







 超级会员免费看
超级会员免费看
 本文介绍了如何使用VLLM进行大模型部署,通过FastAPI搭建API服务,实现基于浏览器和Postman的访问。讨论了VLLM的分布式多卡推理,利用Ray进行管理,并提供了安装和配置的详细步骤。此外,还提及了模型的源码部署和国内大模型的一致性接口设计。
本文介绍了如何使用VLLM进行大模型部署,通过FastAPI搭建API服务,实现基于浏览器和Postman的访问。讨论了VLLM的分布式多卡推理,利用Ray进行管理,并提供了安装和配置的详细步骤。此外,还提及了模型的源码部署和国内大模型的一致性接口设计。
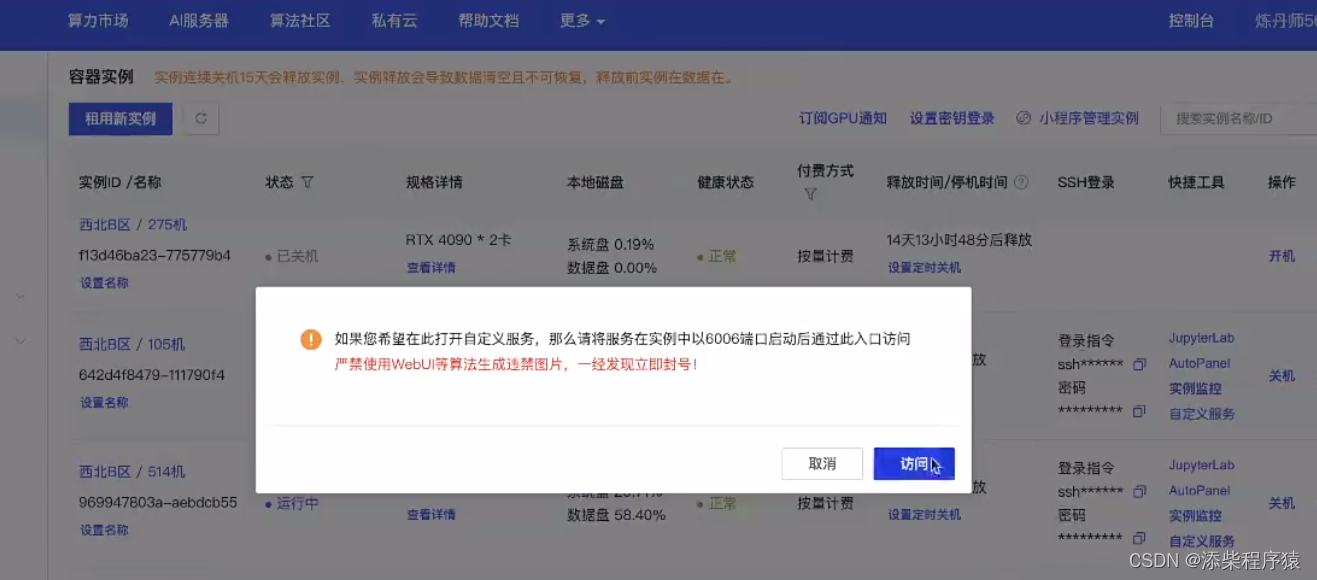
上一节我们部署了vllm,然后我们部署了以后,走到autoDL中,点击自定义服务,然后点击访问
就可以在浏览器中进行访问vllm了
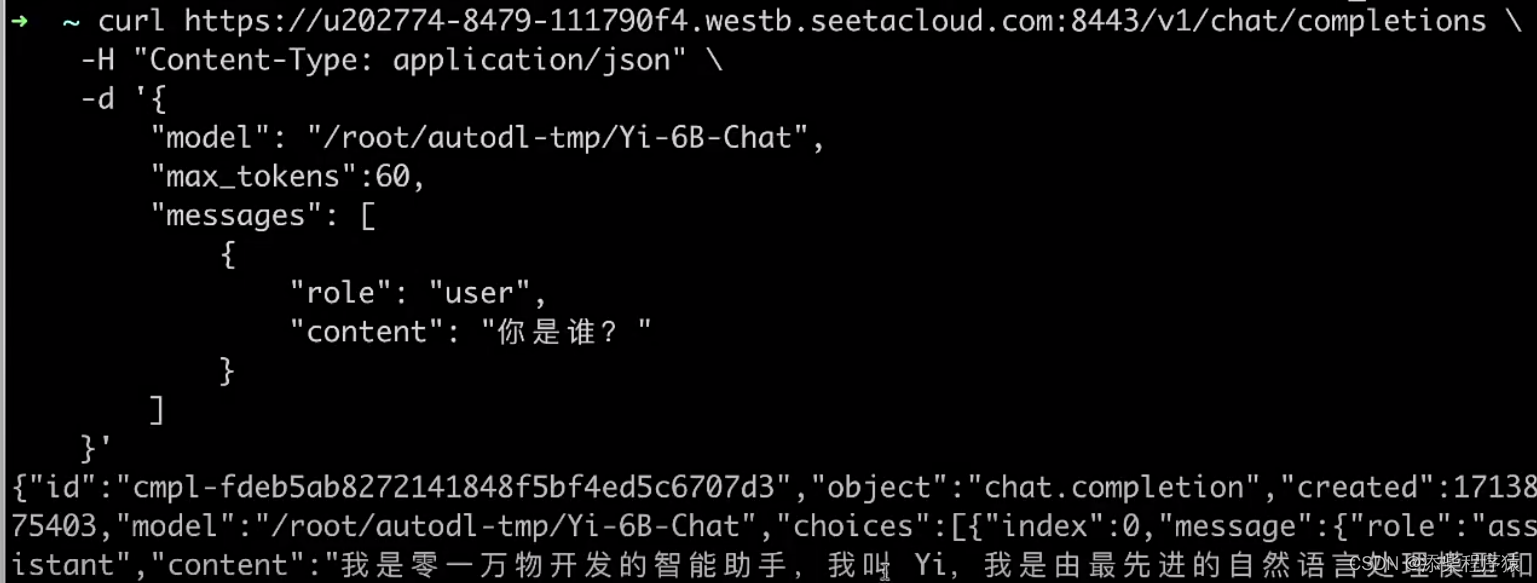
然后同时我们还可以在命令行中进行使用
#### 运行命令
```bash
python -m vllm.entrypoints.openai.api_server --model /root/autodl-tmp/Yi-6B-Chat --trust-remote-code --port 6006
```
```bash
curl https://u202774-8479-111790f4.westb.seetacloud.com:8443/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/root/autodl-tmp/Yi-6B-Chat",
"max_tokens":60,
"messages": [
{
"role": "us
 订阅专栏 解锁全文
订阅专栏 解锁全文



















 5414
5414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











