







 超级会员免费看
超级会员免费看
不平衡数据集指的是数据集各个类别的样本数目相差巨大,例如2000的人群中,某疾病的发生只有100 (5%)人,那么疾病发生与不发生为 1:19。这种情况下的数据称为不平衡数据。在真实世界中,不管是二分类或三分类,不平衡数据的现象普遍存在,尤其是罕见病领域。
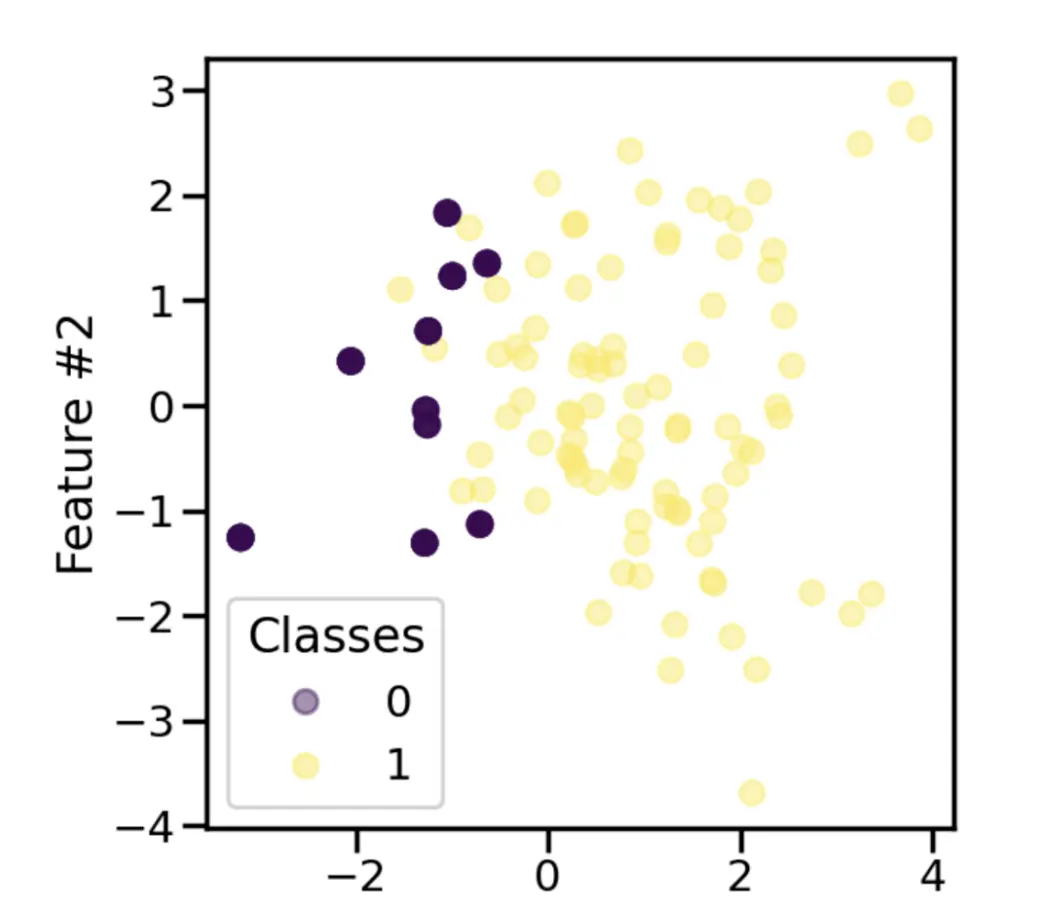
image.png
如果训练集的90%的样本是属于同一个类别,而我们的模型将所有的样本都分类为该类,在这种情况下,该分类器是无效的,尽管最后的分类准确度为90%。
所以在数据不均衡时,准确度(Accuracy)这个评价指标参考意义就不大了。实际上,如果不均衡比例超过4:1,分类器模型就会偏向于占比大的类别。
不平衡数据集的主要处理方法
这里我们主要介绍目前常用的方法。
- 对数据集进行重采样
- 评价指标选用召回率
接下来,我们将进行案例展示,随机产生5000份样本数据,预测变量为2分类。分别介绍不同的采样方法及最后评价指标。

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











