







 本文深入解析了Faiss库中的聚类算法实现,包括初始化聚类参数、使用Flat索引以及训练过程中的数据校验、迭代更新聚类中心。在训练阶段,首先检查数据量是否满足要求,然后进行数据采样或警告。接着,详细介绍了初始化聚类中心和迭代更新的过程,包括计算新簇中心和处理空簇。整个过程涉及并行计算和关键函数的实现,为理解Faiss聚类提供了清晰的视角。
本文深入解析了Faiss库中的聚类算法实现,包括初始化聚类参数、使用Flat索引以及训练过程中的数据校验、迭代更新聚类中心。在训练阶段,首先检查数据量是否满足要求,然后进行数据采样或警告。接着,详细介绍了初始化聚类中心和迭代更新的过程,包括计算新簇中心和处理空簇。整个过程涉及并行计算和关键函数的实现,为理解Faiss聚类提供了清晰的视角。
目录
首先,从宏观的角度来一张Faiss聚类的流程,如下图:
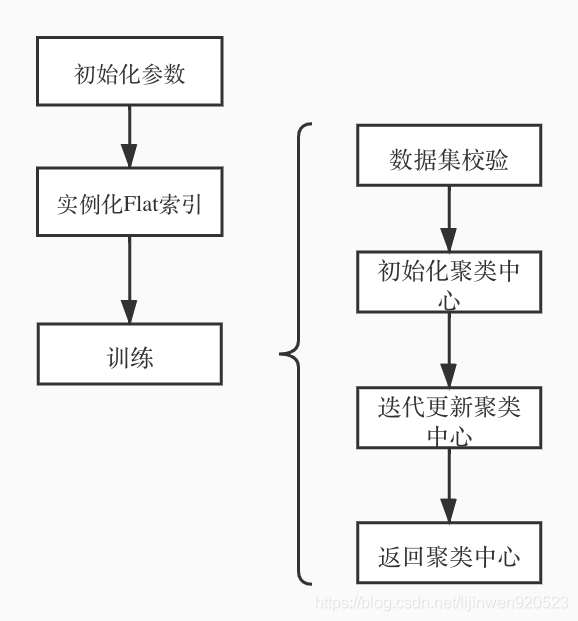
整体的代码如下:
float kmeans_clustering (size_t d, size_t n, size_t k,
const float *x,
float *centroids)
{
Clustering clus (d, k); // 初始化参数
clus.verbose = d * n * k > (1L << 30);
// display logs if > 1Gflop per iteration
IndexFlatL2 index (d); // 实例化flat索引
clus.train (n, x, index); // 训练,也就是聚类
memcpy(centroids, clus.centroids.data(), sizeof(*centroids) * d * k);
return clus.iteration_stats.back().obj; //返回各样本点到各自聚类中心的距离之和
}大致分为三大步骤:初始化,实例化量化索引,以及训练。
1. 初始化
聚类参数较多,罗列出几个比较重要的参数
/** Class for the clustering parameters. Can be passed to the
* constructor of the Clustering object.
*/
struct ClusteringParameters {
int niter; ///< clustering iterations
int nredo; ///< redo clustering this many times and keep best
bool spherical; ///< do we want normalized centroids?
bool int_centroids; ///< round centroids coordinates to integer
int min_points_per_centroid; ///< otherwise you get a warning
int max_points_per_centroid; ///< to limit size of dataset
};niter:每一次聚类需要迭代的次数
nredo: 训练的时候,聚类的次数
spherical: 是否需要归一化
update_index:重复训练的时候是否需要更新索引
min_points_per_centroid: 每一簇最小样本数,低于这个数会warning,但是还是会继续
max_points_per_centroid: 每一簇最大样本数,超过这个数会采样,后文会分析。
聚类是ClusteringParameters的子类,多了两个需要指定的参数d和k,和一个存储聚类中心的vector(centroids):
struct Clustering: ClusteringParameters {
typedef Index::idx_t idx_t;
size_t d; ///< dimension of the vectors
size_t k; ///< nb of centroids
/** centroids (k * d)
* if centroids are set on input to train,  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1416
1416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











