







 超级会员免费看
超级会员免费看
 本文介绍了QLoRa模型量化技术,包括FP32、FP16和INT8的精度对比,以及如何将FP16数据压缩到INT8。QLoRA还引入NF4和双重量化等创新。此外,文章探讨了AdaLoRA的可训练矩阵秩调整,并以CrossWOZ数据集为例,展示了酒店领域数据的处理和增强,以及数据拼接在多轮对话模型ChatGLM2和ChatGLM3中的应用方式。
本文介绍了QLoRa模型量化技术,包括FP32、FP16和INT8的精度对比,以及如何将FP16数据压缩到INT8。QLoRA还引入NF4和双重量化等创新。此外,文章探讨了AdaLoRA的可训练矩阵秩调整,并以CrossWOZ数据集为例,展示了酒店领域数据的处理和增强,以及数据拼接在多轮对话模型ChatGLM2和ChatGLM3中的应用方式。
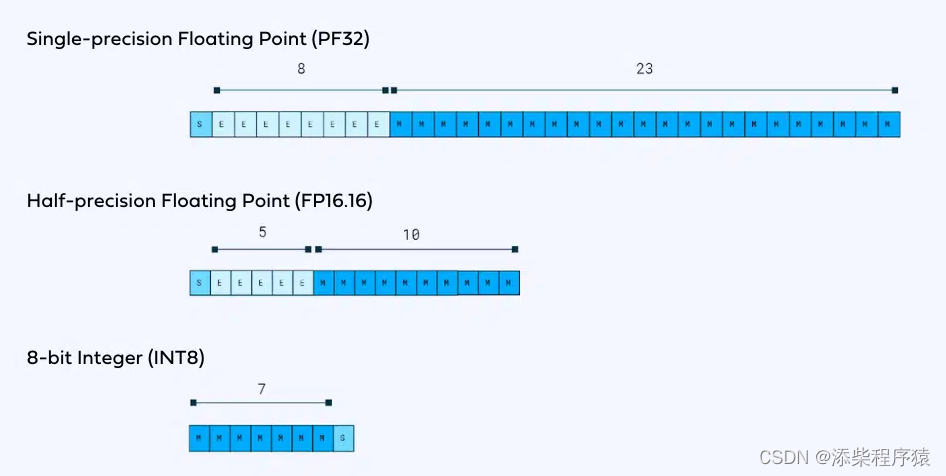
我们知道虽然lora,只需要添加跟原来模型一样的矩阵的方式,来进行轻量化微调,但是
现在的模型一般比较大,比如40层都很常见,就需要在40层的,每层前面添加这样一个矩阵,也会
占用很多的显存,因为需要加载模型数据到显存进行计算.
那么后来就有了QLoRa,其实就是对模型进行了量化.那么怎么量化的:
首先看:
1.PF32 单精度 是标准的模型:可以看到最头上s是,符号位,表示正负,然后中间8位,表示数量级,也就是一个数的,整数部分,然后后面的23,是精度,表示小数部分.
2.FP16 半精度:是16位,来表示,一个矩阵中的一个维度数据,同样前面第一位是,符号位,表示正负,然后中间部分5是数据的数量级,也就是一个数的,整数部分,后面10,这个表示精度是小数部分.
3.INT8 是4分之一精度了,这个的做法,就是,直接把16位的,数量级部分,也就是整数部分,直接丢掉,然后把后面的小数部分,转换成
用7位来表示的一个-127到128之间的一个整数来进行存储.然后后面最后一位是一个符号位.
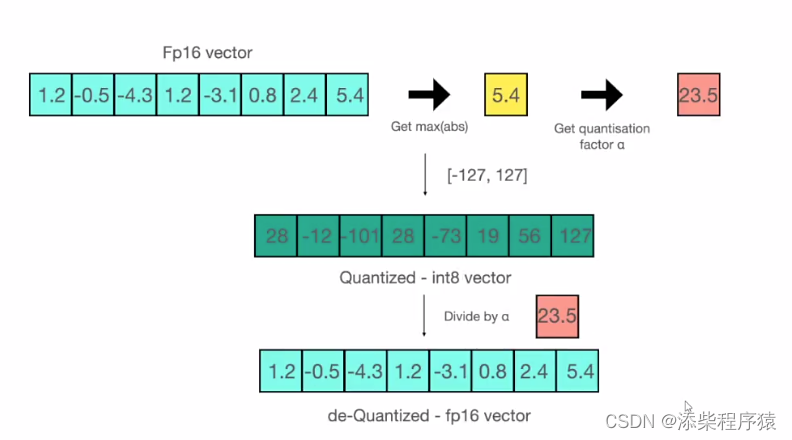
然后我们具体来看一下,如何把16位的FP1

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











