了流分类在QoS、流过滤等方面的应用。通过对Intel网卡的示例,展示了如何在DPDK中配置和使用这些技术。
本文详细介绍了DPDK中的多队列技术和流分类技术,包括RSS和Flow Director,阐述了多队列的由来、DPDK如何利用多队列提升性能,并探讨了流分类在QoS、流过滤等方面的应用。通过对Intel网卡的示例,展示了如何在DPDK中配置和使用这些技术。
1.前言
多队列与流分类技术基本被应用到所有DPDK网关类项目中,比如开源的DPVS,美团的四层网关等等,利用多队列及分流技术可以使得网卡更好地与多核处理器,多任务系统配合,从而达到更高效IO处理的目的。
这章节以英特尔的网卡为例,介绍多队列和流分类是如何合工作的 ,各种分类方式适合哪些场景,DPDK怎么利用这些网卡特性。
2.多队列
2.1 网卡多队列的由来
谈到这个网卡多队列,显而易见说的就是传统网卡的DMA队列有多个,网卡有基于多个DMA队列的分配机制。图中是Intel 82580网卡示意图,我们能看到多队列分配在网卡中的位置。
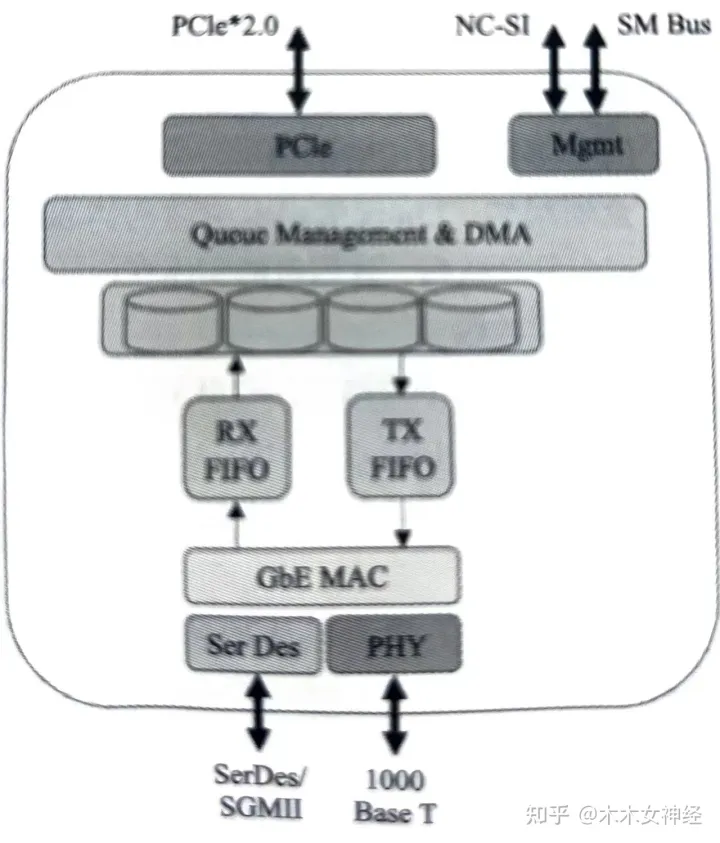
图2-1 82580网卡简易框图
网卡多队列技术与多核处理器技术密不可分,早期的多数计算机,处理器只有一个核,从网卡上收到的以太网报文都需要这个处理核处理。随着半导体技术发展,处理器上核的数量不断在增加,与此同时就带来一个问题:网卡上收到的报文由哪个核来处理?如何分配不同的核上去处理呢?随着网络带宽的不断提升,当端口速率从10Mbit/s100Mbit/s进入1Gbit/s10Gbit/s,单个处理器核肯定是不够满足高速网卡快速处理的需求的,从2007年开始Intel的82575和82598网卡上就引入了多队列技术,可以将各个队列通过绑定到不同的核上来满足高速流量的需求。现在100G、400G的网卡更是支持越来越多的队列数目,除此之外,多队列技术也可以进行流分类处理,以及解决网络IO服务质量QOS,针对不同的优先级进行限速和调度。
强调一下网卡多队列技术是一个硬件手段,需要软件结合将它利用起来才能达到设计目的,分而治之,根据多队列进行流分类,这样应用就可以根据自己的需求将数据包进行控制,可以想象一下哪些场景我们需要这种技术去解决哪些问题,从数据包的响应速度,数据包分类,队列优先级,等等方向来考虑,我相信大家一定能在自己的工作场景使用此技术解决这类问题。
2.2 DPDK与多队列
我们从DPDK提供的一些列以太网设备API入手,可以发现Packet I/O机制与生俱来的支持多队列功能,可以根据不同平台或者需求,选择需要支持的队列数目,可以很方便地使用队列,指定队列发送或者接收,由于这样的特性,可以很容易实现CPU核、缓存与网卡多队列之间的亲和性从而到达很好的性能。
从例子里的l3fwd里也能看出,单个核上运行的程序从指定队列上接受,往指定队列上发送,可以达到很高的cache命中率,效率也就会高。
从RTC模型为例来看,核、内存、网卡队列之间的关系理解DPDK是如何利用网卡多队列技术带来的性能提升。
- 将网卡的某个队列分配給某个核,从该队列中收到的报文都应当在该指定的核上处理结束。
- 从核对应的本地存储分配内存池,接收报文和对应的报文描述符都位于该内存池。
- 为每个核分配一个单独的发送队列,发送报文和对应的报文描述符都位于该核和发送队列对应的本地内存池中。
所以通常情况我们绑定一个核使用一个单独的发送队列来避免多个核访问同一个队列带来的锁开销。当然也可以绑定多个队列到一个核,总之在设计时尽量避免引入保护队列的机制。
对应的可以看源码中l3fwd的例子,其中每个核对应结构中记录了操作的队列是哪个队列。
除了队列和核之间的亲和性这个主要目的之外,网卡多队列机制还可以用与Qos调度、虚拟化等。
2.3 多队列分配
看到这里读者一定会疑问我们可以设定不同的队列包收到不同的核去处理,那么网卡又是怎么把网络报文分发到不同
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5024
5024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









