




 本文介绍了eBPF(Extended Berkeley Packet Filter)的基础知识,包括其起源、与cBPF的区别,以及在现代操作系统中的重要作用。eBPF作为一个通用执行引擎,广泛应用于性能分析、网络过滤、内核调试等多个领域。文章详细阐述了eBPF的工作原理、架构,如虚拟机、指令集、字节码、hook、map和辅助函数等,并列举了BCC Tools、Cilium和eBPF Exporter等实际应用案例。此外,还提及了eBPF编程工具,如libbpf和bpftrace,以及其对内核模块的替代优势。
本文介绍了eBPF(Extended Berkeley Packet Filter)的基础知识,包括其起源、与cBPF的区别,以及在现代操作系统中的重要作用。eBPF作为一个通用执行引擎,广泛应用于性能分析、网络过滤、内核调试等多个领域。文章详细阐述了eBPF的工作原理、架构,如虚拟机、指令集、字节码、hook、map和辅助函数等,并列举了BCC Tools、Cilium和eBPF Exporter等实际应用案例。此外,还提及了eBPF编程工具,如libbpf和bpftrace,以及其对内核模块的替代优势。
eBPF 简介
什么是 BPF
BPF(Berkeley Packet Filter),中文翻译为伯克利包过滤器,是类 Unix 系统上数据链路层的一种原始接口,提供原始链路层封包的收发。BPF 在数据包过滤上引入了两大革新:
- 基于虚拟机 (VM) 设计,可以有效地工作在基于寄存器结构的 CPU 之上。
- 应用程序使用缓存只复制与过滤数据包相关的数据,不会复制数据包的所有信息。这样可以最大程度地减少BPF 处理的数据。
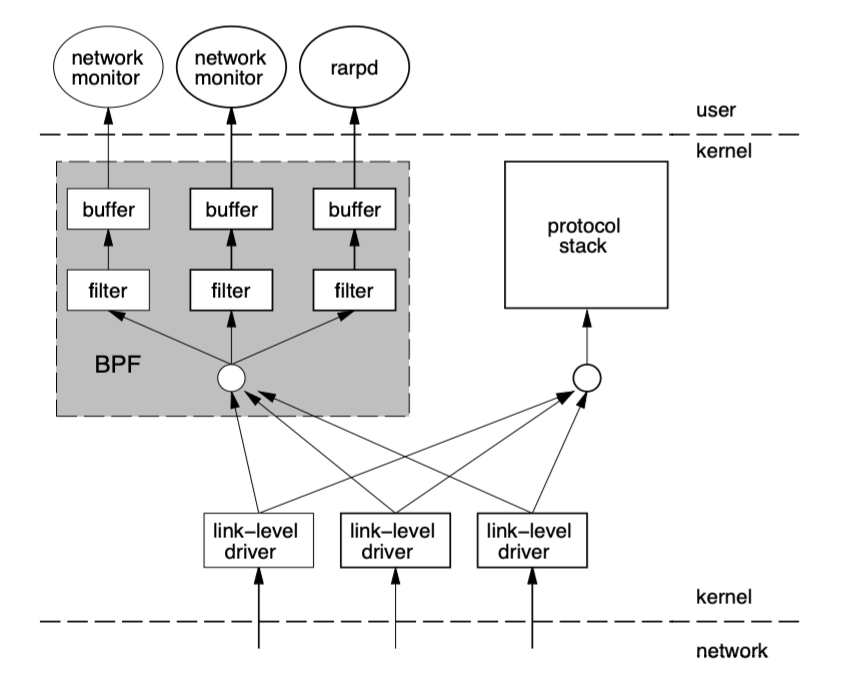
tcpdump就是采用 BPF 作为底层包过滤技术,我们可以在命令后面增加-d来查看tcpdump过滤条件的底层汇编指令。
$ tcpdump -d 'ip and tcp port 8080'
(000) ldh [12]
(001) jeq #0x800 jt 2 jf 12
(002) ldb [23]
(003) jeq #0x6 jt 4 jf 12
(004) ldh [20]
(005) jset #0x1fff jt 12 jf 6
(006) ldxb 4*([14]&0xf)
(007) ldh [x + 14]
(008) jeq #0x1f90 jt 11 jf 9
(009) ldh [x + 16]
(010) jeq #0x1f90 jt 11 jf 12
(011) ret #262144
(012) ret #0
什么是 eBPF
2014 年初,Alexei Starovoitov 实现了 eBPF(extended Berkeley Packet Filter)。经过重新设计,eBPF 演进为一个通用执行引擎,可基于此开发性能分析工具、软件定义网络等诸多场景。eBPF 最早出现在 3.18 内核中,此后原来的 BPF 就被称为经典 BPF,缩写 cBPF(classic BPF),cBPF 虚拟机只在内核中可用,用于过滤网络数据包,与用户空间程序没有交互,因此被称为 “包过滤器”,而 eBPF 从内核空间扩展到用户空间,这也成为了 BPF 技术的转折点。
cBPF 已经基本废弃,现在,Linux 内核只运行 eBPF,内核会将加载的 cBPF 字节码透明地转换成 eBPF 再执行。没有特别说明,现在的 BPF 一般指的是 BPF 这项技术,而不再是任何首字母缩写词。
cBPF 和 eBPF 对比
eBPF 新的设计针对现代硬件进行了优化,所以 eBPF 生成的指令集比旧的 BPF 解释器生成的机器码执行得更快。扩展版本也增加了虚拟机中的寄存器数量,将原有的 2 个 32 位寄存器增加到 10 个 64 位寄存器。由于寄存器数量和宽度的增加,开发人员可以使用函数参数自由交换更多的信息,编写更复杂的程序。总之,这些改进使 eBPF 版本的速度比原来的 BPF 提高了 4 倍。
| 维度 | cBPF | eBPF |
|---|---|---|
| 内核版本 | Linux 2.1.75(1997年) | Linux 3.18(2014年)[4.x for kprobe/uprobe/tracepoint/perf-event] |
| 寄存器数目 | 2个:A,X |
10个:r0–r9,另外r10是一个只读的帧指针 |
| 寄存器宽度 | 32位 | 64位 |
| 存储 | 16 个内存位: M[0–15] | 512 字节堆栈,无限制大小的 “map” 存储 |
| 限制的内核调用 | 常有限,仅限于 JIT 特定 | 有限,通过 bpf_call() 指令调用 |
| 目标事件 | 数据包、 seccomp-BPF | 数据包、内核函数、用户函数、跟踪点 PMCs 等 |
eBPF 与内核模块对比
eBPF 相比于直接修改内核和编写内核模块提供了一种新的内核可编程的选项。eBPF 程序架构强调安全性和稳定性,看上去很像内核模块,但与内核模块不同,eBPF 程序不需要重新编译内核,并且可以确保 eBPF 程序运行完成,而不会造成系统的崩溃。
| 维度 | Linux 内核模块 | eBPF |
|---|---|---|
| kprobes/tracepoints | 支持 | 支持 |
| 安全性 | 可能引入安全漏洞或导致内核 Panic | 通过验证器进行检查,可以保障内核安全 |
| 内核函数 | 可以调用内核函数 | 只能通过 BPF Helper 函数调用 |
| 编译性 | 需要编译内核 | 不需要编译内核,引入头文件即可 |
| 运行 | 基于相同内核运行 | 基于稳定 ABI 的 BPF 程序可以编译一次,各处运行 |
| 与应用程序交互 | 打印日志或文件 | 通过 perf_event 或 map 结构 |
| 数据结构丰富性 | 一般 | 丰富 |
| 入门门槛 | 高 | 低 |
| 升级 | 需要卸载和加载,可能导致处理流程中断 | 原子替换升级,不会造成处理流程中断 |
| 内核内置 | 视情况而定 | 内核内置支持 |
eBPF 可以用来做什么
一个 eBPF 程序会附加到指定的内核代码路径中,当执行该代码路径时,会执行对应的 eBPF 程序。鉴于它的起源,eBPF 特别适合编写网络程序,将该网络程序附加到网络 socket,进行流量过滤、流量分类以及执行网络分类器的动
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 4510
4510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









