 Node.js学习:调试、HTTP服务器与事件
Node.js学习:调试、HTTP服务器与事件





 本文介绍了Node.js的基础知识,包括使用console.log进行调试,建立HTTP服务器,展示了同步与异步I/O的区别,详细解释了事件及事件循环的工作原理,还探讨了模块系统、包管理和npm的本地与全局模式。
本文介绍了Node.js的基础知识,包括使用console.log进行调试,建立HTTP服务器,展示了同步与异步I/O的区别,详细解释了事件及事件循环的工作原理,还探讨了模块系统、包管理和npm的本地与全局模式。
本次学习内容
编写第一个Node.js程序;
异步式I/O和事件循环;
模块和包;
调试。
console.log('Hello World');
页面输出hello world
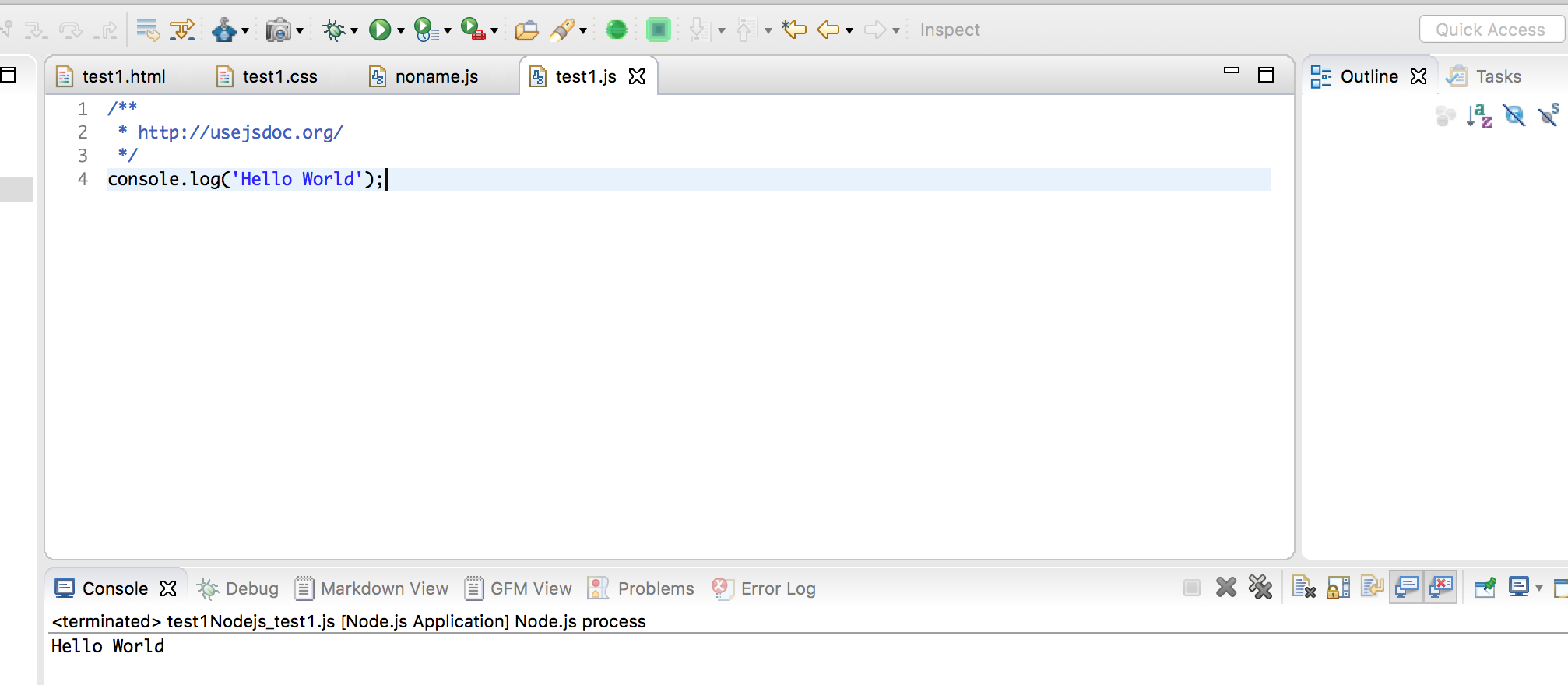
console.log('%s: %d', 'Hello', 25);
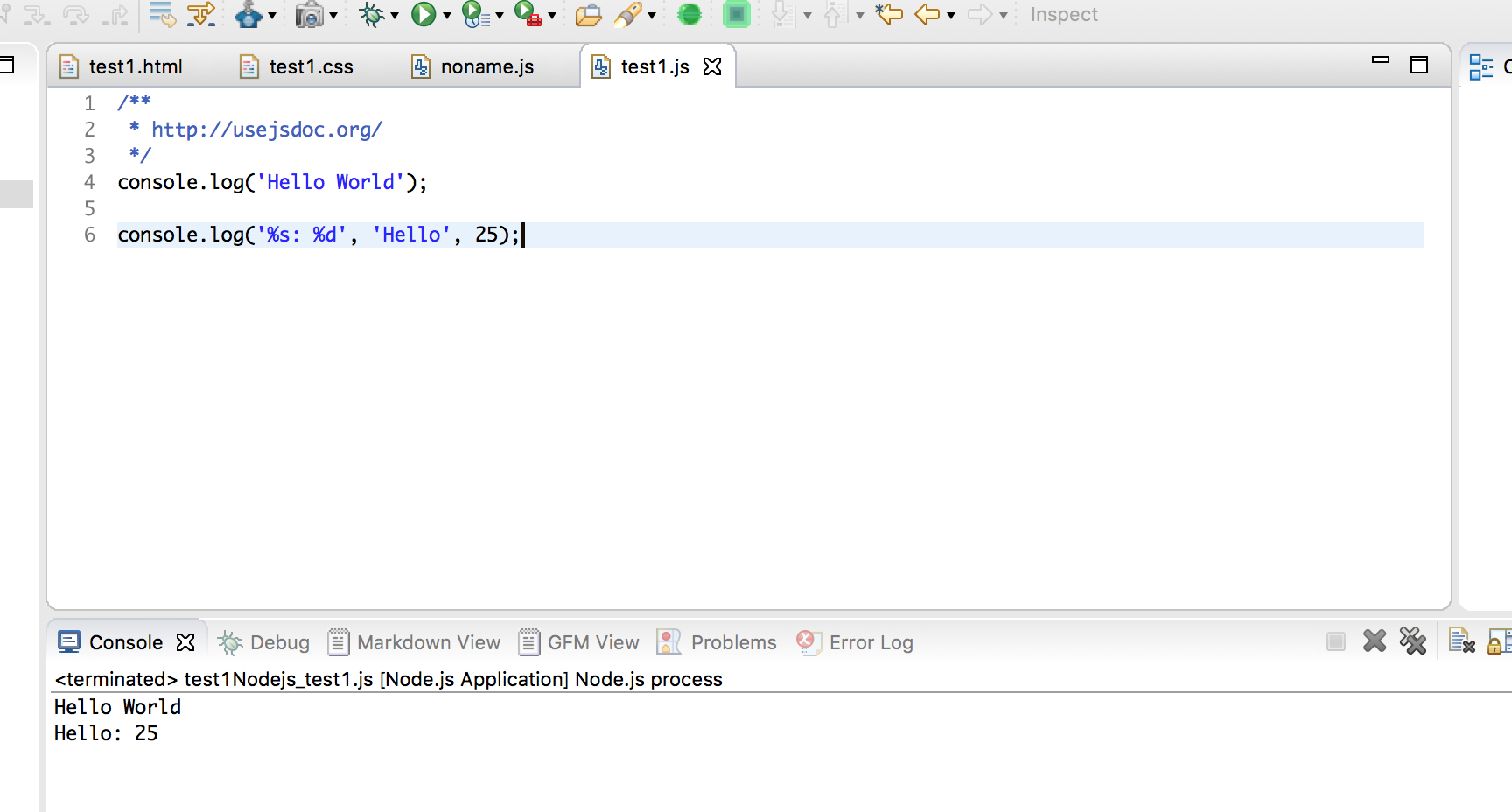
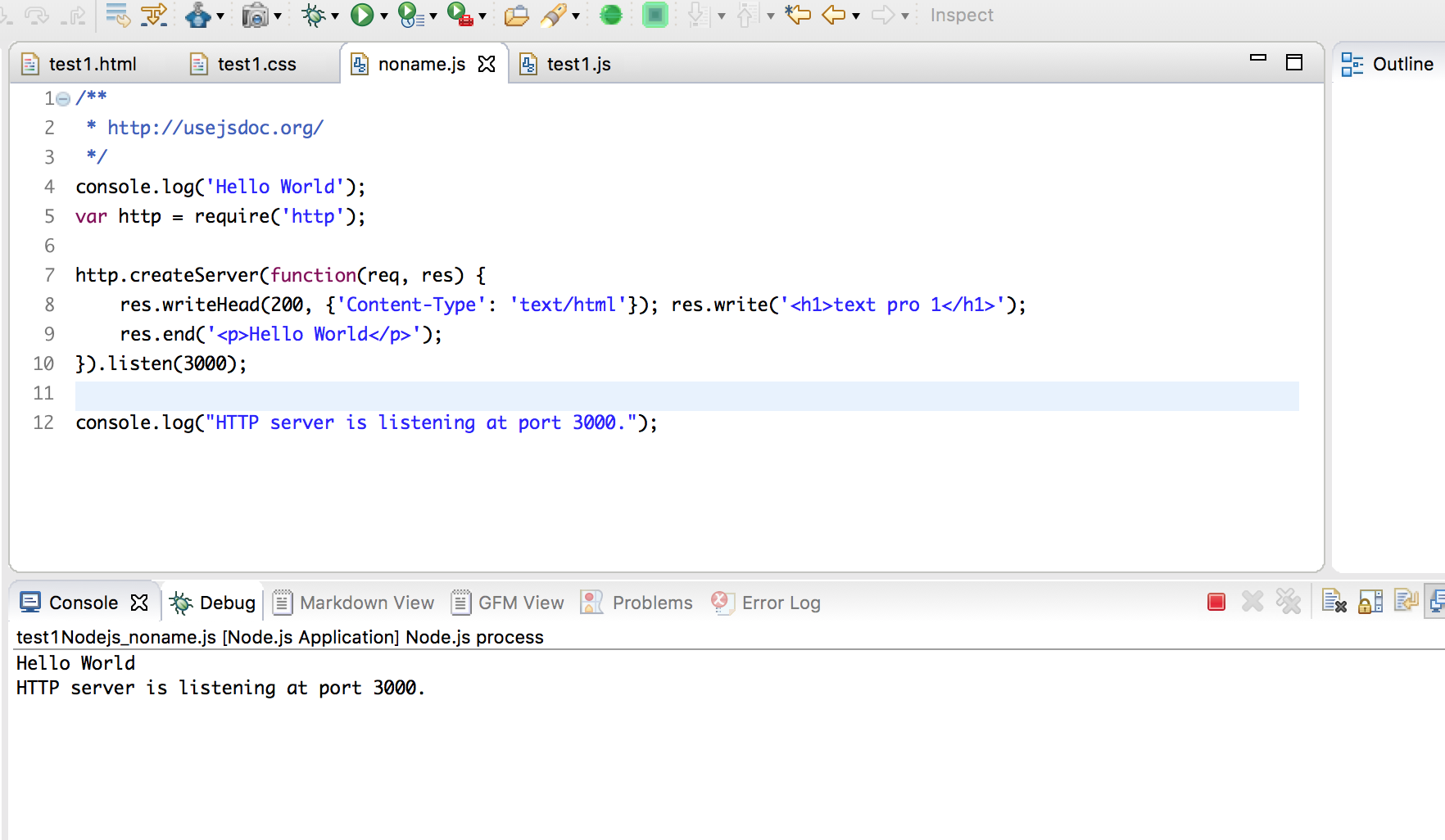
建立 HTTP 服务器
//app.js
var http = require('http');
http.createServer(function(req, res) {res.writeHead(200, {'Content-Type': 'text/html'});res.write('<h1>Node.js</h1>');
res.end('<p>Hello World</p>');
res.end('<p>Hello World</p>');
}).listen(3000);
console.log("HTTP server is listening at port 3000.");
console.log("HTTP server is listening at port 3000.");
接下来运行 node app.js命令,打开浏览器访问 http://127.0.0.1:3000,即可看到图3-2所示的内容。
阻塞与线程
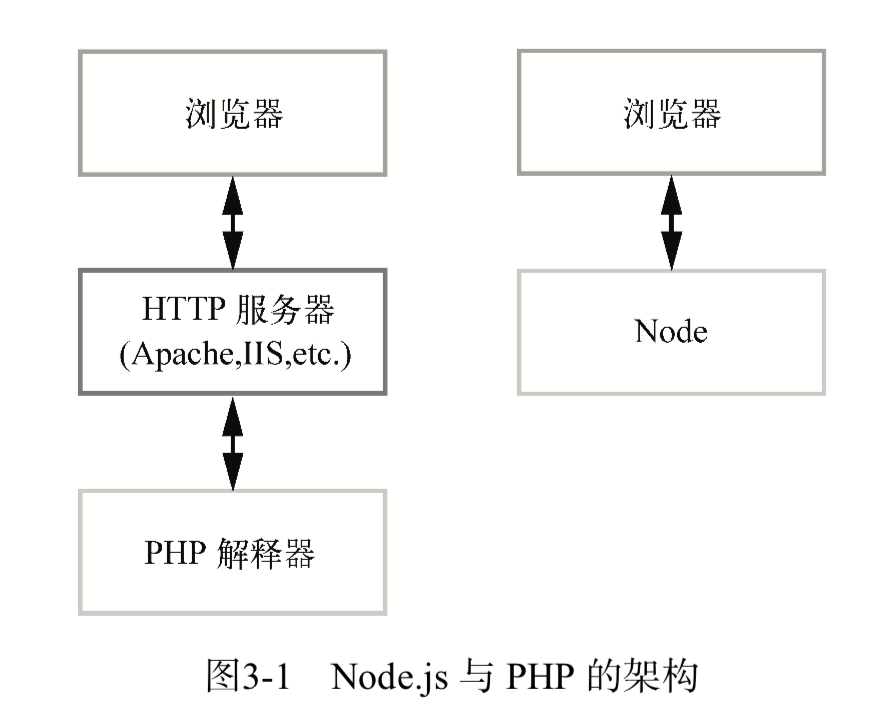
什么是阻塞(block)呢?线程在执行中如果遇到磁盘读写或网络通信(统称为 I/O 操作),通常要耗费较长的时间,这时操作系统会剥夺这个线程的 CPU 控制权,使其暂停执行,同时将资源让给其他的工作线程,这种线程调度方式称为 阻塞。当 I/O 操作完毕时,操作系统将这个线程的阻塞状态解除,恢复其对CPU的控制权,令其继续执行。这种 I/O 模式就是通常的同步式 I/O(Synchronous I/O)或阻塞式 I/O (Blocking I/O)。
相应地,异步式 I/O (Asynchronous I/O)或非阻塞式 I/O (Non-blocking I/O)则针对所有 I/O 操作不采用阻塞的策略。当线程遇到 I/O 操作时,不会以阻塞的方式等待 I/O 操作的完成或数据的返回,而只是将 I/O 请求发送给操作系统,继续执行下一条语句。当操作系统完成 I/O 操作时,以事件的形式通知执行 I/O 操作的线程,线程会在特定时候处理这个事件。为了处理异步 I/O,线程必须有事件循环,不断地检查有没有未处理的事件,依次予以处理。
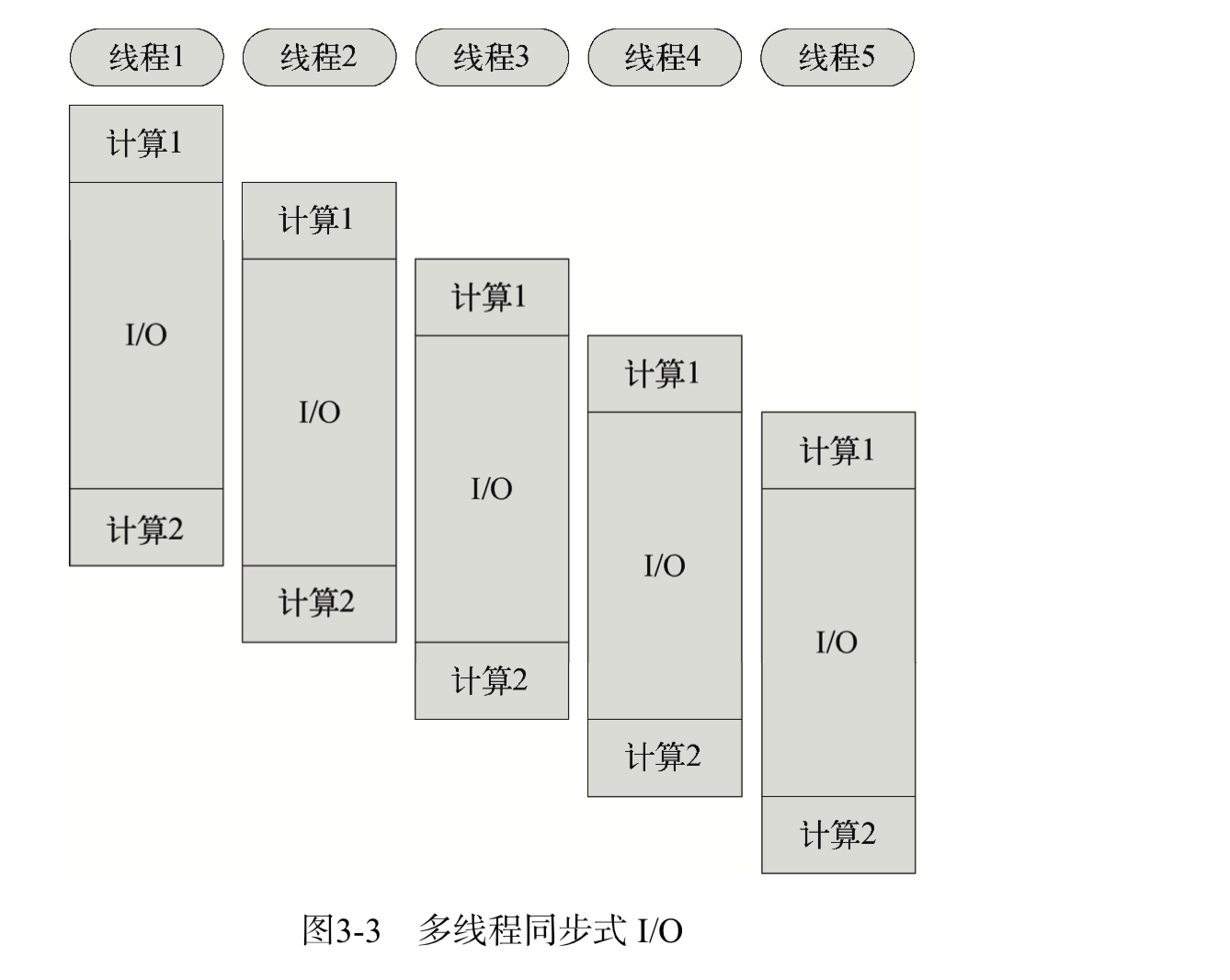
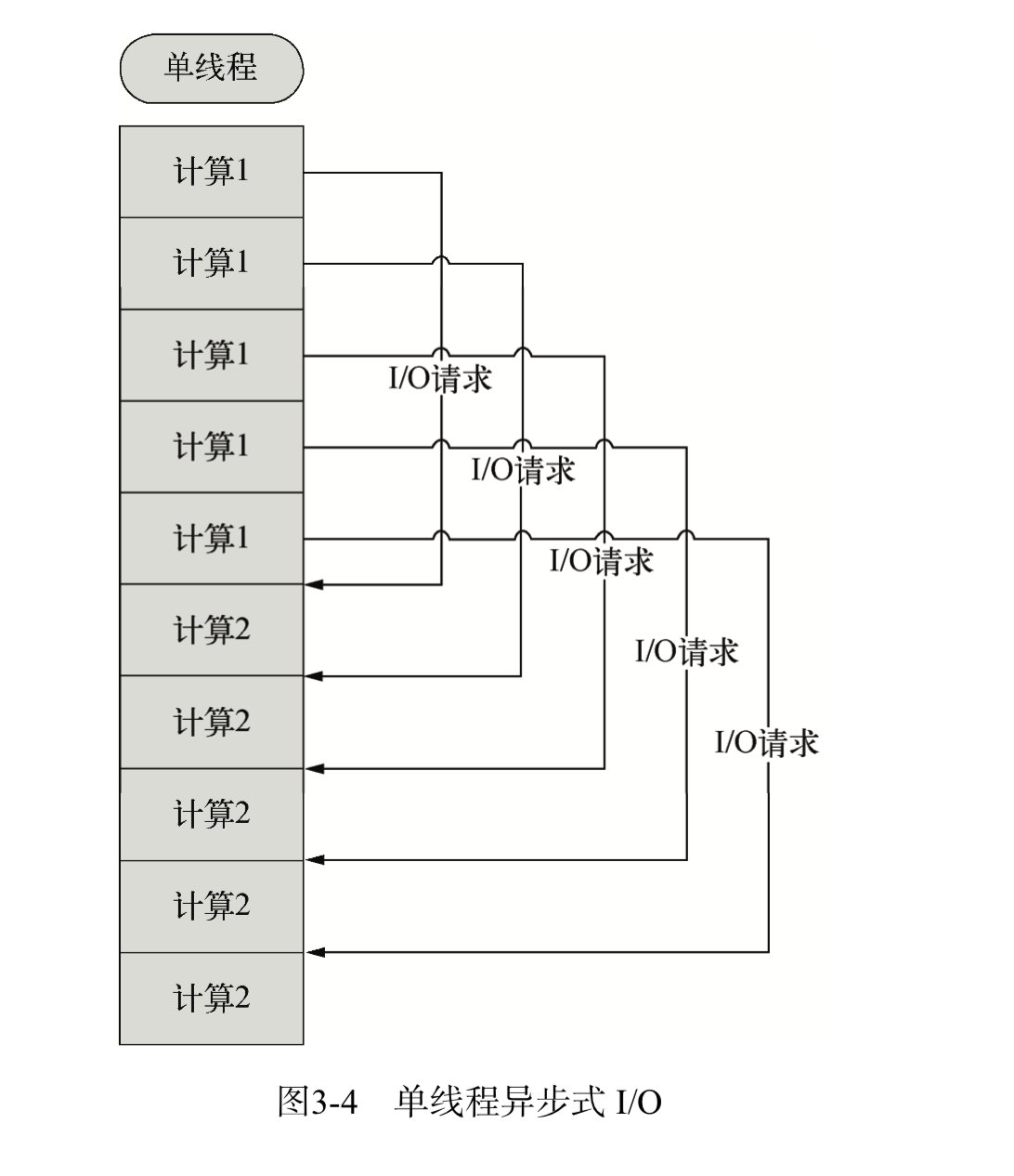
阻塞模式下,一个线程只能处理一项任务,要想提高吞吐量必须通过多线程。而非阻塞模式下,一个线程永远在执行计算操作,这个线程所使用的 CPU 核心利用率永远是 100%,I/O 以事件的方式通知。在阻塞模式下,多线程往往能提高系统吞吐量,因为一个线程阻塞时还有其他线程在工作,多线程可以让 CPU 资源不被阻塞中的线程浪费。而在非阻塞模式下,线程不会被 I/O 阻塞,永远在利用 CPU。多线程带来的好处仅仅是在多核 CPU 的情况下利用更多的核,而Node.js的单线程也能带来同样的好处。这就是为什么 Node.js 使用了单线程、非阻塞的事件编程模式。
图3-3 和图3-4 分别是多线程同步式 I/O 与单线程异步式 I/O 的示例。假设我们有一项工作,可以分为两个计算部分和一个 I/O 部分,I/O 部分占的时间比计算多得多(通常都是这样)。如果我们使用阻塞 I/O,那么要想获得高并发就必须开启多个线程。而使用异步式 I/O时,单线程即可胜任。
让我们看看在 Node.js 中如何用异步的方式读取一个文件,下面是一个例子://readfile.js
var fs = require('fs');
fs.readFile('file.txt', 'utf-8',
fs.readFile('file.txt', 'utf-8', function(err, data) {
if (err) {console.error(err);
} else {console.log(data);
}});
console.log('end.');
Node.js 也提供了同步读取文件的 API://readfilesync.js运行的结果如下:
end.Contents of the file.
var fs = require('fs');
var data = fs.readFileSync('file.txt', 'utf-8');console.log(data);
console.log('end.');
console.log('end.');
运行的结果与前面不同,如下所示:
$ node readfilesync.js
Contents of the file.end.
 ]
]
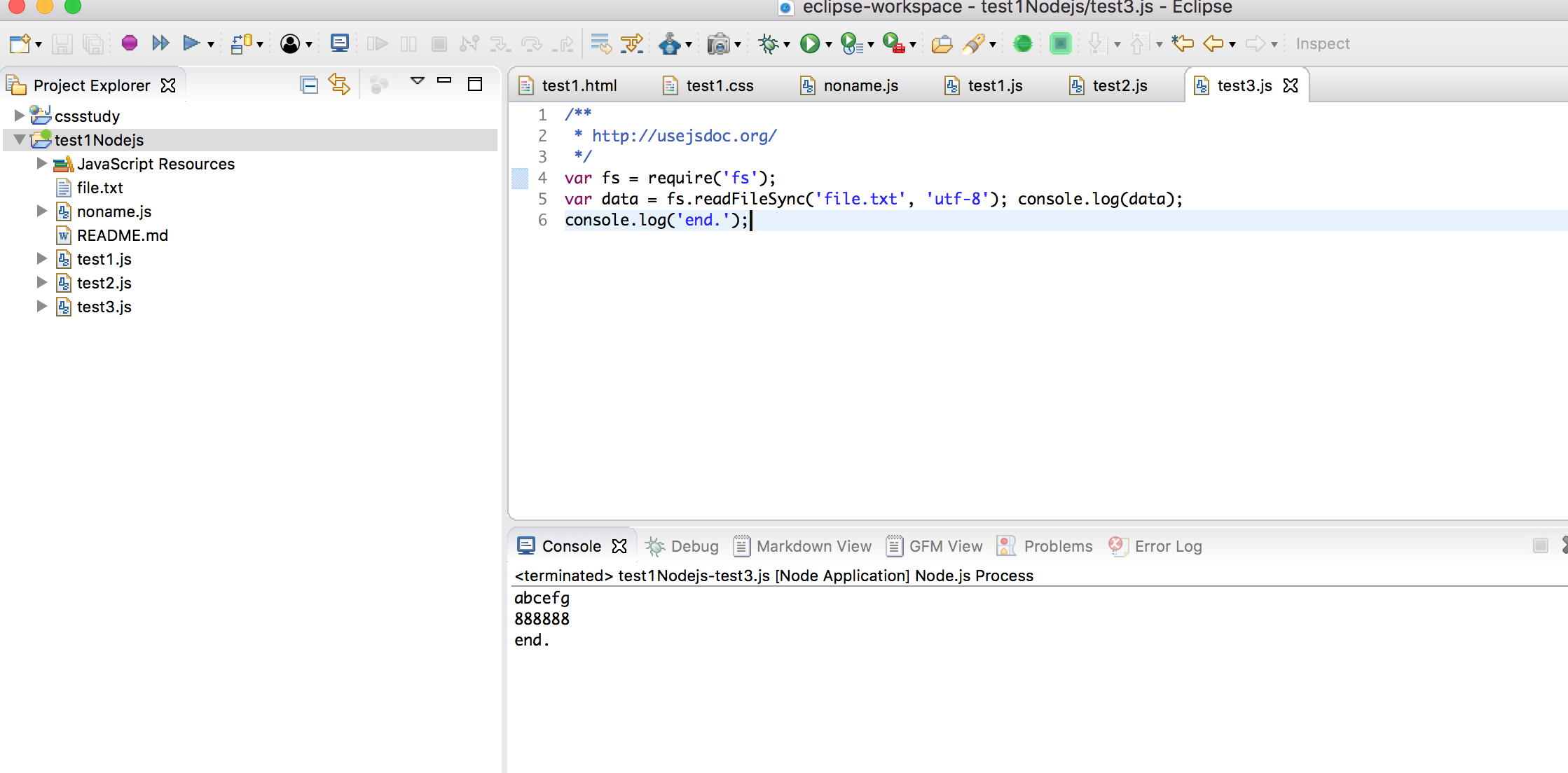
同步式读取文件的方式比较容易理解,将文件名作为参数传入 fs.readFileSync 函数,阻塞等待读取完成后,将文件的内容作为函数的返回值赋给 data 变量,接下来控制台输出 data的值,最后输出 end.。
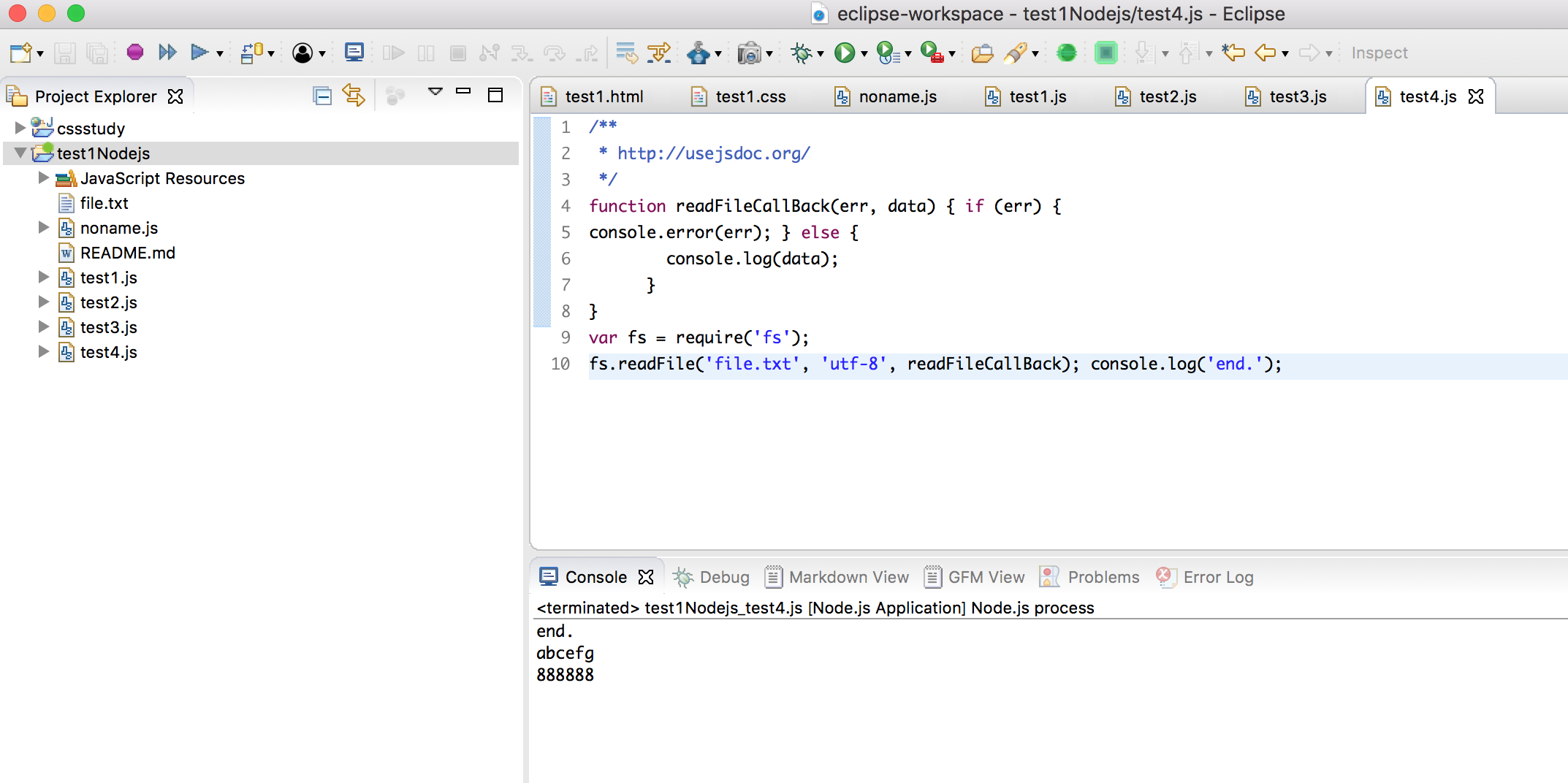
异步式读取文件就稍微有些违反直觉了,end.先被输出。要想理解结果,我们必须先知道在 Node.js 中,异步式 I/O 是通过回调函数来实现的。fs.readFile 接收了三个参数,第一个是文件名,第二个是编码方式,第三个是一个函数,我们称这个函数为回调函数。JavaScript 支持匿名的函数定义方式,譬如我们例子中回调函数的定义就是嵌套在fs.readFile 的参数表中的。这种定义方式在 JavaScript 程序中极为普遍,与下面这种定义方式实现的功能是一致的:
//readfilecallback.js
function readFileCallBack(err, data) {if (err) {
console.error(err);} else {
console.log(data);
}
}
var fs = require('fs');
fs.readFile('file.txt', 'utf-8', readFileCallBack);console.log('end.');
fs.readFile 调用时所做的工作只是将异步式 I/O 请求发送给了操作系统,然后立即返回并执行后面的语句,执行完以后进入事件循环监听事件。当 fs 接收到 I/O 请求完成的事件时,事件循环会主动调用回调函数以完成后续工作。因此我们会先看到 end.,再看到file.txt 文件的内容。
事件
//event.js
var EventEmitter = require('events').EventEmitter;
var event = new EventEmitter();
event.on('some_event', function() {console.log('some_event occured.');
});
setTimeout(function() {event.emit('some_event');
}, 1000);
运行这段代码,1秒后控制台输出了 some_event occured.。其原理是 event 对象注册了事件 some_event 的一个监听器,然后我们通过 setTimeout 在1000毫秒以后向event 对象发送事件some_event,此时会调用 some_event的监听器。
Node.js 在什么时候会进入事件循环呢?答案是 Node.js 程序由事件循环开始,到事件循
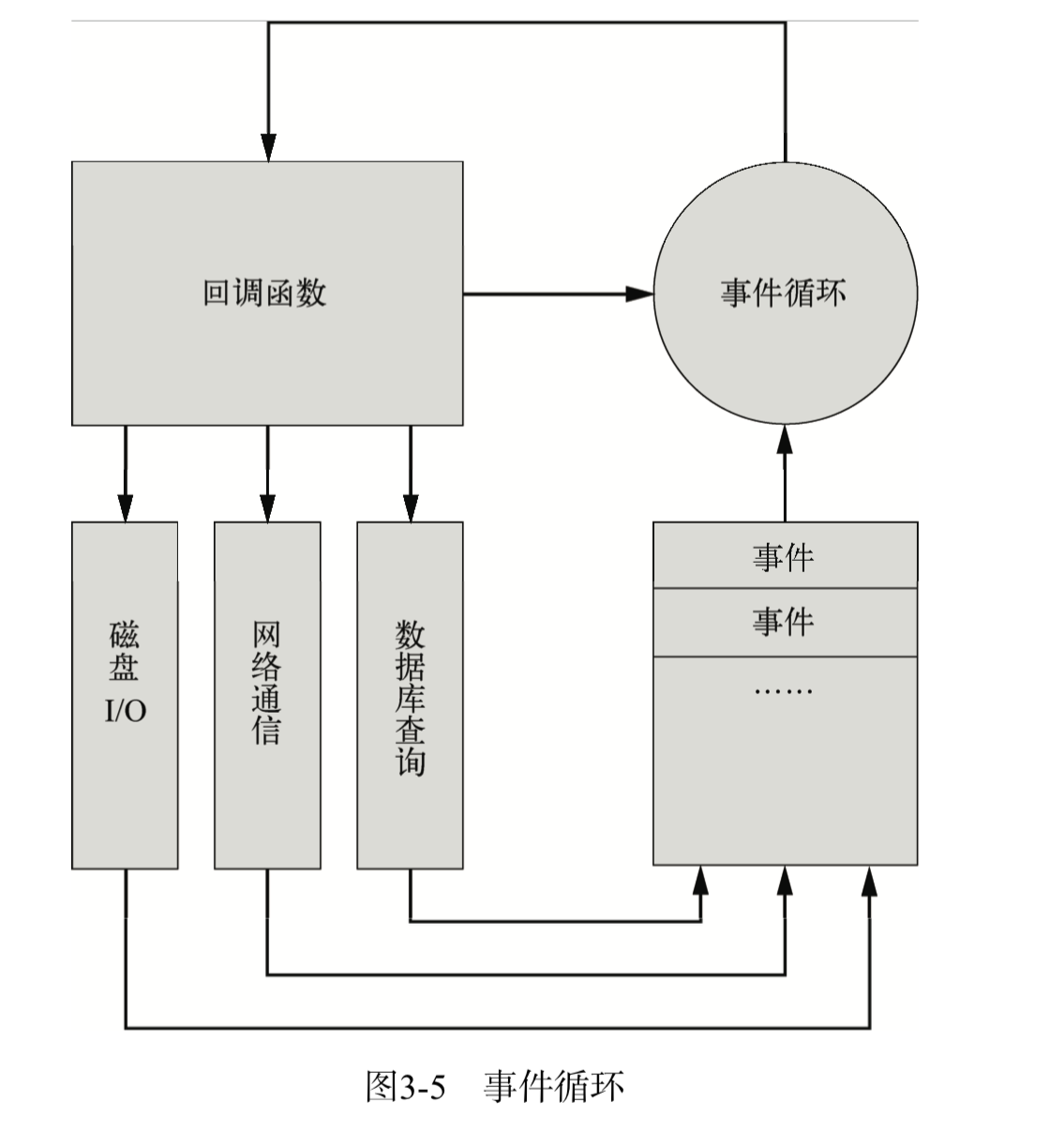
环结束,所有的逻辑都是事件的回调函数,所以 Node.js 始终在事件循环中,程序入口就是事件循环第一个事件的回调函数。事件的回调函数在执行的过程中,可能会发出 I/O 请求或直接发射(emit)事件,执行完毕后再返回事件循环,事件循环会检查事件队列中有没有未处理的事件,直到程序结束。图3-5说明了事件循环的原理。
与其他语言不同的是,Node.js 没有显式的事件循环,类似 Ruby 的 EventMachine::run()的 函 数 在 N o d e . j s 中 是 不 存 在 的 。N o d e . j s 的 事 件 循 环 对 开 发 者 不 可 见 ,由 l i b e v 库 实 现 。l i b e v支持多种类型的事件,如 ev_io、ev_timer、ev_signal、ev_idle 等,在 Node.js 中均被EventEmitter 封装。libev 事件循环的每一次迭代,在 Node.js 中就是一次 Tick,libev 不断检查是否有活动的、可供检测的事件监听器,直到检测不到时才退出事件循环,进程结束。
什么是模块;
如何创建并加载模块;
如何创建一个包;
如何使用包管理器 ;
模块是 Node.js 应用程序的基本组成部分,文件和模块是一一对应的。换言之,一个Node.js 文件就是一个模块,这个文件可能是 JavaScript 代码、JSON 或者编译过的 C/C++ 扩展。
创建模块
在 Node.js 中,创建一个模块非常简单,因为一个文件就是一个模块,我们要关注的问题仅仅在于如何在其他文件中获取这个模块。Node.js 提供了 exports 和 require 两个对象,其中 exports 是模块公开的接口,require 用于从外部获取一个模块的接口,即所获取模块的 exports 对象。
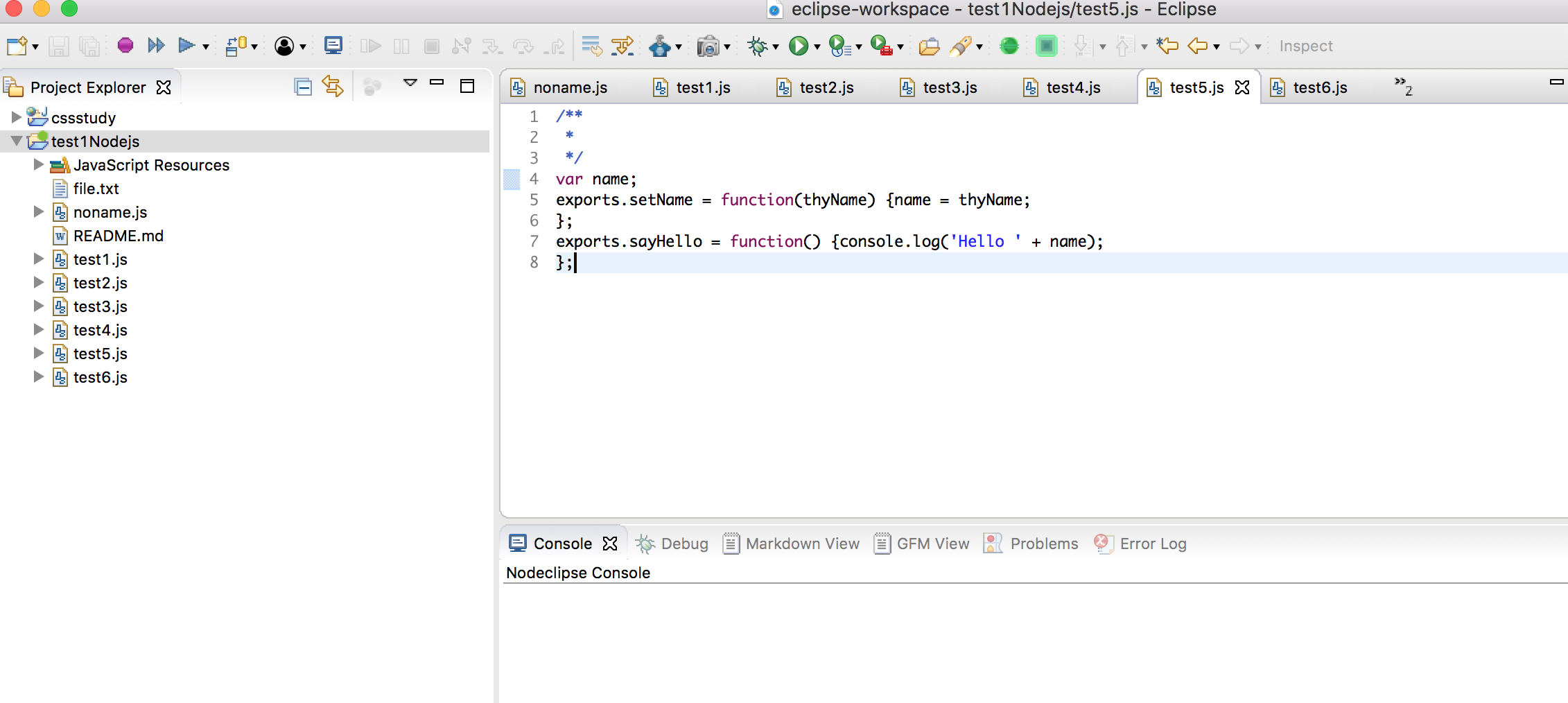
让我们以一个例子来了解模块。创建一个 module.js 的文件,内容是://module.js
var name;
exports.setName = function(thyName) {name = thyName;
};
exports.sayHello = function() {console.log('Hello ' + name);
};
在同一目录下创建 getmodule.js,内容是: 9//getmodule.js
var myModule = require('./module');
myModule.setName('BYVoid');
myModule.sayHello();
运行node getmodule.js,结果是:Hello BYVoid
在以上示例中,module.js 通过 exports 对象把 setName 和 sayHello 作为模块的访问接口,在 getmodule.js 中通过 require('./module') 加载这个模块,然后就可以直接访问 module.js 中 exports 对象的成员函数了。
这种接口封装方式比许多语言要简洁得多,同时也不失优雅,未引入违反语义的特性,符合传统的编程逻辑。在这个基础上,我们可以构建大型的应用程序,npm 提供的上万个模块都是通过这种简单的方式搭建起来的。
单次加载
上面这个例子有点类似于创建一个对象,但实际上和对象又有本质的区别,因为require 不会重复加载模块,也就是说无论调用多少次 require,获得的模块都是同一个。我们在 getmodule.js 的基础上稍作修改:
//loadmodule.js
var hello1 = require('./module');hello1.setName('BYVoid');
var hello2 = require('./module');hello2.setName('BYVoid 2');
hello1.sayHello();
覆盖 exports有时候我们只是想把一个对象封装到模块中,例如:
//singleobject.jsfunction Hello() {
var name;
this.setName = function (thyName) {name = thyName;
};
this.sayHello = function () {console.log('Hello ' + name);
};};
3.3 模块和包 37
exports.Hello = Hello;
此时我们在其他文件中需要通过 require('./singleobject').Hello 来获取
Hello 对象,这略显冗余,可以用下面方法稍微简化://hello.js
function Hello() {var name;
this.setName = function(thyName) {
name = thyName;
name = thyName; 4
};
this.sayHello = function() {console.log('Hello ' + name);
};};
module.exports = Hello;
这样就可以直接获得这个对象了:
//gethello.js
var Hello = require('./hello');
hello = new Hello();hello.setName('BYVoid');hello.sayHello();
注意,模块接口的唯一变化是使用 module.exports = Hello 代替了 exports.Hello=Hello。在外部引用该模块时,其接口对象就是要输出的 Hello 对象本身,而不是原先的exports。
事实上,exports 本身仅仅是一个普通的空对象,即 {},它专门用来声明接口,本质上是通过它为模块闭包1的内部建立了一个有限的访问接口。因为它没有任何特殊的地方,所以可以用其他东西来代替,譬如我们上面例子中的 Hello 对象。
创建包
包是在模块基础上更深一步的抽象,Node.js 的包类似于 C/C++ 的函数库或者 Java/.Net的类库。它将某个独立的功能封装起来,用于发布、更新、依赖管理和版本控制。Node.js 根据 CommonJS 规范实现了包机制,开发了 npm来解决包的发布和获取需求。
package.json 必须在包的顶层目录下; 二进制文件应该在 bin 目录下;
JavaScript 代码应该在 lib 目录下;
文档应该在 doc 目录下;
单元测试应该在 test 目录下。
Node.js 对包的要求并没有这么严格,只要顶层目录下有 package.json,并符合一些规范即可。当然为了提高兼容性,我们还是建议你在制作包的时候,严格遵守 CommonJS 规范。
1. 作为文件夹的模块
模块与文件是一一对应的。文件不仅可以是 JavaScript 代码或二进制代码,还可以是一个文件夹。最简单的包,就是一个作为文件夹的模块。下面我们来看一个例子,建立一个叫做 somepackage 的文件夹,在其中创建 index.js,内容如下:
//somepackage/index.js
exports.hello = function() {console.log('Hello.');
};
然后在 somepackage 之外建立 getpackage.js,内容如下://getpackage.js
var somePackage = require('./somepackage');somePackage.hello();
运行 node getpackage.js,控制台将输出结果 Hello.。
3.3 模块和包
我们使用这种方法可以把文件夹封装为一个模块,即所谓的包。包通常是一些模块的集合,在模块的基础上提供了更高层的抽象,相当于提供了一些固定接口的函数库。通过定制package.json,我们可以创建更复杂、更完善、更符合规范的包用于发布。
2. package.json
在前面例子中的 somepackage 文件夹下,我们创建一个叫做 package.json 的文件,内容如下所示:
{
"main" : "./lib/interface.js"
}
然后将 index.js 重命名为 interface.js 并放入 lib 子文件夹下。以同样的方式再次调用这个包,依然可以正常使用。 4Node.js 在调用某个包时,会首先检查包中 package.json 文件的 main 字段,将其作为
包的接口模块,如果 package.json 或 main 字段不存在,会尝试寻找 index.js 或 index.node 作为包的接口。
package.json 是 CommonJS 规定的用来描述包的文件,完全符合规范的 package.json 文件应该含有以下字段。
name:包的名称,必须是唯一的,由小写英文字母、数字和下划线组成,不能包含空格。
description:包的简要说明。
version:符合语义化版本识别1规范的版本字符串。
keywords:关键字数组,通常用于搜索。
maintainers:维护者数组,每个元素要包含 name、email (可选)、web (可选)字段。
contributors:贡献者数组,格式与maintainers相同。包的作者应该是贡献者数组的第一个元素。
bugs:提交bug的地址,可以是网址或者电子邮件地址。
licenses:许可证数组,每个元素要包含 type (许可证的名称)和 url (链接到 许可证文本的地址)字段。
repositories:仓库托管地址数组,每个元素要包含 type(仓库的类型,如 git )、 9url (仓库的地址)和 path (相对于仓库的路径,可选)字段。
dependencies:包的依赖,一个关联数组,由包名称和版本号组成。
下面是一个完全符合 CommonJS 规范的 package.json 示例:
{
"name": "mypackage",
"description": "Sample package for CommonJS. This package demonstrates the required
elements of a CommonJS package.",
"version": "0.7.0",
"keywords": [
"package",
"example"],
"maintainers": [
{
"name": "Bill Smith",
"email": "bills@example.com",
}
],
"contributors": [
{
"name": "BYVoid",
"web": "http://www.byvoid.com/"
}],
"bugs": {
"mail": "dev@example.com",
"web": "http://www.example.com/bugs"
},
"licenses": [
{
"type": "GPLv2",
"url": "http://www.example.org/licenses/gpl.html"
}],
"repositories": [
{
"type": "git",
"url": "http://github.com/BYVoid/mypackage.git"
}
],
"dependencies": {
"webkit": "1.2",
"ssl": {
"gnutls": ["1.0", "2.0"],
"openssl": "0.9.8"
}
}}
3.3 模块和包
Node.js包管理器,即npm是 Node.js 官方提供的包管理工具1,它已经成了 Node.js 包的标准发布平台,用于 Node.js 包的发布、传播、依赖控制。npm 提供了命令行工具,使你可以方便地下载、安装、升级、删除包,也可以让你作为开发者发布并维护包。
1. 获取一个包
使用 npm 安装包的命令格式为:
npm [install/i] [package_name]
例如你要安装 express,可以在命令行运行:$ npm install express
或者:
$ npm i express
随后你会看到以下安装信息:
npm http GET https://registry.npmjs.org/express
npm http 304 https://registry.npmjs.org/express
npm http GET https://registry.npmjs.org/mime/1.2.4
npm http GET https://registry.npmjs.org/mkdirp/0.3.0
npm http GET https://registry.npmjs.org/qs
npm http GET https://registry.npmjs.org/connect
npm http 200 https://registry.npmjs.org/mime/1.2.4
npm http 200 https://registry.npmjs.org/mkdirp/0.3.0
npm http 200 https://registry.npmjs.org/qs
npm http GET https://registry.npmjs.org/mime/-/mime-1.2.4.tgz
npm http GET https://registry.npmjs.org/mkdirp/-/mkdirp-0.3.0.tgz 7npm http 200 https://registry.npmjs.org/mime/-/mime-1.2.4.tgz
npm http 200 https://registry.npmjs.org/mkdirp/-/mkdirp-0.3.0.tgz
npm http 200 https://registry.npmjs.org/connect
npm http GET https://registry.npmjs.org/formidable
npm http 200 https://registry.npmjs.org/formidable
express@2.5.8 ./node_modules/express
npm http 200 https://registry.npmjs.org/mkdirp/-/mkdirp-0.3.0.tgz
npm http 200 https://registry.npmjs.org/connect
npm http GET https://registry.npmjs.org/formidable
npm http 200 https://registry.npmjs.org/formidable
express@2.5.8 ./node_modules/express
-- mime@1.2.4
-- mkdirp@0.3.0
-- qs@0.4.2
-- connect@1.8.5
此时 express 就安装成功了,并且放置在当前目录的 node_modules 子目录下。npm 在
获取 express 的时候还将自动解析其依赖,并获取 express 依赖的 mime、mkdirp、qs 和 connect。
2. 本地模式和全局模式
npm在默认情况下会从http://npmjs.org搜索或下载包,将包安装到当前目录的node_modules子目录下。

















 2601
2601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









