







 超级会员免费看
超级会员免费看
 本文介绍了轻量化微调的概念,包括Prompt Tuning、P-Tuning和Prefix-Tuning的原理。重点讲解了LoRA微调方法,它通过在Transformer模型的参数矩阵上叠加低秩矩阵来优化模型,尤其对Q和V矩阵进行叠加训练效果显著。此外,还探讨了低秩矩阵在数据压缩和处理中的应用。
本文介绍了轻量化微调的概念,包括Prompt Tuning、P-Tuning和Prefix-Tuning的原理。重点讲解了LoRA微调方法,它通过在Transformer模型的参数矩阵上叠加低秩矩阵来优化模型,尤其对Q和V矩阵进行叠加训练效果显著。此外,还探讨了低秩矩阵在数据压缩和处理中的应用。
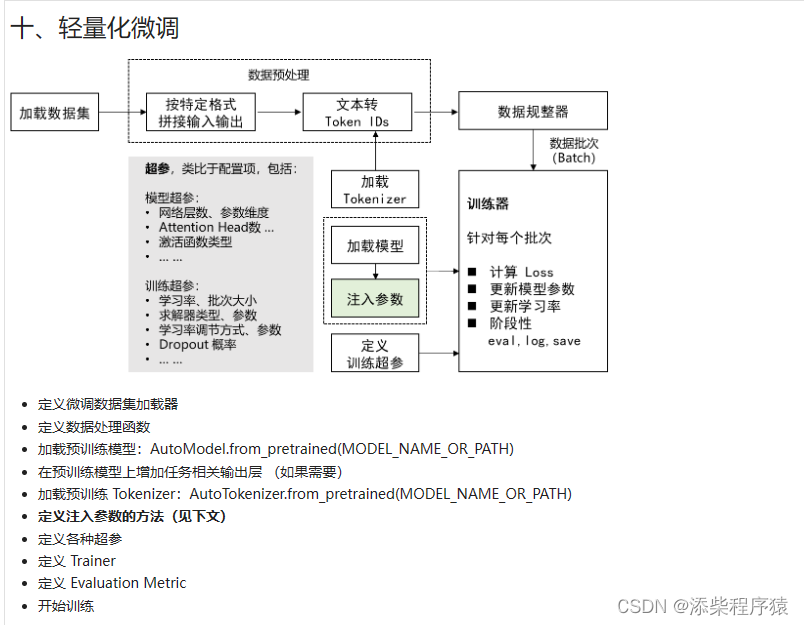
然后我们再来看一下,轻量化微调,这个过程,我们微调fine-tunning的过程很相似,
这里再说一遍:
1.首先加载我们的训练数据集,然后对数据进行处理,主要是对数据按特定的个数,拼接输入输出,训练数据主要包含,问题和答案,
2.然后把我们拼接好的训练数据,的文本转换成token ids, 注意 后面的数据规整器就是用来 对数据进行分批处理的,把数据按照batchsize进行划分
3.然后,再去加载tokenizer,对token进行序列化处理,然后,再去
4.加载模型 右边的部分就是训练器训练的过程
5.然后这里多了一块,就是注入参数,注意这里加载模型后,模型原来的参数都是冻结的,在训练过程中是不动的.
6.然后再定义和训练超参数.
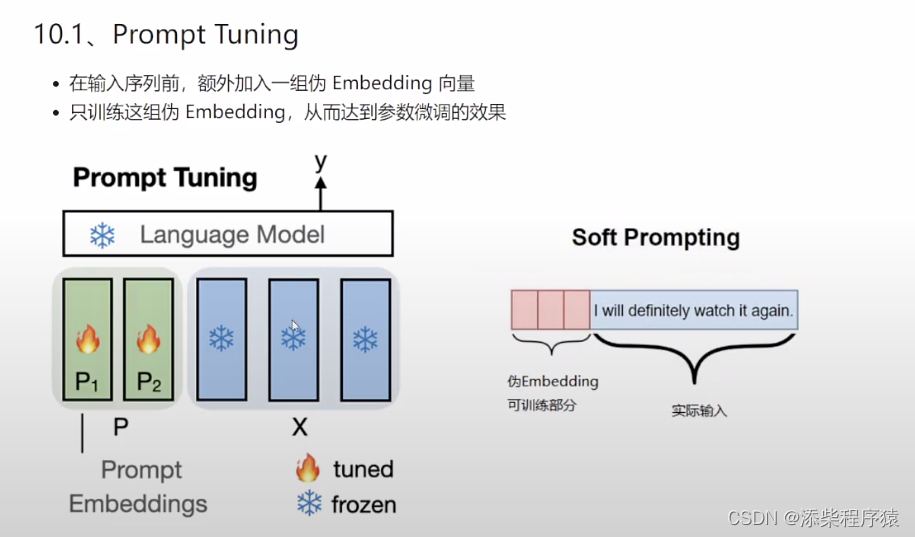
然后我们再来看一下这个Prompt Tuning,这个轻量化微调的原理,可以看到
其实就是在他就是在X部分,注意这个X不分,其实就是我们对大模型提问的语句,生成的词向量矩阵,然后,现在我们做的就是
在这个我们的提问句对应的词向量矩阵X的前面,添加了几个P1 P2

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











