







 超级会员免费看
超级会员免费看
 双数组Trie树(DAT)是一种高效的Trie树实现,结合了数组的快速查询和链表的空间节省。本文介绍了DAT的基本概念、Java实现,以及在词典构建和分词中的应用,特别提到了Ansj库中的DAT应用和前向最大匹配分词算法。
双数组Trie树(DAT)是一种高效的Trie树实现,结合了数组的快速查询和链表的空间节省。本文介绍了DAT的基本概念、Java实现,以及在词典构建和分词中的应用,特别提到了Ansj库中的DAT应用和前向最大匹配分词算法。
双数组Trie树(Double-array Trie, DAT)是由三个日本人提出的一种Trie树的高效实现 [1],兼顾了查询效率与空间存储。Ansj便是用DAT(虽然作者宣称是三数组Trie树,但本质上还是DAT)构造词典用作初次分词,极大地节省了内存占用。本文将简要地介绍DAT,并实现了基于DAT的前向最大匹配的中文分词算法。
1. Trie树
两种实现
Trie树(也称为字典树、前缀树)是一种常被用于词检索的树结构,其思想非常简单:利用词的共同前缀以达到节省空间的目的;基本的实现有array与linked-list两种。array实现需要为每一个字符开辟一个字母表大小的数组:
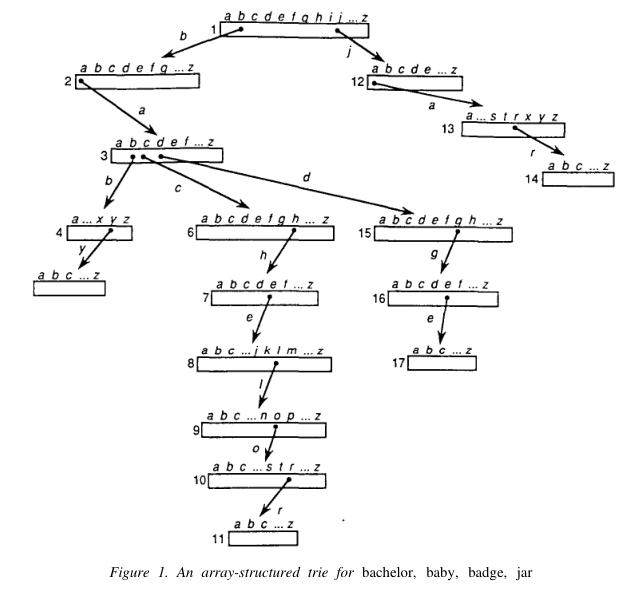
上图给出四个单词bachelor, baby, badge, jar的Trie树array实现示例图;对应的Java代码如下:
class TrieNode {
public Character value;
public TrieNode[] next = new TrieNode[65536]; // 65536 = 2^16
}虽然,array的查询时间复杂度为\(O(1)\);但是,从图中可以看出,存在着大量的空间浪费。当然,有人会想到用Hash

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 9872
9872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











