







 超级会员免费看
超级会员免费看
 本文详细解析了Hadoop3.x中MapTask的源码,通过一个实例展示了数据如何经过MapTask处理,进入环形缓冲区,并通过分区、序列化、溢写和归并排序的过程,最终准备供ReduceTask使用。文中还强调了数据在不同机器间传输需序列化的原因,以及MapTask执行的完整流程。
本文详细解析了Hadoop3.x中MapTask的源码,通过一个实例展示了数据如何经过MapTask处理,进入环形缓冲区,并通过分区、序列化、溢写和归并排序的过程,最终准备供ReduceTask使用。文中还强调了数据在不同机器间传输需序列化的原因,以及MapTask执行的完整流程。

然后我们来看一下maptask的源码,这个对理解maptask如何工作很重要
我们在一个例子的基础上去debug,去看,可以看到,我们用
partitioner2这个案例,这个是我们之前,用来区分,把136开头的手机号,放到一个文件中,把137的放到一个文件中,
....139放到一个分区文件中,其他的放到另一个文件中的那个案例.
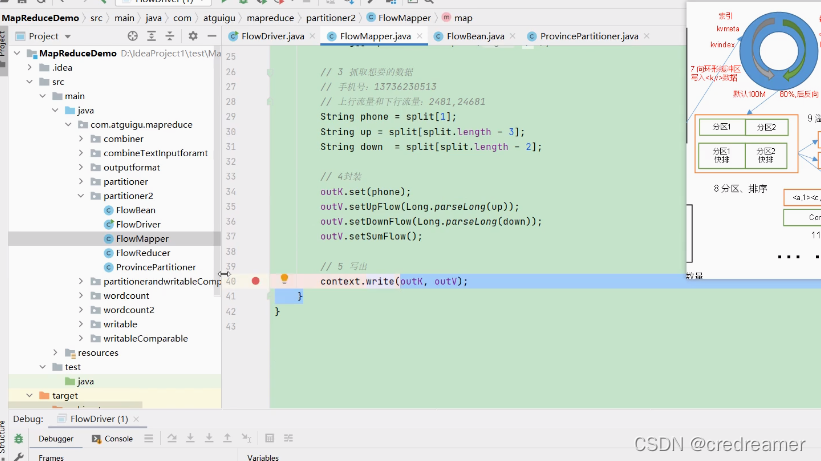
然后我们在FlowMapper中的context.write这里打个断点
然后
然后我们来看一下maptask的源码,这个对理解maptask如何工作很重要
我们在一个例子的基础上去debug,去看,可以看到,我们用
partitioner2这个案例,这个是我们之前,用来区分,把136开头的手机号,放到一个文件中,把137的放到一个文件中,
....139放到一个分区文件中,其他的放到另一个文件中的那个案例.
然后我们在FlowMapper中的context.write这里打个断点
然后

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


























