







 超级会员免费看
超级会员免费看
 本文详细解析了Transformer模型的预训练、微调和轻量化微调过程,重点介绍了预训练模型的构建、数据处理和模型训练。同时,深入探讨了Transformer的架构,特别是自注意力机制和LM Head在模型推理中的作用,为理解大模型如GPT-3.5的工作原理提供了清晰的阐述。
本文详细解析了Transformer模型的预训练、微调和轻量化微调过程,重点介绍了预训练模型的构建、数据处理和模型训练。同时,深入探讨了Transformer的架构,特别是自注意力机制和LM Head在模型推理中的作用,为理解大模型如GPT-3.5的工作原理提供了清晰的阐述。

然后我们来看一下,这几个的区别
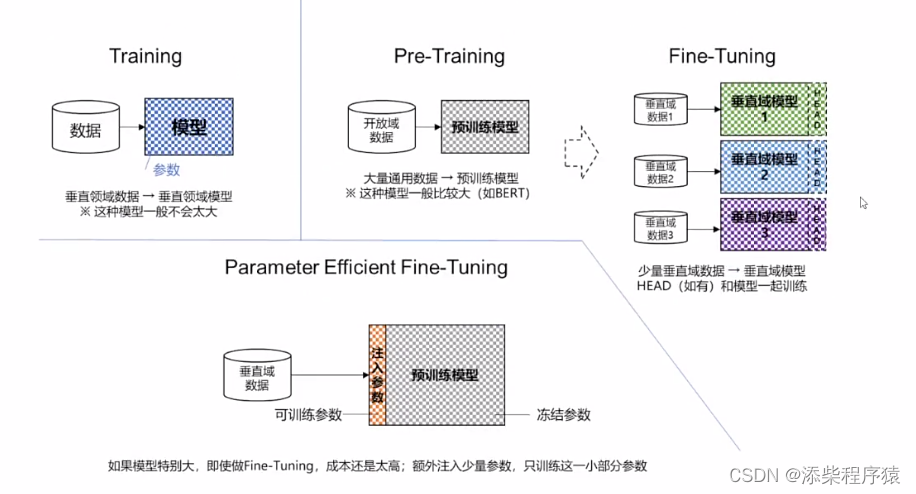
1.最开始的时候,模型是用在垂直领域的,其实就是用在某个业务上的,用来解决,单一的算法,或者业务问题,
这个时候模型不是太大,左上角那个training,数据量没那么多.
2.然后在bert时期,开始就发现,如果在专业领域,我需要构建非常多的专业的知识,需要很多比如语言学专家等,收集专业数据太难了
所以就开始收集了很多通用数据,把比较大的语料,比如电子辞典等等,全都给模型训练,得到一个基础的模型,发现还不错.这个时候
模型就开始大了,大力出奇迹了.这个是Pre Training
3.然后再来看Fine-Tuning,这个是微调,表示在预训练的模型基础上,也就是拿了很多语料训练出来的模型基础上,然后再拿一些,垂直领域的知识,也就是某些专业领域的知识,拿过来,然后,叫做添加一个HEAD层,和原来的模型,放到一起,进行训练,这样相当于调整了原来的参数,并且添加了一些参数.这个训练过程也很慢,消耗很大.
4.后来就出现了parameter efficient fine-tuning叫做轻量化微调,就是我先冻结原来的

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











